Gemma 4 + Blackwell 2枚で組む familiar 推論スタックと model-foundry パイプライン
Blackwell GPU 2枚に Gemma 4 ファミリーを載せた familiar 推論スタックの構成設計。NVFP4 + vLLM と IQ4_XS + llama.cpp の使い分け、model-foundry の Dagster パイプライン分離、Grafana テレメトリ可視化まで。

この記事について
homelab の LLM 推論スタックを Gemma 4 ファミリーで統一した構成の記録。ハードウェアの選定からモデルの割り当て、familiar オーケストレータのロール設計、Dagster パイプラインの分離、テレメトリの可視化までを一本の流れで書く。
ハードウェア: EPYC + Blackwell x 2
compute node の仕様:
- CPU: AMD EPYC 9175F
- RAM: 768GB
- GPU: RTX 6000 PRO MAX-Q 96GB Blackwell x 2(NVLink なし)
GPU 2枚を独立して使う構成にした。NVLink がないので Tensor Parallel は使えないが、2つのモデルを別々の GPU に載せて parallel slot を最大化するほうが、初期フェーズでは有利だと判断した。目的はデータ収集のスループットであって、単一モデルの推論速度ではない。
Gemma 4 ファミリーで統一する判断
立ち上げフェーズではモデルの多様性より複雑性の最小化を優先した。Gemma 4 がリリースされたタイミングで、スコアが良くかつ GPU メモリに収まる 31B dense と 26B-A4B MoE の2つを採用した。
異種モデルによるデータ多様性は、familiar が安定稼働してデータパイプラインが回り始めてからの課題。最初に複数ファミリーを混ぜると、モデルごとのプロンプト調整やフォーマットの差異でデバッグが増える。まずは Gemma 4 で全部動かして、パイプラインを検証する。
モデル割り当てと GPU メモリ設計
| slot | model | format | runtime | VRAM | parallel | GPU |
|---|---|---|---|---|---|---|
| naughty | Gemma 4 31B IT | NVFP4 | vLLM | ~17GiB | 3 | GPU0 |
| kindergarten | Gemma 4 26B-A4B IT | IQ4_XS | llama.cpp | ~13GiB | 5 | GPU1 |
GPU メモリ割り当て:
- GPU0 (96GB): Gemma 4 31B NVFP4 ~17GiB + KV cache x 3 parallel slots (~79GB 空き)
- GPU1 (96GB): Gemma 4 26B-A4B IQ4_XS ~13GiB + KV cache x 6 parallel slots (~83GB 空き)
naughty: Gemma 4 31B NVFP4 on vLLM
NVFP4 は NVIDIA TensorRT Model Optimizer 形式で、Blackwell の FP4 カーネルでフル最適化される。vLLM の continuous batching で parallel 3 のスループットを最大化する。thinking mode、native function calling、system prompt に対応。
ベンチマーク:
- AIME 2026: 89.2%
- LiveCodeBench v6: 80.0%
- Codeforces ELO: 2150
- GPQA Diamond: 84.3%
- MMLU Pro: 85.2%
31B dense で AIME 89.2% はかなり良い。NVFP4 量子化で VRAM ~17GiB に収まるのも大きい。96GB GPU に対して KV cache に十分な余裕がある。
