familiar - ローカルLLMだけで動くマルチエージェント開発基盤を作った話
クラウドAPIに依存せず、自宅サーバーのローカルLLMだけで計画、実装、テスト、レビューを自律実行する familiar を作るまでの発端と初期設計の記録。

はじめに
2月から3ヶ月かけて、自宅サーバーのローカルLLMだけで動く、データスタックと連携したマルチエージェント開発基盤を作っていた。名前は familiar。家族でもあり、使い魔でもある、インスピレーションから付けた名前だ。処理の中でみんなが楽しくやってくれたらいいなと思って。内部の alias にはフクロウの grandpa、子猫の frisky、子狐の naughty を与えた。
55分のデモ走行を録画して YouTube に上げた。
動画リンク: https://www.youtube.com/watch?v=tSAguJzTINs
Django製の飲食店予約システムを、人間の介入ゼロで計画、実装、テスト、レビューまで自律実行する。33コミット、約11Mトークン消費、最終的に13テスト全パスで全レビューアー approved まで到達した。
Django だけではない。React はよく学習されているので、軽くかけた限りでは問題なく動いた。他にも Tauri、Flutter、Hugo など、自分が好きなもの、仕事で使うものは一通り揃えた。開発だけでなく、企画(Strategist)、投資(Analyst)、PR(Spokesman)という X-Role Header 用の内部変数も作り、オーケストレーションモデル自体をプラグイン、切り替えできる形にした。ワーカー側も、必要な才能をいくらでも拡張し、プラグインできる設計にした。
この記事は、ローカルLLMとデータ基盤の開発経緯、そして実装しながら見えてきた設計判断の振り返りだ。
familiar とは何なのか
familiar は、複数の任意のローカルLLMを協調させて、作業そのものを小さな単位に分解し、実行、やり直し、統合、完了までを行う実行基盤だ。 実行と合わせて、観測基盤、学習パイプラインも密結合させたオンプレ向けのマルチエージェントだ。
人間の作業は、今は最初の要求と最後の確認。最終的には systemctl start familiar.service によるサービス起動だけにする。オーケストレーターが決裁、計画を行い、労働者へ割り当て、結果判断を行い、労働者は計画の実施、テスト、レビュー、視覚的デザイン、場合によっては統合を受け持つ。実行基盤はそれぞれのコミュニケーションプロトコルを設計し、依頼として扱い、完了報告、確認材料、成果物、レビュー判定を保存する。
開発記録を見返すと、familiar の開発中心は「モデル最適化」、「完全なruntime制御」ではなく、「ローカルLLMが苦手なところを実行基盤と道具で補う」ことだった。 そして完璧を求めるのではなく、どうやって生き残るか、生存性を主題においた。
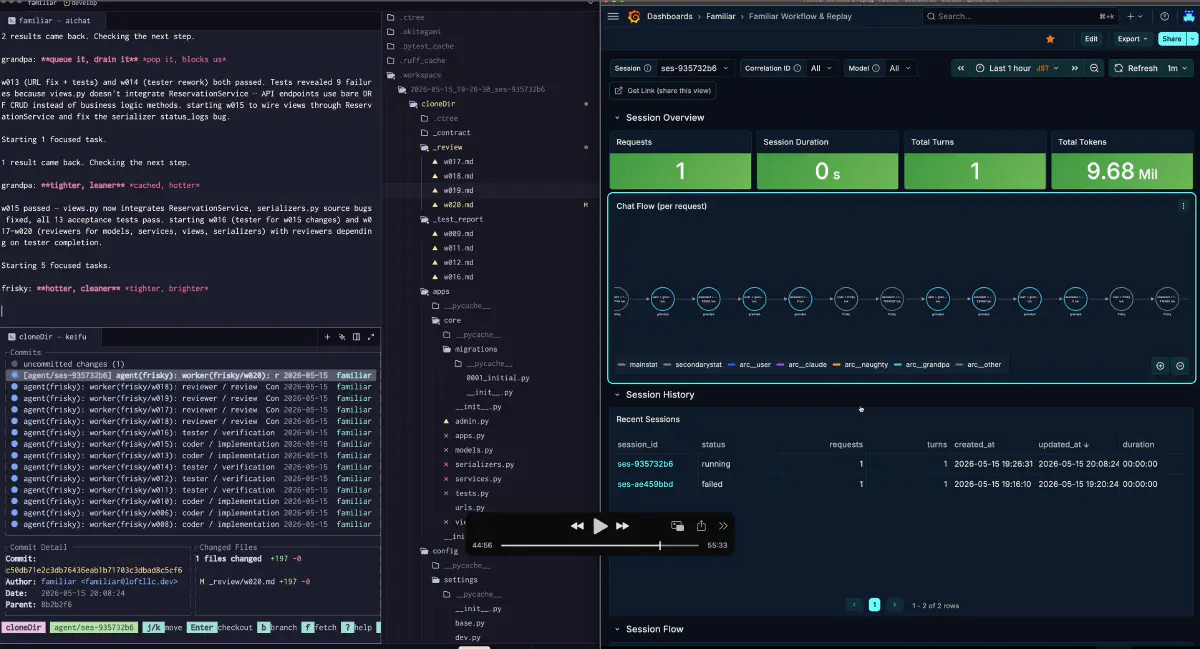
実行基盤の核は、オーケストレーターの判断と担当役の結果を同じ時系列で見られることにある。どの担当役が通ったのか、どこで失敗したのか、どの前提関係が詰まったのか、どのやり直しが効いたのか。この結果の因果はなにか。再現するか。これが見えないと、指示文を直したのか、作業順序を直したのか、道具を直したのか判断できない。
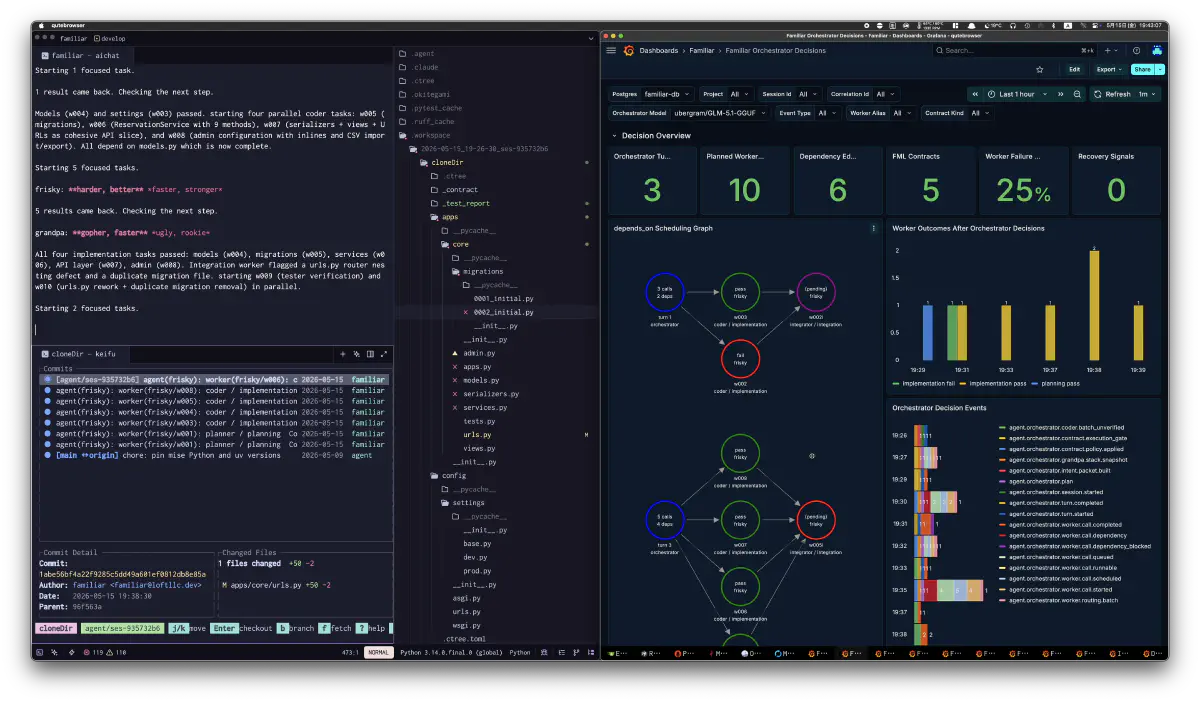
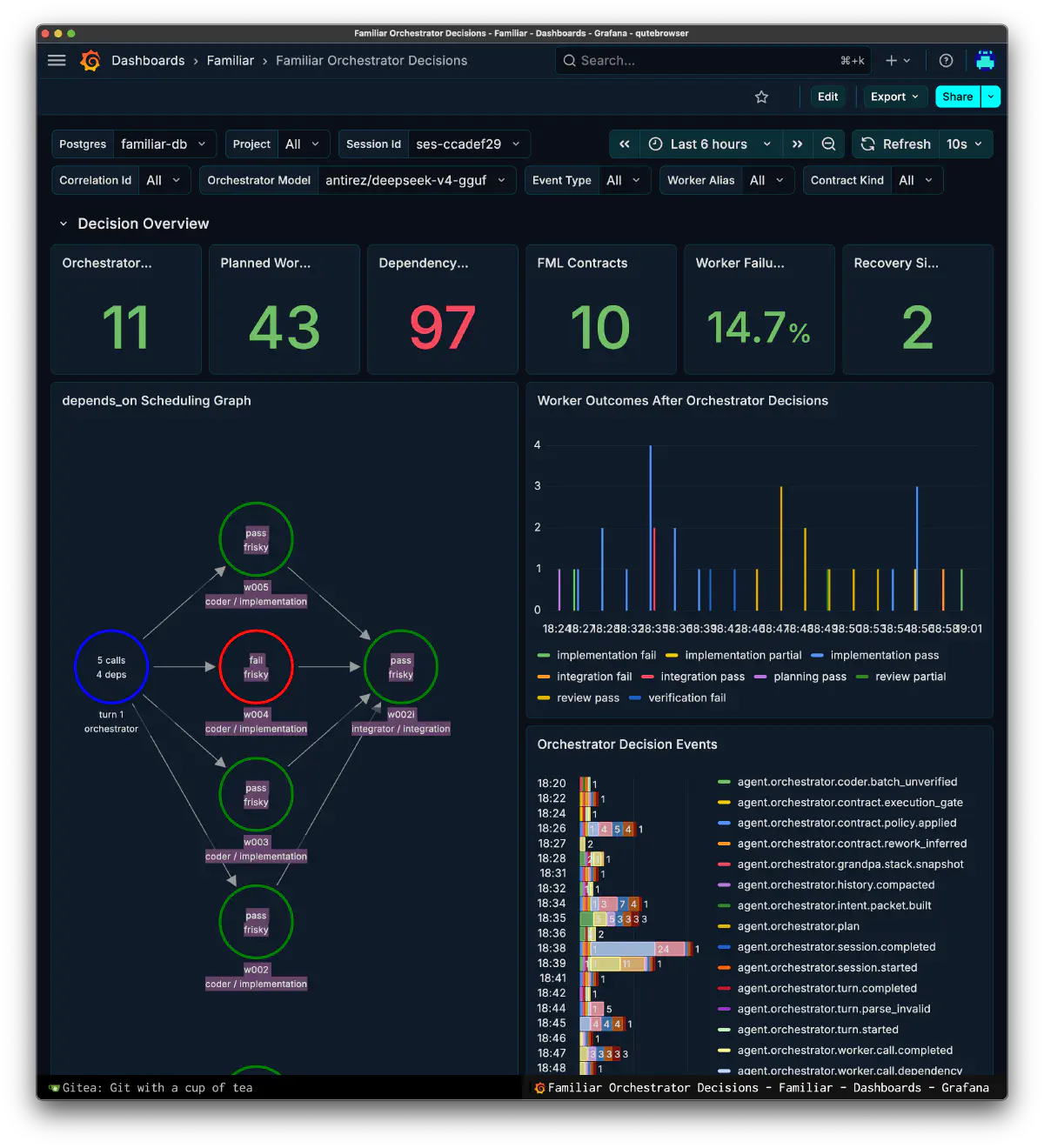
今となってはモデルは開発費用や、データの権利によって現実的でない。これからより良いものがOSSから提供されるかもわからない。なのでライセンスがクリアなものはすべてアーカイブとして集めた。grandpa は GLM-5.1、 Kimi-K2.5、DeepSeek V4 Flash のような一定以上のパラメーターを持つモデル候補なら代替可能だ。これはOSSで提供されたら開発しなくとも最新の学習情報を持ったものに置き換え、積み上げたデータセットから経験は補えるからだ。現状はもっとも安定しているのはライセンス、動作、諸々を勘案して、オーケストレーターはGLM-5.1、労働者側はQwen3.6, gemma4などのMTP対応が進んでいるもので、速くて実装に強いモデルを置いている。開発中、2月〜4月はOSSモデルが豊作だったのも運が良かった。
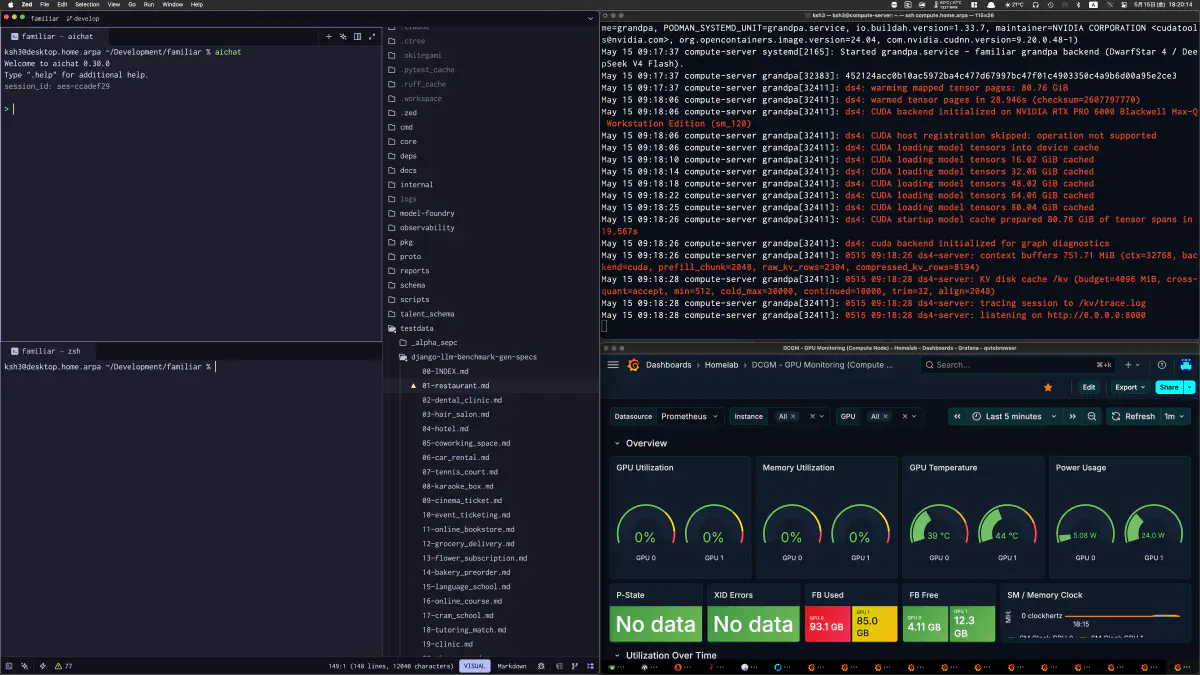
観測面は、最初に考えていたよりずっと大きくなった。開発記録には、Grafana の Familiar folder をバックアップして 54世代の dashboard を同期した記録も残っていた。Orchestrator Decisions、Workflow & Replay、MOLsEV、C&F Latency、Arch Stats、Tool Calls、Guard Calls、LoRA/Prompt ROI、Model/Quant Failure Heatmap など、runtime実装に合わせて、見方そのものが増えていった。
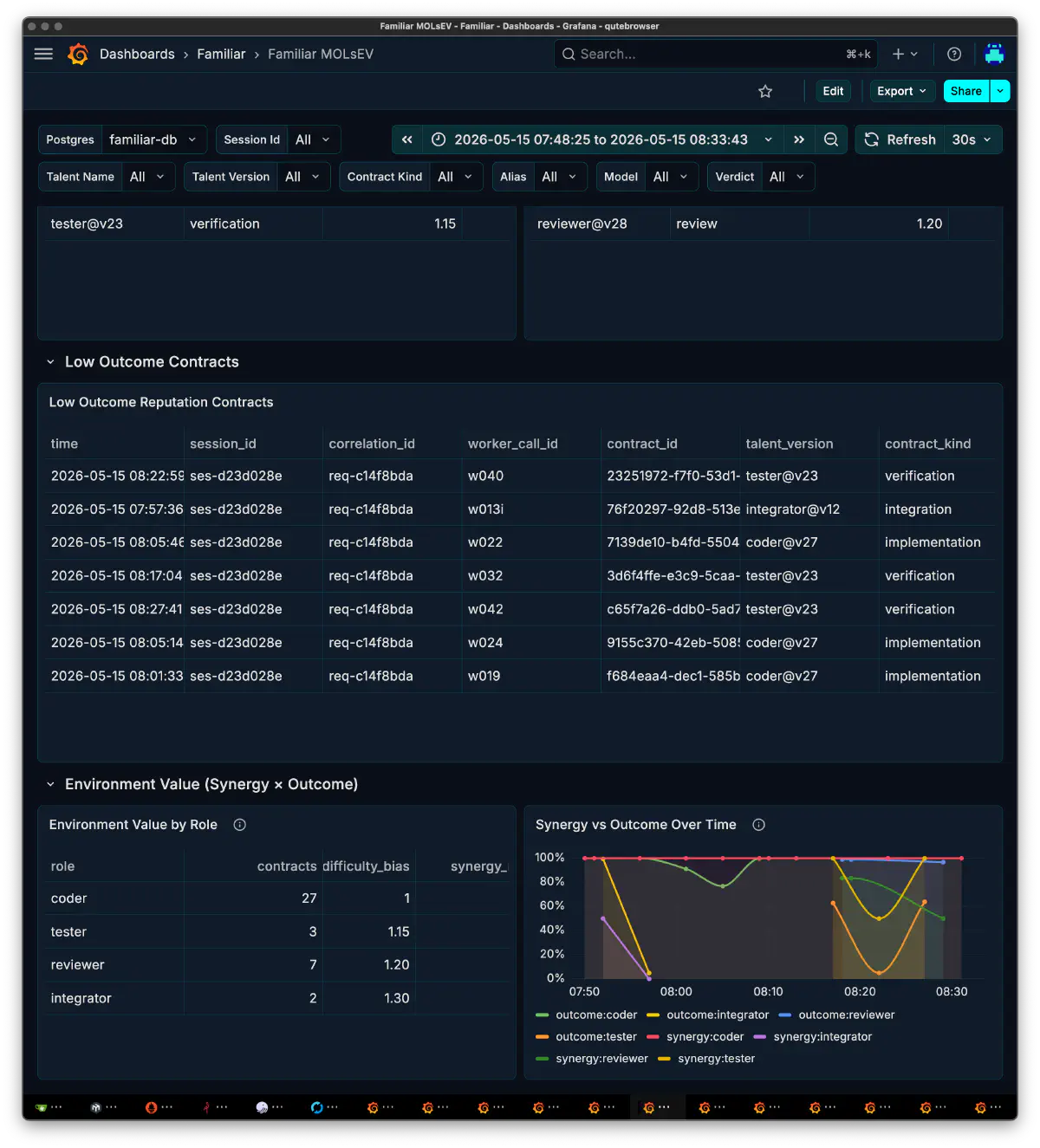
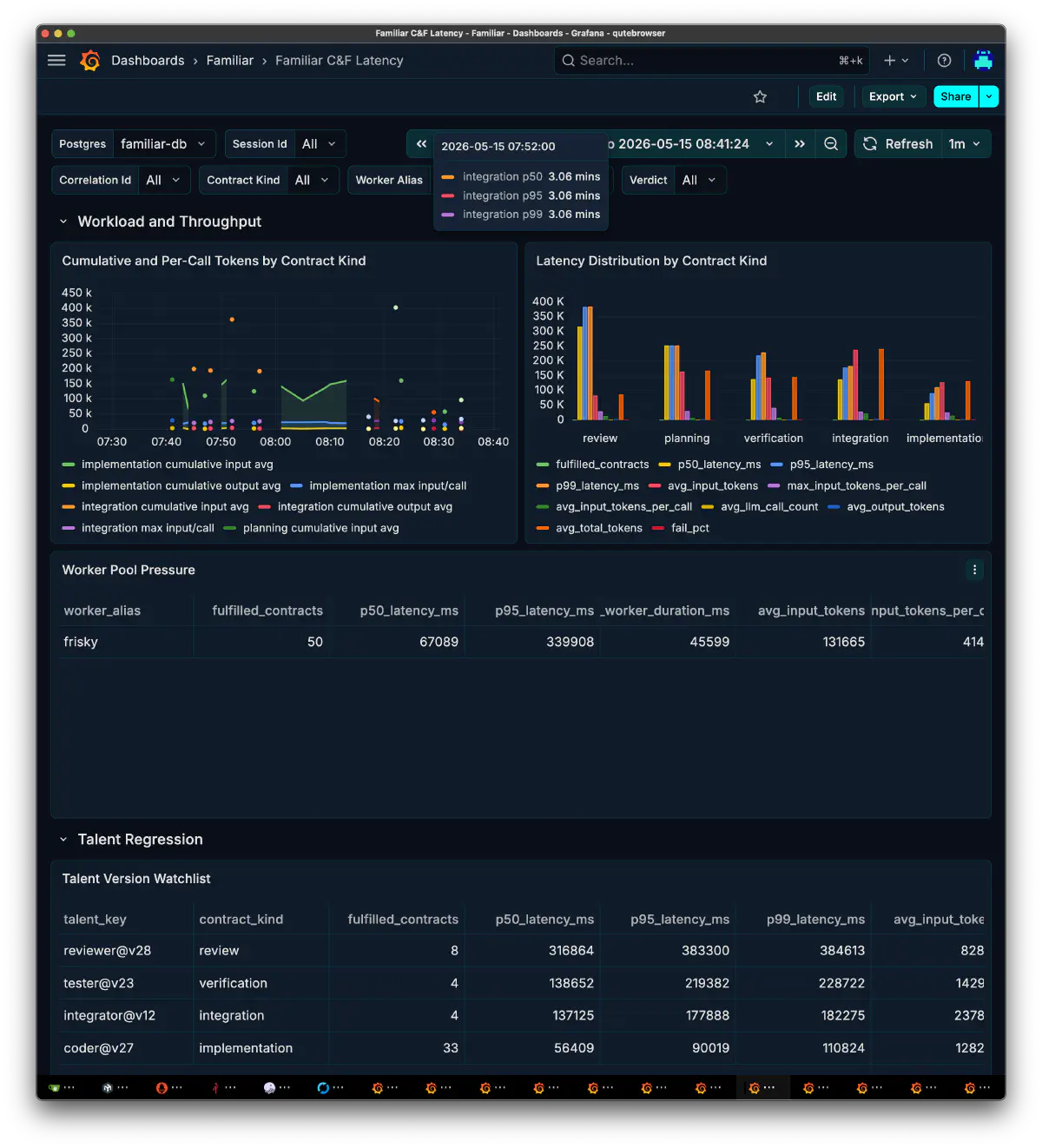
色々試してわかったのはマルチエージェントは prompt, モデルの優劣だけでは成立しないということだった。なんというか、OSSの力を借りて総力戦といったイメージである。
発端は Qwen Next だった
発端は去年7月頃に Qwen Next を試したことだった。
そのとき、「これはもうすぐ CPU 推論にシフトしていくな」とかなり強く感じた。GPU が不要になるという意味ではない。MoEによる推論コストの最適化、長いコンテキスト、複数モデルの同時運用を考えると、GPU だけで全部を抱えるより、CPU、メモリ帯域、L3 cache、ストレージ、ネットワークまで含めて一つのローカル推論環境として設計する方向に進むだろうと思った。
半導体の不足懸念も少しずつ話題になっていたこともあり、8月頃に急いで、どういうマシン構成にするかを検討した。
