自作ハーネス familiar の検証: クラウドエージェント orchestrator と Qwen3-Coder-Next 80B / GLM-5.1 による実地観測
familiar の orchestrator / naughty / grandpa 構成を、Claude orchestrator、Qwen3-Coder-Next 80B IQ4_KSS、GLM-5.1 smol-IQ4_K で実地検証した記録。6ページ生成失敗の切り分け、Grafana/DB/DCGM による観測、V2 system prompt 動的構成と output_file モード導入までをまとめる。

familiar の実験を「動いた」「動かなかった」で終わらせず、どこで詰まり、何を変えると挙動が変わるのかまで見える状態にしたかった。familiar 自体は orchestrator を claude | codex | gemini | ローカル LLM に切り替えられるが、今回の検証では Claude を orchestrator として使い、naughty に Qwen3-Coder-Next 80B IQ4_KSS、grandpa に GLM-5.1 smol-IQ4_K を載せた構成で、実際のサイト生成とレビューを流しながら切り分けを行った。
結論から言うと、最初に見えていた「worker backend unavailable」は backend 障害そのものではなかった。真因は、orchestrator が大きい仕様を単一 worker call に丸ごと押し込み、GPUTimeout=300s を踏み抜くプランを組んでいたことにあった。そこを見つけるために、workspace、chat_history、Grafana の session flow、DCGM GPU monitoring を同時に見る必要があった。
検証構成
今回の実験で見たかったのは 3 点だった。
- orchestrator が大きい仕様を contract-first に分解できるか
naughtyとgrandpaの役割分担が観測可能な形で残るか- 失敗時に「モデルの問題」ではなく「プランの問題」と言い切れるだけの証拠が揃うか
実運用スタックとしては translator も含めて構成されているが、今回の検証対象は orchestrator / grandpa / naughty の 3 ロールに絞っている。以前使っていた kindergarten 構成は廃止した。
ロール構成は次のとおり。
| Role | 主な役割 | モデル |
|---|---|---|
| orchestrator | ターン制御、worker call 計画、依存関係整理 | Claude orchestrator |
| naughty | HTML 生成、単一ファイルの直接生成 | Qwen3-Coder-Next 80B IQ4_KSS x 2 instance |
| grandpa | 部分レビュー、検証、ファイル読解ベースの確認 | GLM-5.1 smol-IQ4_K |
| translator | 翻訳 | Plamo-2-translate bf16 |
Plamo-2-translate はライセンス都合があるため、そのまま長期運用するつもりはない。現在は llm-jp/llm-jp-4-32b-a3b-base を翻訳用途に LoRA 化し、さらに nvfp4 化して置き換える作業を進めている。
対象タスクは歯科クリニックの 6 ページ静的サイト生成だった。index.html、services.html、doctors.html、info.html、visit.html、access.html を持ち、共通ヘッダとフッタ、料金表、モーダル、README まで揃える要件を流した。
失敗の最初の形
最初の観測はこれだった。
Status: worker execution failed after one recovery attempt.