kindergarten: Gemma 4 26B-A4B MoE on llama.cpp
26B-A4B は MoE(Mixture of Experts)で、アクティブパラメータは 4B。推論時のメモリフットプリントが小さく、parallel slot を多く取れる。IQ4_XS (bartowski) で ~13GiB。
ik_llama.cpp を使うのは、MoE モデルの推論でパフォーマンスが良いから。vLLM は dense モデルの continuous batching が得意だが、MoE の GGUF 量子化モデルは ik_llama.cpp のほうが扱いやすい。
familiar のモデルロール設計
familiar には grandpa / naughty / kindergarten / translator の4ロールがある。CLAUDE.md で構成を切り替える:
grandpa x naughty x kindergarten x translator # フル構成
naughty x translator # 最小構成
naughty x kindergarten x translator # 標準構成
grandpa は推論速度よりも品質を重視するスロットで、トークン/秒のバランシングを担う。ただし初期フェーズではデータセット収集の parallel 処理性能を優先したいので、grandpa を外した naughty x kindergarten x translator が標準構成になる。
translator は plamo-2-translate を使う翻訳専用スロット。日英翻訳の品質が高く、多言語記事パイプラインで使っている。
model-foundry: Dagster パイプラインの分離
推論スタックと並行して、Dagster パイプラインの独立リポジトリ化も進めた。
もともと agent-gateway の devstack/dagster/ に同居していた Dagster パイプラインを model-foundry として分離した。Dagster パイプラインはゲートウェイのインフラ付属物ではなく、独立したデータパイプライン基盤として機能していたから。
DuckDB 導入で見えるようになったもの
分離後に DuckDB を導入したら、Dagster UI の可視性が劇的に改善した。
導入前は各アセットを個別に開いて確認する必要があったが、導入後は pipeline_event_inbox_record アセットの STEP_OUTPUT に event_id、subject、correlation_id が構造化された dict で表示される。パイプラインの実行状況が一画面で把握できるようになった。
DuckDB 導入直後に型チェックエラーが出た:
dagster._core.errors.DagsterTypeCheckDidNotPass: Type check failed for step input
"pipeline_event_inbox_record" - expected type "dict".
Value of type <class 'NoneType'> failed type check
NATS キューが空のときにアセットが None を返す実装になっていた。空イベントのハンドリングを修正。
イベント名のリデザイン
knowledge domain のパイプラインイベント名も整理した:
| 旧名 | 新名 |
|---|---|
knowledge.chat.persist | llm.chat.persist |
knowledge.embedding | obsidian.semantic_search |
knowledge.flow.lineage | llm.flow.lineage |
knowledge.tool_call | llm.tool_call |
knowledge.* は knowledge domain の内部実装を漏らしていた。新名は「どのシステムに対して行うか」を表すトピック設計に変更した。これは後のv3 リデザインでのドメイン3分割に繋がる布石でもあった。