自作PCは趣味だけれど、さすがに今回は金額も大きく、リスクも高かった。HPC 構成として希望する内容が組めたので、すぐに発注した。3ヶ月待ちだった。中心に置いたのは AMD EPYC 9175F だった。16C/16T というコア数だけを見ると変わり種だが、L3 cache が 512MB ある。ローカルLLM推論で CPU を主軸に考えるなら、この L3 cache の大きさはかなり魅力的だった。
最終的には、compute、storage、desktop、edge を分ける構成にした。
- compute.home.arpa は推論ノード。EPYC 9175F、DDR5 大容量メモリ、NVIDIA GPU 2枚を載せる。
- storage.home.arpa は PostgreSQL、NATS JetStream、MinIO、Gitea、OCI Registry、Prometheus、Loki、Vector、Caddy などを置くサービスノード。Mac mini Late 2018 (x86) の OS を Linux に入れ替えている。このモデルは中古で3万円くらいで手に入り、Arm 周りの面倒さがないのでかなり愛用している。メルカリでよさそうな個体を見つけたら、スペアとして集めている。24/7 利用。
- desktop.home.arpa は日常作業環境で、UI と外部ネットワークとの接点をここに集約させた。
- edge.home.arpa は RouterOS、Step-CA、Caddy による内部 TLS とネットワーク境界。
個人が購入するには、正直かなり高い構成だった。法人ではあるが、実態としてはただのフリーランスエンジニアだ。それでも、これだけは頑張る必要があった。
システムをデザインするとき、ハードウェア構成はキャンバスの大きさになる。設計・実装は、ちょうどぴったりの器に合わせて作っていく必要もあったし、なによりあまりノウハウの無い開発だったから、何度も試行する必要があったので、クラウドでお試しとはいかなかった。プロトタイプまで作った今となっては、中古で3万くらいのmac mini x86があればあとはクラウドGPUでもできると思うけど、それはノウハウがない事前にはわからなかった。
さらに買うなら、使い倒す時間も一緒に確保しないと意味がない。そこで長く関わっていた案件の仕事量を減らし、12月からフルでコミットする計画を立てた。離職の準備も進めて、あとは集中して作るだけ、というところまで持っていった。
ところが12月に入ると、昔からの取引先の技術者の方に大病が見つかった。こちらの時間を空けるどころか、逆に12月から時間を取りにくい状況になってしまった。しようがない。2月に入ってようやく落ち着き、細かい作業を少しずつ済ませていった。
最初にやったのは、LLM そのものではなく土壌作りだった。ネットワークを分け、サービスの置き場所を分け、推論、永続化、観測、開発環境の責務を分けた。いきなりエージェントを書くのではなく、まず「長く動かして、壊れたら追える」場所を作った。
最初は LLM 利用を観測するための proxy だった
当初、開発を始めたものは familiar というより、LLM 利用を観測するための軽いバックエンドだった。
Rust + axum で API を立て、バックエンドの LLM に proxy する。そこに Knowledge.Gate を挟んで、どんな prompt が投げられ、どんな response が返り、どの tool call が起き、どこで詰まったかを集める。周辺には Dagster、MLflow、NATS、Prometheus、Grafana を置いた。
その時点の関心は「自律開発エージェントを作る」よりも、「LLM を開発作業に使ったとき、何が起きているのかを観測できるようにする」ことに近かった。クラウド API を使っていても、ローカルモデルを使っていても、LLM の出力だけを眺めていると改善できない。改善したいなら、利用の履歴、失敗の形、トークン消費、モデルごとの癖を残す必要がある。
ただ、開発を進めるうちに、自分が本当にデザインしたいものが見えてきた。
単なる LLM proxy ではない。何を観測し、何を判断し、どこまで自律させるのか。そして、その判断をどこに置き、失敗したときにどう戻し、どのログを学習や改善に使うのか。時間をかけて精錬できる仕組み。そういう全体像が見えてきた。
その段階で、Rust + axum API として始めた設計と実装を捨てて、Go に置き換えた。Go にしたのは、goroutine と channel で並列実行、状態管理、スケジューリング、subscription を扱いやすかったからだ。最終的には、外部 MCP 群や Python ツールを抱えた構成ではなく、単一バイナリに近い形で自律運転できる基盤にしたかった。
動画の最後では session を落としているが、実装としては外部の pub/sub から依頼をかけられるようにしている。所定の directory からタスクを取り出し、KV を evict しながら自走し、success | fail | loop の状態に落とす仕組みもすでにデザインできている。Go を選んだ大きな理由の一つは、この loop 待機と再開のコストが低く、常駐型の orchestration runtime と相性が良かったことだ。
モデル選定は、触って肌感覚を集めるところから始めた
一通りの型ができた頃、1月あたりから徐々にモデルの選定を始めた。
この時期は、まだ集中して大きい機能を作れる時間がなかった。だから、軽めの作業としてモデルを落とし、起動し、短いタスクを投げ、挙動を観察していった。ベンチマーク表だけでは分からないものがある。prompt の崩れ方、tool call の癖、長文での粘り、空出力、XML の乱れ、tool の閉じ忘れ、CPU offload したときの待ち方、どこまで量子化できるか。そういうものは、実際に触らないと分からない。
この頃の storage 側の Hugging Face archive は、ほとんど作業ログそのものだった。
ksh3@storage-server:~$ ls -ltr /srv/archive/cold/hf/hub/
total 0