Initial error: worker call w1 failed: worker backend unavailable
(alias=naughty backend=vllm model=naughty): knowledge gate: llm backend unavailable:
request vllm: Post "http://compute.home.arpa:8001/v1/chat/completions":
context deadline exceeded (Client.Timeout exceeded while awaiting headers)
この文面だけを見ると、naughty が落ちているように見える。実際、自分も最初は backend の容量問題や疎通を疑った。ただ、ここで backend の生死だけを見ても本質には届かなかった。
workspace を開くと、orchestrator は 6 ページ全体を 1 つの worker call に丸ごと押し込む方向で考えていた。しかも naughty の並列度情報自体は workspace に届いていた。つまり「分解できる情報はあるのに、分解の仕方を system prompt が教えていない」状態だった。
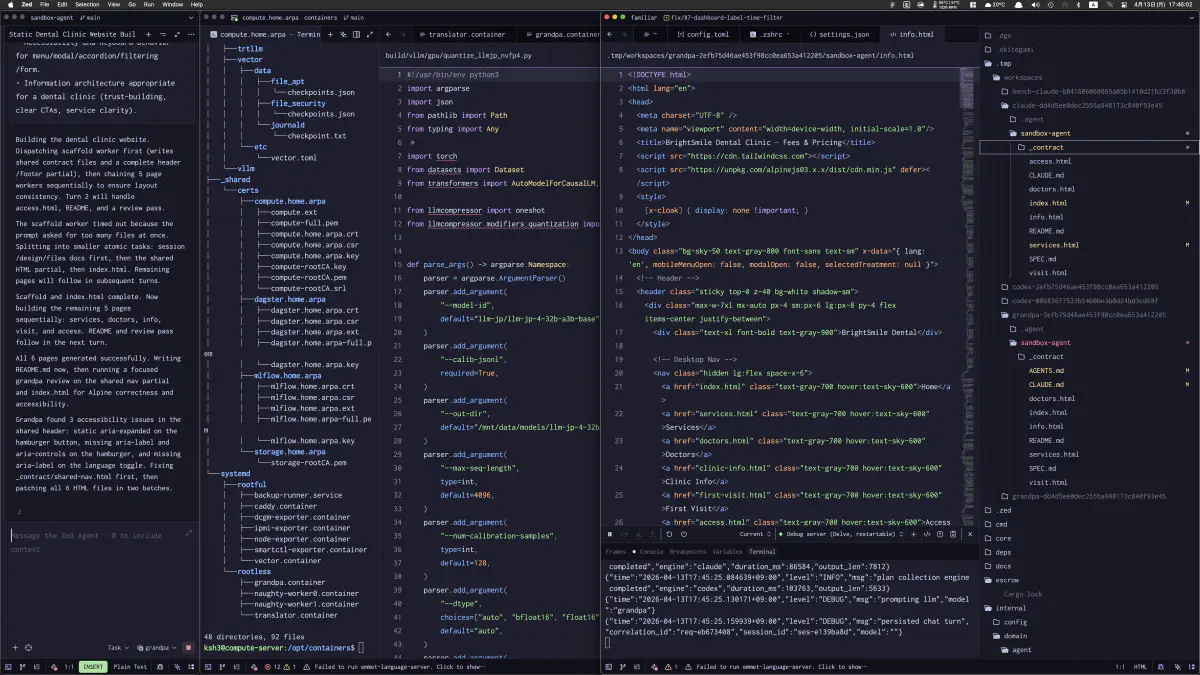
実際にはどこまで動いていたか
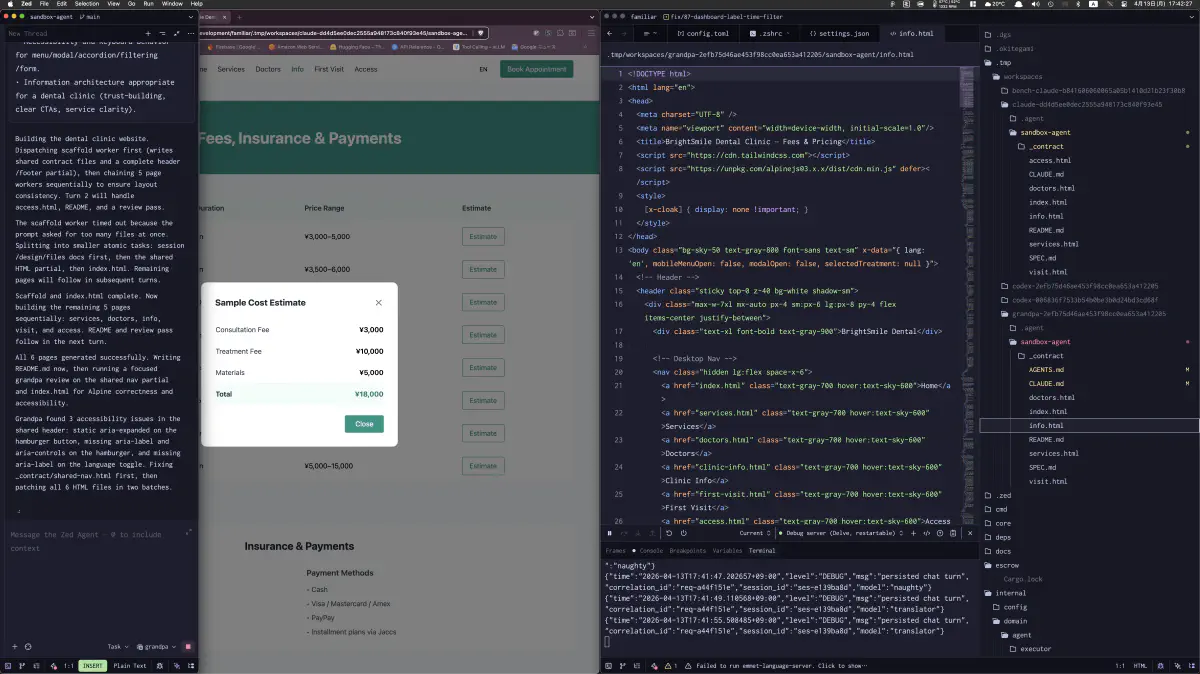
失敗扱いになっていても、生成そのものは途中まで進んでいた。料金表モーダル付きのページが実際に描画され、info.html 側にも対応する HTML が存在している。ここで重要なのは、「壊れていた」のではなく「終わり切らなかった」ことを画面とファイルで確認できた点だった。