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 19:44 models--Qwen--Qwen3-VL-32B-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 20:21 models--AaryanK--IQuest-Coder-V1-40B-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 23:30 models--NousResearch--Hermes-4.3-36B
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 00:11 models--unsloth--gpt-oss-120b-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 01:56 models--NousResearch--Hermes-4-70B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 08:23 models--lmstudio-community--Llama-4-Scout-17B-16E-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 10:23 models--nvidia--Llama-3.3-70B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 11:33 models--nvidia--Llama-4-Scout-17B-16E-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 11:46 models--Firworks--command-a-reasoning-08-2025-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 19:59 models--Elias-Schwegler--IQuest-Coder-V1-40B-Loop-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 21:51 models--miromind-ai--MiroThinker-v1.5-30B
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 22:37 models--IQuestLab--IQuest-Coder-V1-40B-Loop-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 22:37 models--IQuestLab--IQuest-Coder-V1-40B-Instruct
drwxr-xr-x 6 ksh3 ksh3 85 Jan 11 01:03 models--unsloth--Llama-4-Maverick-17B-128E-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 01:47 models--pfnet--plamo-2-translate
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 02:15 models--google--functiongemma-270m-it
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 02:17 models--Firworks--gemma-3-270m-it-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 05:44 models--BCCard--gemma-3-27b-it-NVFP4A16
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 07:01 models--openai--gpt-oss-20b
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 07:27 models--google--gemma-3-27b-it
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 10:46 models--GAlex535--Qwen3-Coder-30B-A3B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 13:17 models--openai--gpt-oss-120b
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 15:20 models--mratsim--Monstral-123B-v2-NVFP4
drwxr-xr-x 6 ksh3 ksh3 85 Jan 11 15:37 models--Lightricks--LTX-2
drwxr-xr-x 5 ksh3 ksh3 64 Jan 12 01:04 models--ChristianAzinn--mixtral-8x22b-v0.1-imatrix
drwxr-xr-x 5 ksh3 ksh3 64 Jan 20 08:57 models--Firworks--NVIDIA-Nemotron-3-Nano-30B-A3B-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 20 10:13 models--Qwen--Qwen3-Coder-30B-A3B-Instruct-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Jan 22 04:07 models--zai-org--GLM-4.7-Flash
drwxr-xr-x 5 ksh3 ksh3 64 Feb 5 15:11 models--nvidia--NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 13 22:57 models--unsloth--Qwen3-Next-80B-A3B-Thinking-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 14 00:46 models--AesSedai--Step-3.5-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 06:15 models--unsloth--GLM-5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 11:44 models--ubergarm--GLM-4.7-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 18:10 models--DavidAU--GLM-4.7-Flash-Uncensored-Heretic-NEO-CODE-Imatrix-MAX-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 19:11 models--bartowski--Qwen_Qwen3-Coder-Next-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 16 00:52 models--ubergarm--DeepSeek-V3.2-Speciale-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 16 03:44 models--DavidAU--Openai_gpt-oss-120b-NEO-Imatrix-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 17 08:49 models--ubergarm--MiniMax-M2.5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 17 19:40 models--GadflyII--Qwen3-Coder-Next-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 15:12 models--ACE-Step--Ace-Step1.5
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 15:41 models--mistralai--Voxtral-Mini-4B-Realtime-2602
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 17:18 models--black-forest-labs--FLUX.2-klein-9B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 23:14 models--LiquidAI--LFM2-8B-A1B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 00:09 models--LiquidAI--LFM2-8B-A1B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 05:58 models--LiquidAI--LFM2.5-1.2B-Thinking
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 06:03 models--LiquidAI--LFM2.5-VL-1.6B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 06:07 models--LiquidAI--LFM2.5-1.2B-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 19:49 models--ubergarm--Devstral-2-123B-Instruct-2512-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 23 20:30 models--AesSedai--MiniMax-M2.5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 24 06:41 models--nvidia--Qwen3-Next-80B-A3B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 24 06:47 models--nvidia--Qwen3-Next-80B-A3B-Thinking-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 01:54 models--AesSedai--Qwen3.5-35B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 03:16 models--AesSedai--Qwen3.5-122B-A10B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 16:57 models--Sehyo--Qwen3.5-122B-A10B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 19:39 models--Qwen--Qwen3.5-27B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 2 04:18 models--mmnga-o--NVIDIA-Nemotron-Nano-9B-v2-Japanese-gguf
drwxr-xr-x 5 ksh3 ksh3 64 Mar 2 06:23 models--nvidia--NVIDIA-Nemotron-Nano-9B-v2-Japanese