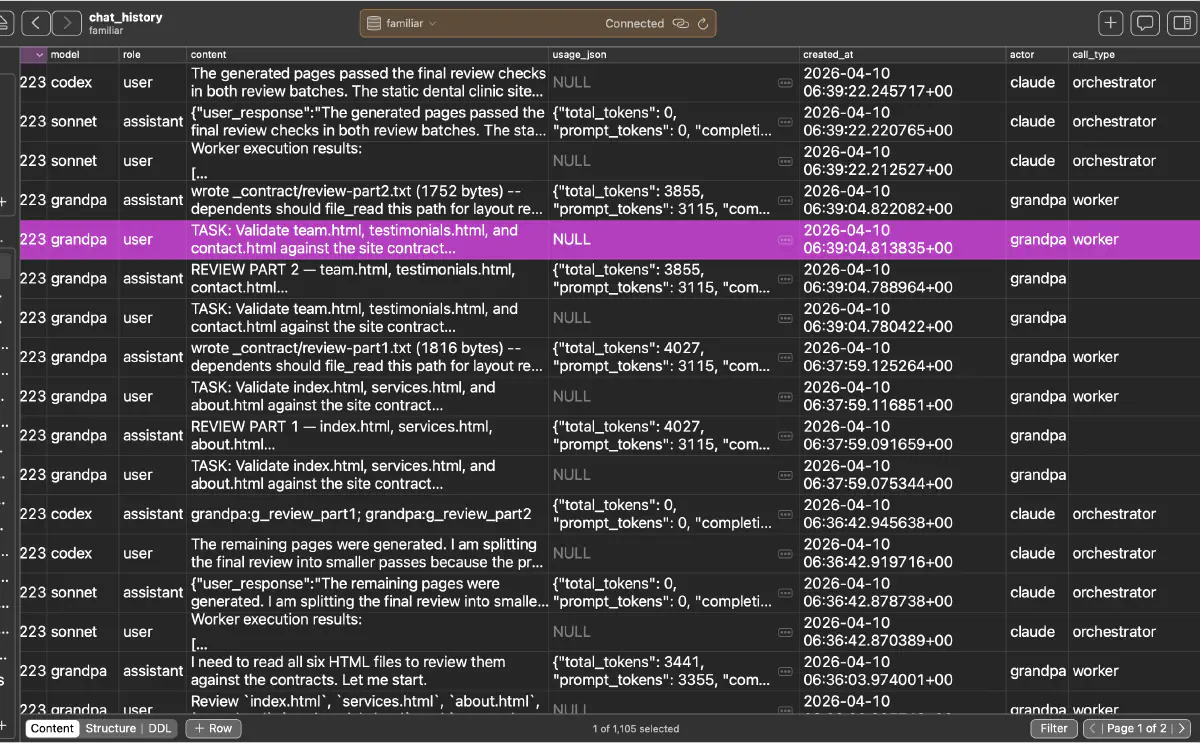
さらに chat_history を見ると、orchestrator、grandpa、その他ワーカーの発話と usage がターン単位で残っている。レビューを 2 分割して走らせていた痕跡や、worker ごとに usage JSON が入っていることも確認できた。
何を見て切り分けたか
今回の検証で効いたのは、1 つのログだけを信用しないことだった。最低でも 4 面で見ないと、原因の層を間違える。
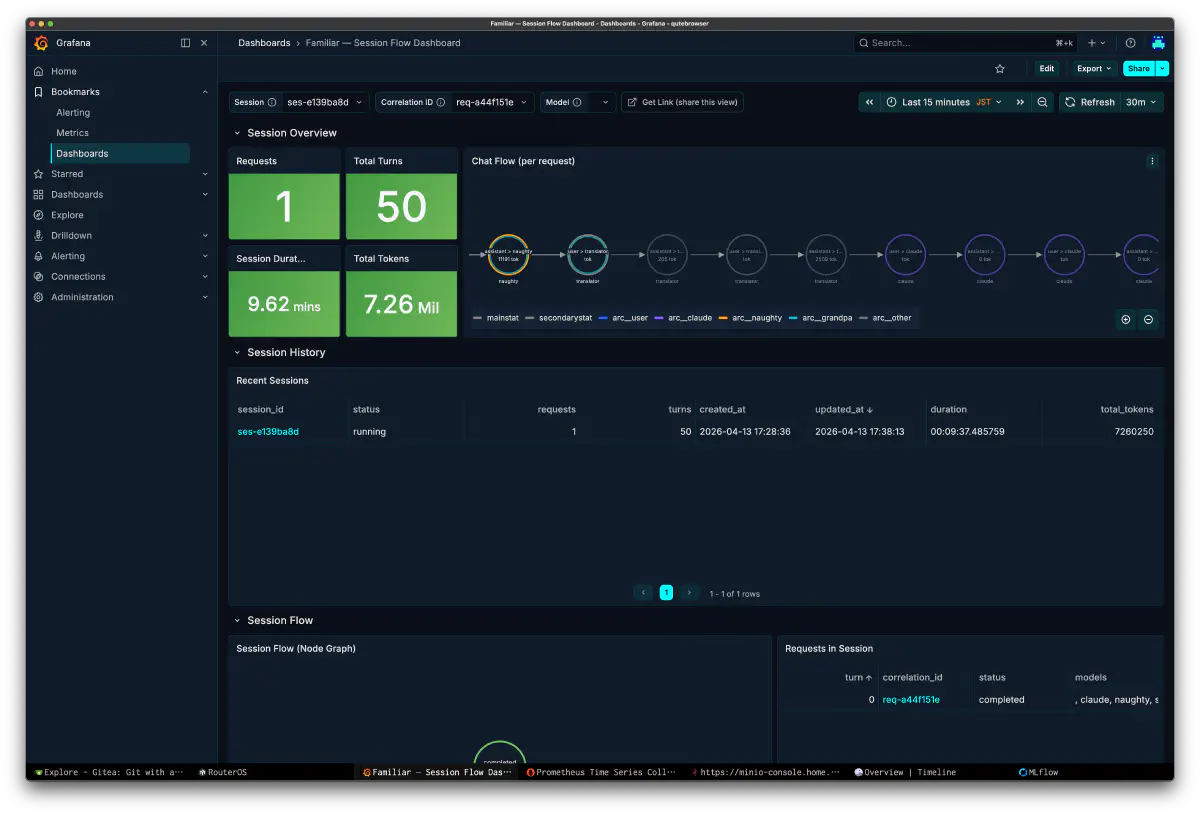
まず Grafana の session flow では、1 リクエスト 50 ターン前後の重い実行が数分単位で続いていたことが見える。ここで一度 7.26M tokens と読んでしまったが、これはクエリ条件を間違えていた時の表示だった。あとで見直して修正したところ、実際のトークン量はおよそ 442k だった。chat flow には naughty、grandpa、claude の役割が色分けされていて、どのロールが長く引っ張ったのかをその場で追える。
Vector 側の session flow graph は、より低レベルなノードとエッジを見せてくれる。plan ノードから worker ノードにどう枝分かれしたか、running と queued がどう遷移したかを raw telemetry で追えるので、「orchestrator の考えた DAG がそもそも悪いのか」を見るのに向いていた。
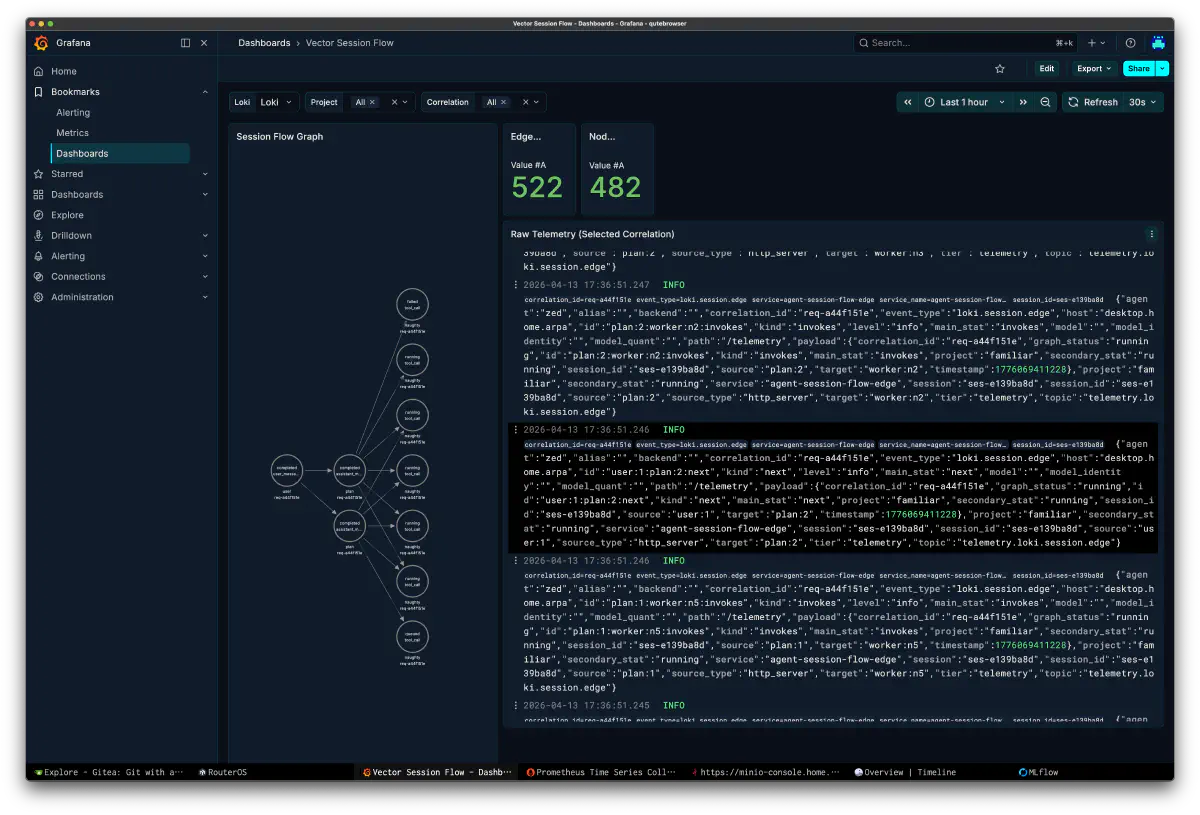
GPU 側では DCGM を見る。ここで両 GPU がしっかり動いているなら、問題は「GPU が遊んでいた」ではなく「やらせ方」にあると判断できる。今回も utilization と FB usage は十分に乗っていて、backend が完全停止していたわけではないと分かった。