drwxr-xr-x 5 ksh3 ksh3 64 Mar 3 02:56 models--bartowski--Qwen_Qwen3.5-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 3 03:53 models--ubergarm--Qwen3.5-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 05:21 models--perplexity-ai--pplx-embed-context-v1-0.6b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 05:24 models--perplexity-ai--pplx-embed-v1-0.6b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 08:22 models--perplexity-ai--pplx-embed-context-v1-4b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 08:23 models--perplexity-ai--pplx-embed-v1-4b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 14 00:30 models--AesSedai--NVIDIA-Nemotron-3-Super-120B-A12B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 14 11:03 models--nvidia--NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 17 23:30 models--fishaudio--s2-pro
drwxr-xr-x 5 ksh3 ksh3 64 Mar 17 23:36 models--mradermacher--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-i1-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 18 00:00 models--bartowski--Qwen_Qwen3.5-4B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 18 16:24 models--AesSedai--Mistral-Small-4-119B-2603-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 23 04:31 models--AesSedai--Nemotron-Cascade-2-30B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 03:02 models--mconcat--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 03:37 models--Qwen--Qwen3.5-9B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 04:54 models--chankhavu--Nemotron-Cascade-2-30B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:50 models--Jackrong--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:57 datasets--OpenMOSS-Team--OmniAction
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:59 datasets--Roman1111111--claude-opus-4.6-10000x
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 22:11 datasets--nvidia--Nemotron-Terminal-Corpus
drwxr-xr-x 5 ksh3 ksh3 64 Mar 28 05:43 models--nvidia--Nemotron-Cascade-2-30B-A3B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 28 09:17 datasets--nvidia--Nemotron-Terminal-Synthetic-Tasks
drwxr-xr-x 6 ksh3 ksh3 85 Mar 29 14:33 models--HauhauCS--Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 17:33 models--Qwen--Qwen3.5-4B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 18:47 models--Qwen--Qwen3.5-35B-A3B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 18:55 models--mistralai--Mistral-Small-4-119B-2603-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 08:24 models--Qwen--Qwen3.5-9B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 08:24 models--zed-industries--zeta-2
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 11:24 models--nvidia--MiniMax-M2.5-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 12:59 models--sentence-transformers--all-MiniLM-L6-v2
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 13:02 models--datalab-to--chandra-ocr-2
drwxr-xr-x 5 ksh3 ksh3 64 Apr 2 14:29 datasets--ianncity--KIMI-K2.5-450000x
drwxr-xr-x 5 ksh3 ksh3 64 Apr 2 14:42 datasets--open-index--hacker-news
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 00:49 models--bartowski--google_gemma-4-26B-A4B-it-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 02:31 models--lightonai--LateOn-Code-edge
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 02:32 models--mixedbread-ai--mxbai-edge-colbert-v0-17m
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 11:33 models--google--gemma-4-26B-A4B-it
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 17:15 models--ubergarm--Step-3.5-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 6 07:00 models--bartowski--Qwen_Qwen3.5-9B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 8 15:31 datasets--nohurry--Opus-4.6-Reasoning-3000x-filtered
drwxr-xr-x 5 ksh3 ksh3 64 Apr 8 16:17 datasets--ianncity--KIMI-K2.5-1000000x
drwxr-xr-x 6 ksh3 ksh3 85 Apr 8 16:38 models--ubergarm--Qwen3-Coder-Next-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 11 05:57 models--google--translategemma-4b-it
drwxr-xr-x 5 ksh3 ksh3 64 Apr 11 06:20 models--llm-jp--llm-jp-4-32b-a3b-base
drwxr-xr-x 5 ksh3 ksh3 64 Apr 12 18:35 models--MiniMaxAI--MiniMax-M2.7
drwxr-xr-x 6 ksh3 ksh3 85 Apr 13 02:52 models--ubergarm--MiniMax-M2.7-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 14 09:24 models--llm-jp--llm-jp-4-32b-a3b-thinking
drwxr-xr-x 5 ksh3 ksh3 64 Apr 16 09:22 models--AesSedai--Qwen3.5-397B-A17B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 17 08:51 models--AesSedai--Qwen3.6-35B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 20 09:02 models--cyberagent--CAT-Translate-7b
drwxr-xr-x 5 ksh3 ksh3 64 Apr 20 14:25 datasets--Jackrong--GLM-5.1-Reasoning-1M-Cleaned
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 00:11 models--openai--privacy-filter
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 15:41 models--Qwen--Qwen3.6-27B
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 16:36 models--Qwen--Qwen3.6-27B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 00:41 models--huihui-ai--Huihui-GLM-5.1-abliterated-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 11:19 models--deepseek-ai--DeepSeek-V4-Flash
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 15:24 datasets--Modotte--CodeX-2M-Thinking
drwxr-xr-x 5 ksh3 ksh3 64 Apr 27 01:44 models--nsparks--DeepSeek-V4-Flash-FP4-FP8-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 27 16:02 models--zai-org--GLM-5.1