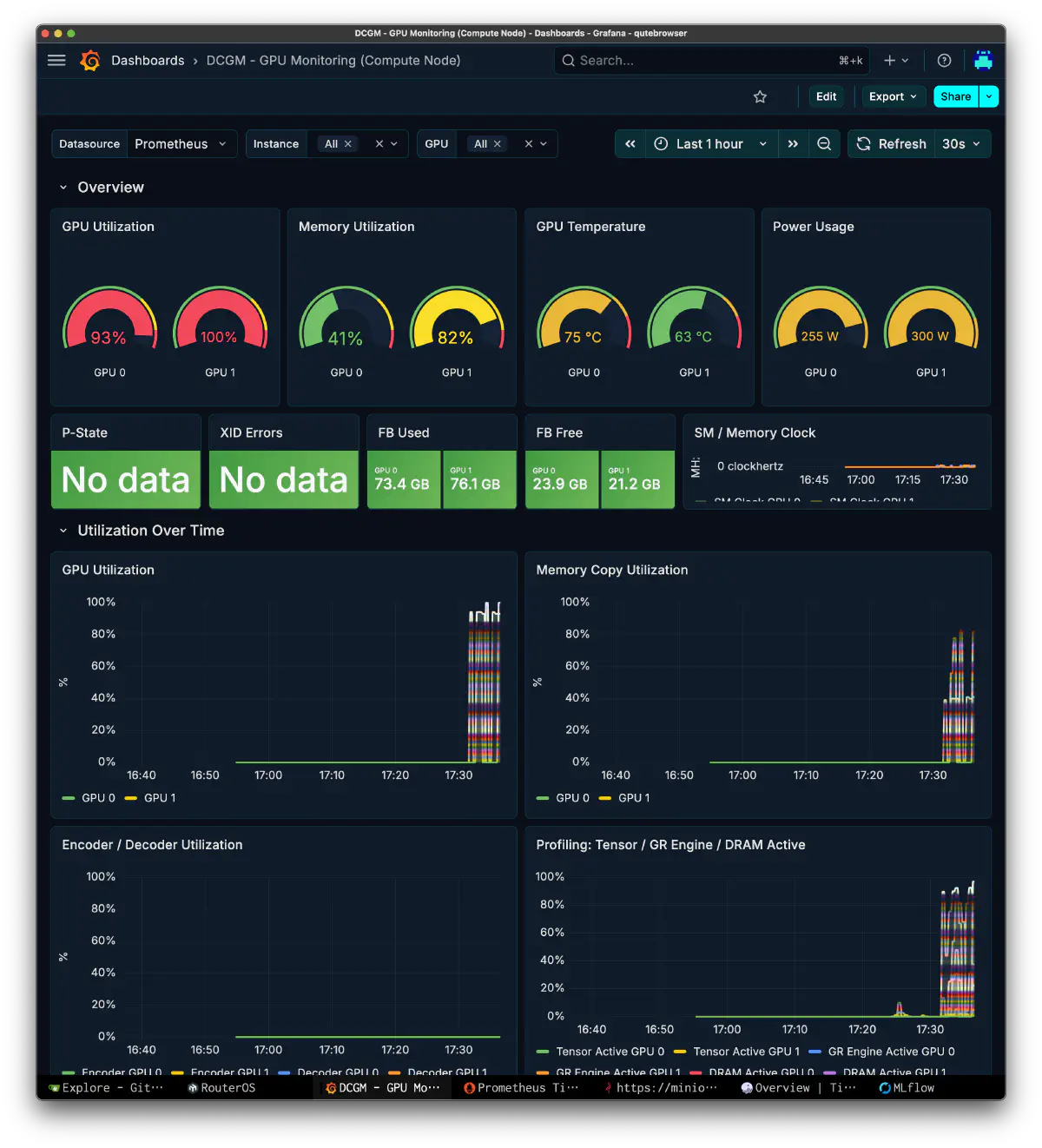
根本原因
最終的に root cause chain はこう整理できた。
- orchestrator は V1 相当の system prompt で動いていた
- そこには contract-first parallel design の具体例が足りなかった
- 6 ページ要件を 1 回の大きい worker call に押し込んだ
naughtyが 300 秒以内に完了できずGPUTimeoutに到達した- recovery も同じ plan をなぞるので失敗した
本来欲しかった worker_calls は、次のような形だった。
{
"continue": true,
"worker_calls": [
{
"id": "n1",
"alias": "naughty",
"prompt": "Create the shared structure and landing page first.",
"depends_on": [],
"output_file": "index.html"
},
{
"id": "g1",
"alias": "grandpa",
"prompt": "Review the shared contract and validate accessibility risks.",
"depends_on": ["n1"]
},
{
"id": "n2",
"alias": "naughty",
"prompt": "Create services.html using the shared header/footer.",
"depends_on": ["n1"],