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 16:51 models--Qwen--Qwen3.6-35B-A3B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 17:22 models--Qwen--Qwen3.6-35B-A3B
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 17:43 models--AesSedai--Kimi-K2.6-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 30 18:40 models--RedHatAI--DeepSeek-V4-Flash-NVFP4-FP8
drwxr-xr-x 5 ksh3 ksh3 64 May 1 16:03 datasets--AlicanKiraz0--Cybersecurity-Dataset-Fenrir-v2.1
drwxr-xr-x 5 ksh3 ksh3 64 May 1 22:50 models--ubergarm--GLM-5.1-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 2 09:46 models--mistralai--Mistral-Medium-3.5-128B
drwxr-xr-x 5 ksh3 ksh3 64 May 2 09:55 models--mistralai--Mistral-Medium-3.5-128B-EAGLE
drwxr-xr-x 5 ksh3 ksh3 64 May 2 14:43 models--RedHatAI--Qwen3.6-35B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 3 14:55 models--ubergarm--Qwen3.6-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 4 03:57 models--sakamakismile--Qwen3.6-27B-Text-NVFP4-MTP
drwxr-xr-x 5 ksh3 ksh3 64 May 4 15:06 datasets--Kassadin88--GLM-5.1-OpenThoughts3-Distill
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:01 models--LilaRest--gemma-4-31B-it-NVFP4-turbo
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:04 models--nvidia--Gemma-4-31B-IT-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:05 models--google--gemma-4-31B-it-assistant
drwxr-xr-x 5 ksh3 ksh3 64 May 9 01:20 models--RecViking--Mistral-Medium-3.5-128B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 10 02:52 models--ubergarm--Kimi-K2.6-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 10 07:18 models--google--gemma-4-31B-it
drwxr-xr-x 5 ksh3 ksh3 64 May 10 10:25 models--Zyphra--ZAYA1-74B-preview
drwxr-xr-x 5 ksh3 ksh3 64 May 12 16:37 models--AesSedai--MiMo-V2.5-Pro-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 12 17:21 models--antirez--deepseek-v4-gguf
ksh3@storage-server:~$
uncensored 系のような汎用ではないもの、癖の強いストーリーテラー、画像生成、ビデオ生成、セキュリティ用途、コーディング、OCR。思いつくユースケースは一通り試した。 この一覧は単なるコレクションではない。どのモデルをどの役割に置けるか、どの量子化ならローカルで耐えるか、どういった癖を持つかを探った履歴だ。
Claude を試して、すぐに後悔した
僕はコードを書くのがすごく好きだ。
だから、AI コーディング支援についても、かなり頑なにインラインオートコンプリートだけを使っていた。Copilot 的なものは便利だけれど、コードを書く主体は自分でありたい。そういう感覚が強かった。
今年の2月に、Claude を試した。きっかけは、戦争利用に反対する表明を見て「いいな」と思ったことだった。実際に使ってみると、すぐに「あー、なんでもっと速く使わなかったんだろう」とすごく後悔した。
歳を重ねるうちに、毎日のコーディングで肩こりや腱鞘炎に悩まされてきた。もう数年でリタイアかなと思うこともあった。でも Claude を使って、大好きな開発をまだ続けられるなと確信した。だから、自分の癖、ノウハウ、設計思想、何を捨てるかの基準を、システムで補完したかった。
ちょうど、自分のローカル基盤側でもアーキテクチャ全体の骨組みができ始めていた。だから3月頃から、Claude を開発作業に入れていった。最初の狙いは、Claude や Codex をそのまま組み込むことではなかった。小さい依存として claude -p や Codex にプロンプトを渡し、ローカルLLMのオーケストレーター候補と同じような仕事をさせる。その振る舞いを観察しながら、最終的には CPU 推論でも動かせる 100B 超級のローカルオーケストレーターモデル候補へ、ゆっくり育てていくつもりだった。
4月に、いったん壊す判断をした
4月に Anthropic の方針転換があり、状況が変わった。