"output_file": "services.html"
}
]
}
骨格を先に作り、その contract を基準に後続ページを分割し、grandpa はレビューと検証に寄せる。この構造にしない限り、モデルを差し替えても同じ種類の詰まり方を繰り返す。
何を直したか
修正は 3 本柱だった。
1. system prompt を worker pool 構成から動的生成する
BuildOrchestratorSystemPrompt(pool) の形に倒し、naughty、grandpa、translator の有効/無効に応じて、含めるべき role 説明と分解パターンを切り替えるようにした。静的ファイル 1 枚では、運用構成の差分に追随できなかったためだ。加えて、最終合成と部分合成のバージョニングを保持し、その差分と採用結果を観測できるようにもした。単に prompt を切り替えるだけではなく、「どの合成結果がどのターンで使われたか」を追えることが、あとから振る舞いを説明するうえで重要だった。
2. output_file モードを導入する
単一ファイル生成に ReAct ループを回すのは遅すぎる。worker が tool 呼び出しを何度も往復する代わりに、raw text をそのまま指定パスへ書く output_file モードを足した。これで HTML 1 ファイル生成は「1 回の LLM 呼び出しで終える」経路に逃がせる。
ただ、これは --seq=2、--parallel 2 程度の軽い並列なら、そこまで神経質にならなくても回るかもしれない。自分の構成では Qwen3-Coder-Next 80B IQ4_KSS を 2 instance の backend として使っているので、1 つのゴールに対して共有してよいものと、干渉を避けるべきものを明確に分ける仕組みが必要だった。そこを曖昧にすると、同じゴールに向かった 2 worker が不要に同じファイルへ触ったり、逆に共有すべき contract を持てずにばらけたりする。