サブプロセスから claude -p を呼び、エージェントが自律的に使う形はグレーに見えた。Reddit でも BAN されたという投稿が散見された。そこで、Claude や Codex に関連する実装を全部壊した。
これは痛かった。せっかく動き始めていたものを捨てることになる。ただ、その時点で分かったのは、自分が本当に必要としているのは Claude そのものではなく、オーケストレーションの知見だったということだ。
どの粒度でタスクを分けるのか。ワーカーに何を渡すと失敗するのか。どの失敗は再試行で戻るのか。どの失敗は設計を変えないと戻らないのか。レビューはどのタイミングで入れるべきか。並列実装の衝突は誰が統合すべきか。こうした判断を、外部ツールの挙動に頼らず、自分の基盤の中で観測して蓄積する必要が出てきた。
そこで集中して作り始めたのが、Vector、Tempo、Alloy、PostgreSQL ベースの観測テーブルだった。
これは筋が良かった。
エージェントの振る舞いは、ログを眺めるだけでは分からない。plan、dispatch、worker result、tool call、token usage、task failure、review verdict、recovery を同じ correlation の中で追えるようにして初めて、「なぜそう動いたのか」を考えられる。
この頃から、Grafana は単なるメトリクス表示ではなく、familiar の思考過程を読むための作業画面になっていった。dashboard も増え、役割別、task 別、tool call 別、latency 別に見方を切り替えられるようになった。
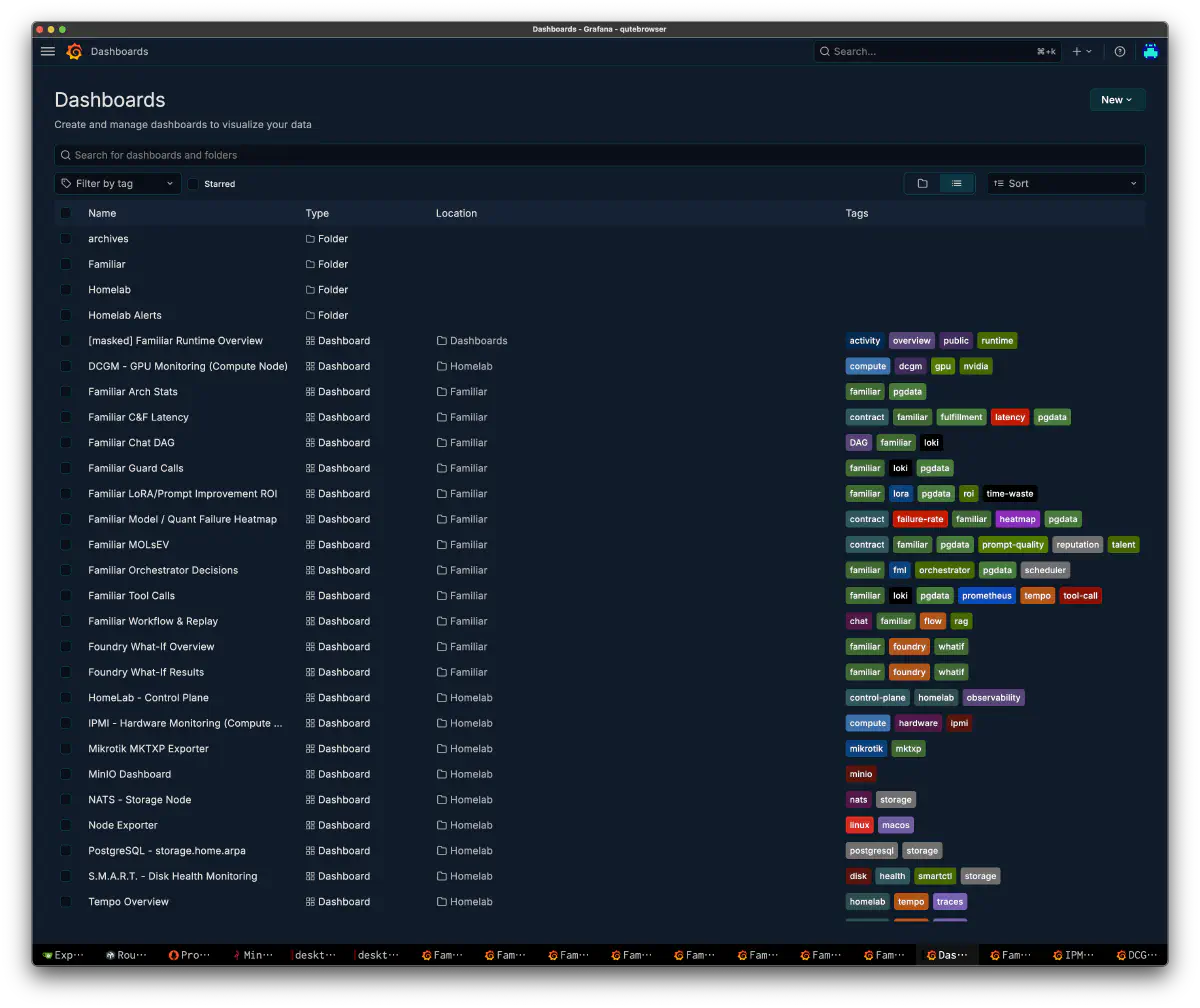
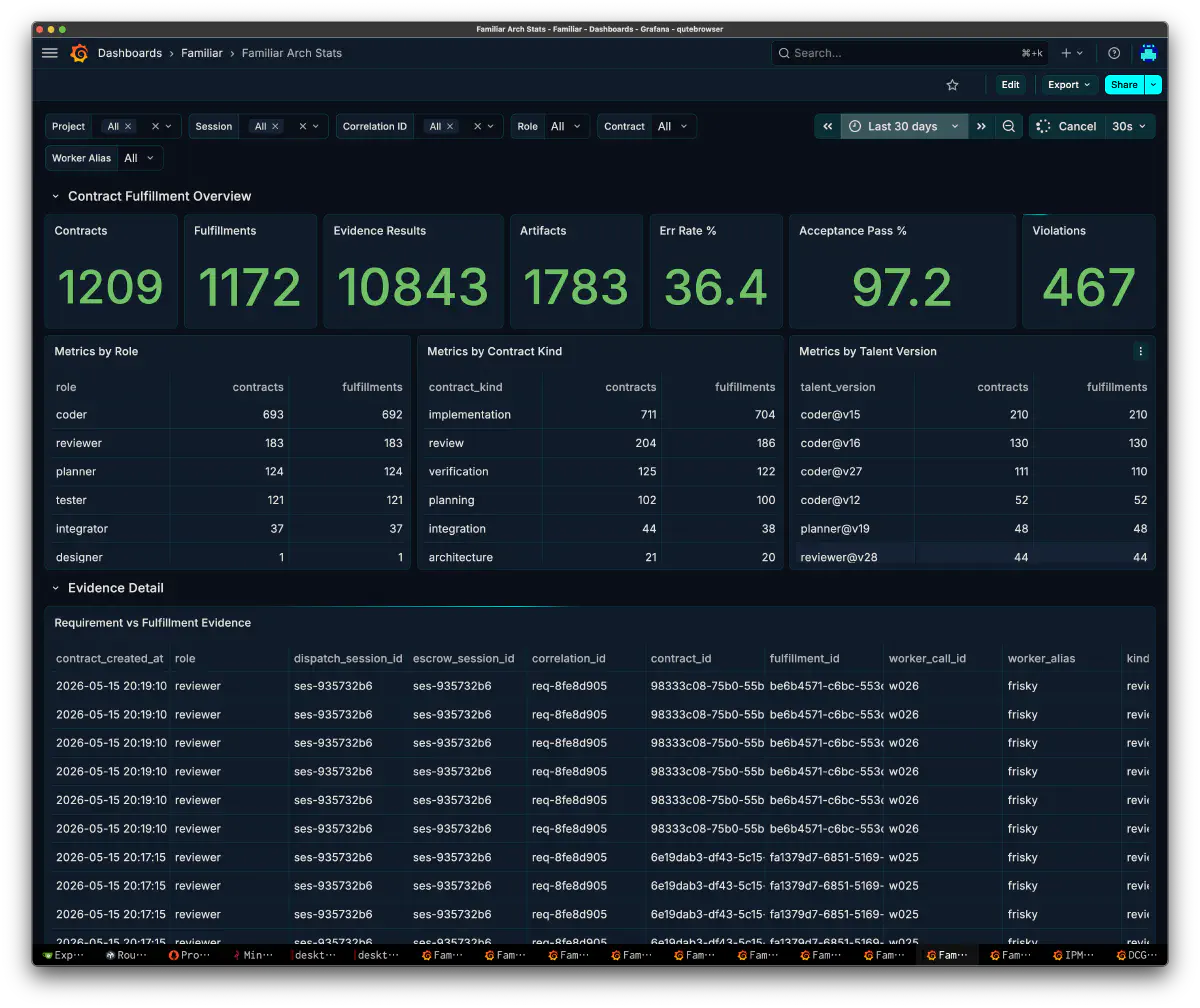
観測できるようになると、思考と試行のループができる。Grafana と PostgreSQL を見る。うまくいかなかった session を読み、散歩しながら、ふと「もしかしたらこういう動きになるのでは」と理解が進む。帰ってから実装の形を変え、また走らせる。
結果的に、Claude と Codex を排除したことで、1から理解する機会を得られた。繰り返すべき実験の型ができ、PDCA が回り始めた。
本体より、ツールを作っていた
3月頃は、モデル選定と振る舞いの観測を続けながら、ローカルLLMには苦手なところを補完してあげる必要があると感じていた。
ローカルLLMは、クラウドの巨大モデルより弱いという単純な話ではない。弱いところが違う。長い文脈での記憶の保持、曖昧なファイル探索、実行結果の解釈、同じ失敗を繰り返さないための状態管理、どの情報を次のターンに持ち越すか。そういう部分をモデル単体に期待しすぎると、すぐに破綻する。
だから、本体を細部で太らせるより、まず全体の振る舞いを観測し、共通する問題に対して周辺の道具を作る必要があった。
最終的に、MCP、管理、デバッグ系のツールを15個くらい作った。この頃は体感としては、familiar 本体が2割、ツール開発が8割くらいだった。エージェントの知能をプロンプトだけに閉じ込めるのではなく、観測、検索、構造化、検証、復旧の足場を外側に作っていく作業だった。
観測系が多くなるのは当然だった。LLM 自体が、返り値の読めない関数みたいなものだからだ。入力を渡すと何かを返すが、その内部状態は見えない。しかも同じ入力でも、コンテキスト、温度、直前の失敗、ツールの使い方で振る舞いが変わる。それをさらに複数のモデルで連鎖させて因果を調べるとなると難しい。
だから見るべきものは、最終結果だけではない。結果だけを見ると、「成功した」「失敗した」で終わってしまう。必要なのは、一連の振る舞いと変化を理解できることだった。どの時点に因果があるのか。なぜこのツールを呼んだのか。何が認知負荷なのか。どの失敗はリワークで戻り、どの失敗は恒久対策を要求するのか。
この発想が、familiar の MCP ツール群の設計にもそのまま出ている。つまり、分からないことを runtime 側で不変な関数にして、分かるようにしていけばいい。その仕分けと整理が必要だった。
そのためには、これまで良いとされてきた開発から大きく方針転換する必要もあった。
僕はコメントがないプログラムのほうが好きだ。ラベルは付けるけれど、説明はシンボルですべきだと思っている。コードのアウトラインを見れば多くは理解できるし、細部を見なくても、実装したテストのシンボルを見れば意図は分かる。
コメントを書く、書かないの話ではない。これは自分に対しても、誰かに対しても、思いやりの話だと思っている。コメントを書くということは、結果として相手に読んでほしいということだ。だから、できるだけ読まなくても分かるように、シンボル名を何度も考え、変え、アウトラインを揃えることに注力する。読む量を少しでも少なくする。それが僕なりの思いやりであって、コメントなんだと思う。
でも、これは僕の考えであって、familiar では実装する LLM にとって働きやすい環境こそが、彼らにとっての良いコードになった。コメントは必要だし、うまく検索するためのラベルも必要だ。相手の立場に立つと、何を実装すればよいかが決まってくる。
コーディングをする僕たちは、経験が長くなるほど、構造化された型データを好きになりやすい。だけど、LLM の context に渡すデータでは、必ずしも型で担保することが正解ではない。これも大きな気づきだった。
反復する型はノイズと未練を残すことがある。逆に、ダイナミックな形にすることで、LLM が知る必要のないことを隠せる。つまり、関心を分離できる。こういう、いわゆるアンチパターンへの理解も少しずつ進んだ。 物事の良し悪しは、都合の解釈でしかないということだ。
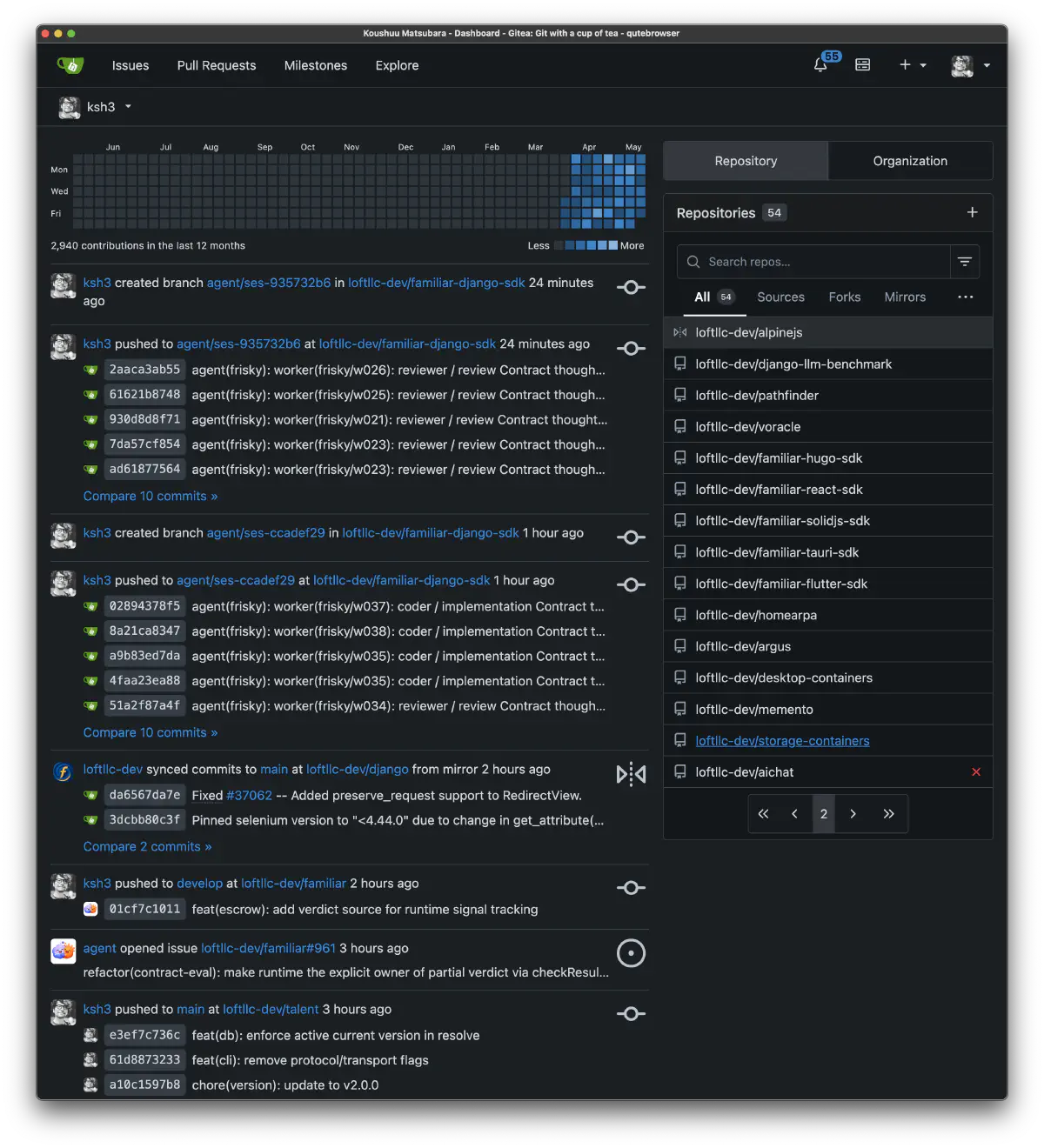
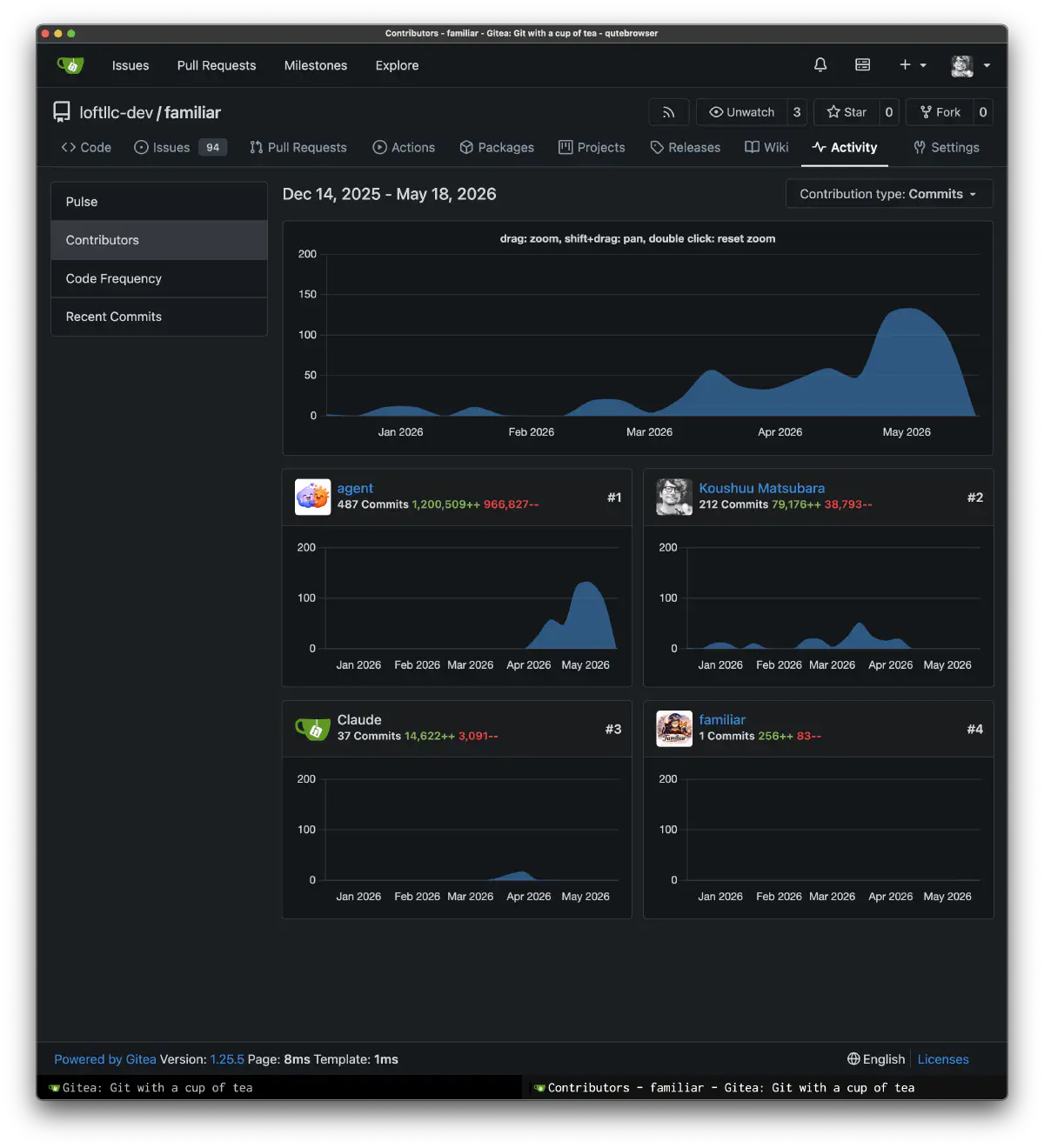
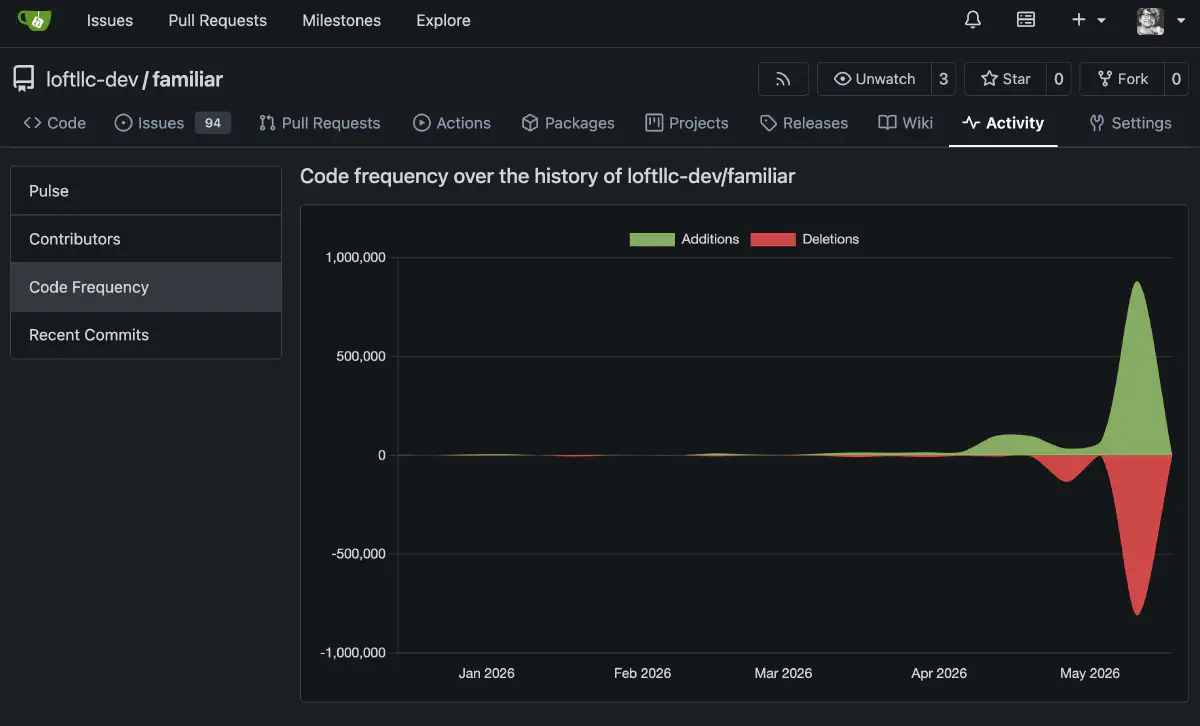
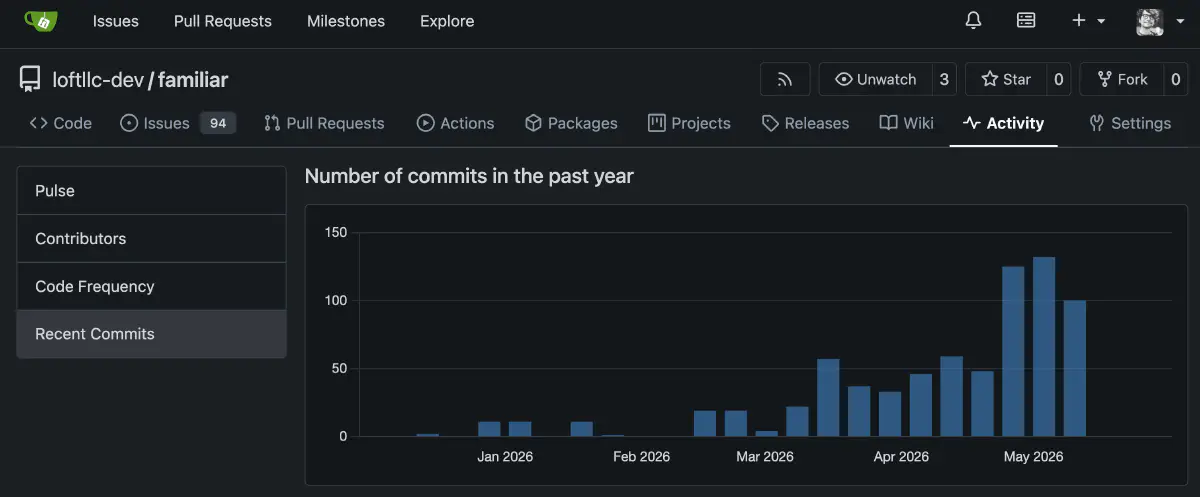
やっと開発のスタートラインに立てた感覚がある。これから学習、世代管理など、やることはまだまだある。ここ数ヶ月、根を詰めてやっていたので、ここで一区切りの記録を残しておく。また機会があれば続きを書きたい。