今はこの問題に対して MCP ツールを追加し、共有と干渉回避の両方を越えられるようにしている。output_file はその前段の最適化として効いたが、最終的には backend を複数 instance で安定運用するための境界制御まで含めて考える必要があった。
3. orchestra.log に追跡情報を集約する
orchestrator の system prompt、worker prompt、worker content、tool_call と tool_result、duration_ms を 1 つのログで追えるようにした。複雑なセッションでは、あとから「なぜこの worker call が出たのか」を読めないと再発防止ができない。
検証結果
今回の検証で得た判断は次のとおり。
- 問題の中心は model quality そのものではなく、orchestrator の分解戦略と message stack の扱いだった
naughty=Qwen3-Coder-Next 80B IQ4_KSS x 2 instanceは単一ファイル生成器として使う方が筋がよいgrandpa=GLM-5.1 smol-IQ4_Kは全体生成よりレビュー・検証・分割された確認に寄せた方が安定する- 可観測性は補助機能ではなく、設計の正しさを判断する主系統だった
特に大きかったのは、session flow と DB で「どういう plan が組まれたか」と「実際にどのロールが何を返したか」を分けて見られるようになったことだ。backend が遅いのか、prompt が悪いのか、ターン設計が悪いのかを、同じ画面上の impression で済ませずに証拠として残せるようになった。
ここで強調したいのは、問題の核心がマルチモデルのオーケストレーション、いわゆるハーネス側にあるという点だ。一定レベルを超えたモデル同士では、単体能力の差だけで劇的な違いが出ることは少ない。むしろ効いてくるのは、指示の連鎖をどう積み上げるか、messages[N] のスタック操作を安定的に扱えるか、そして途中成果物をどう次のターンに橋渡しするかだった。
開発を始めてから約 1 か月で、ローカル LLM 専用と汎用の Rust ベース MCP ツールを、廃止したものも含めて 20 近く並行開発してきた。多くは「いかに ctx の無駄を減らすか」に注力した結果で、そのうちいくつかは目に見えて効いた。直近で minimax-m2.7 を検証した時と比べても、one-shot のサイト生成で必要なコンテキストは 150k から 55k 付近まで圧縮できている。
優先順位も明確で、今は SFT や DPO の自動収集より先に、「その過程を Grafana と DB で追えること」を重く見ている。生成が失敗した時に学習データが増えることより、なぜ失敗したかを turn 単位で説明できることの方が、いまの段階では価値が高い。
今後の論点
次の論点は「どのモデルを選ぶか」より「どのハーネスだと安定して回るか」に寄っている。orchestrator の切り替え、worker の責務分離、message stack の圧縮、観測データの残し方を 1 つずつ詰めていけば、モデル個別のベンチ結果より再利用価値の高い基盤になる。
今回の段階で少なくとも「モデルを替えれば直る」という話ではないところまでは整理できた。familiar の実験を前に進めるには、まず orchestrator が安全に小さく分解し、その過程を Grafana と DB で追えること。この土台ができたことで、次の比較実験はようやく意味を持つ状態になった。