Grafana LLM ダッシュボード
推論スタックのテレメトリを Grafana で可視化する。
データフロー
familiar -> Vector (HTTP port 8687 /telemetry) -> Prometheus / Loki -> Grafana
描画方針:
- Grafana は Vector 経由のリアルタイムデータで描画する(PostgreSQL を直接参照しない)
- 永続化は PostgreSQL にフラットに持つ
- 要約が必要なものは Dagster + DuckDB で加工
Vector の http_telemetry ソースが familiar のテレメトリイベントを受け取り、Prometheus へのメトリクス転送と Loki へのログ保存を同時に担う。correlation_id で一連のセッションを横断的に追跡できる。
Vector の設定:
[sources.http_telemetry]
type = "http_server"
address = "0.0.0.0:8687"
path = "/telemetry"
encoding = "json"
familiar が発行するテレメトリイベントは JSON で POST される。Vector がこれを受け取り、Prometheus 用のメトリクス変換と Loki へのログ転送を並行で実行する。Grafana ダッシュボードはこの2つのデータソースを組み合わせて、リアルタイムの推論パフォーマンスとセッションフローを描画する。
実際に Gemma 4 を回してみた所感
nvidia/gemma-4-31b-it-nvfp4 を vLLM で --max-num-seqs 3、ik_llama.cpp の gemma4 ブランチで Q4_K_L を --parallel 5 で実験した。Go の channel でキューイングを制御して、concurrency でフルに回す構成。
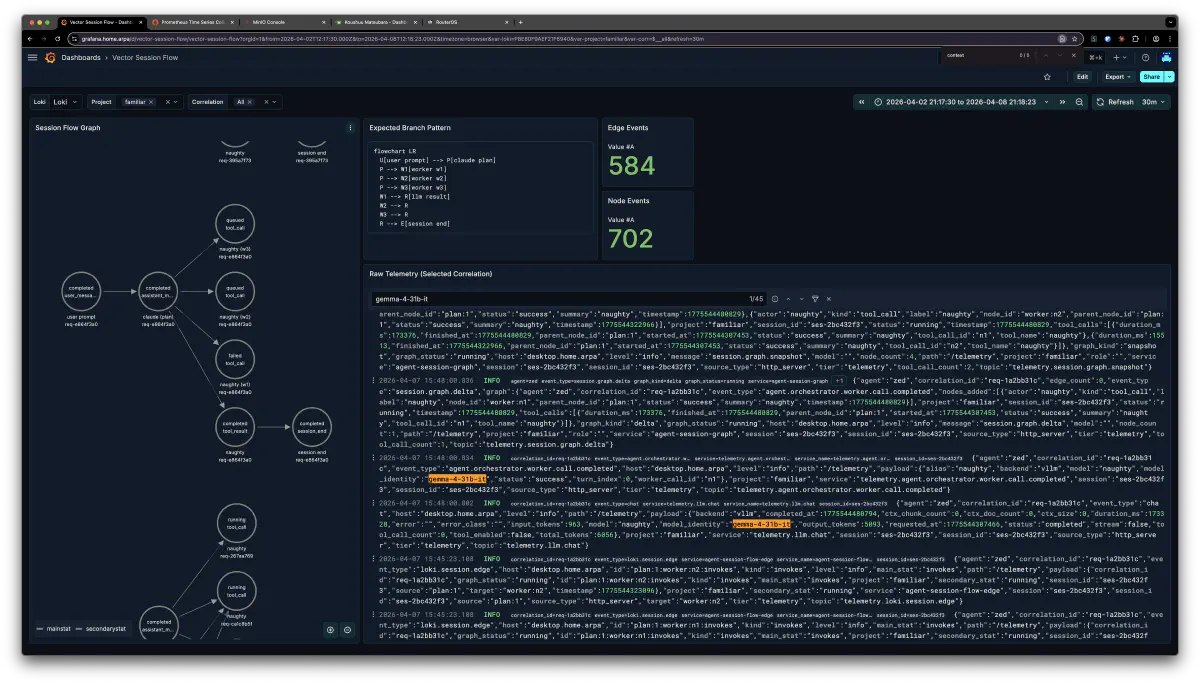
結果として、オーケストレータモデルが 26B MoE 側(kindergarten)にルーティングしなかったので、試せたのは 31B IT x 3 の並行実行だけだった。成果物自体はまるっと出来上がったが、協調性がない。
KV cache が同居しているので、ある程度似た方向に寄るかと期待していたが、実際にはあまり関係なかった。同じプランニングを渡していても、3つの worker の統制が取れていない。各 worker が独立して推論を進めるので、片方が決めた方針をもう片方が無視するような動きになる。
ここから得た教訓: コーディングタスクに限定するなら、any-to-any のような汎用モデルはオーケストレータだけに使うほうがいい。worker には特化したプロンプトとコンテキストで制約をかけないと、parallel 実行で品質が担保できない。データ収集のスループットを上げたいなら parallel は有効だが、協調的な成果物を期待するならオーケストレータの設計が先に必要だった。
その後: GLM-5.1 + Qwen3-Coder-Next 構成
この実験の後、ちょうど grandpa 役に最適な GLM-5.1 がリリースされた。Kimi-K2.5 と入れ替えて、コーディング向きの Qwen3-Coder-Next と組み合わせた構成にしたところ、良い成果が取れた。
dev0 / GLM-5.1 (grandpa)
PP: 340 tok/s
TG: 12-16 tok/s
dev0 / Qwen3-Coder-Next (worker-0)
PP: 2500 tok/s
TG: 114 tok/s
dev1 / Qwen3-Coder-Next (worker-1)
PP: 5100 tok/s
TG: 161 tok/s
dev1 / PLaMo2Translate (translator)
PP: 100-240 tok/s
TG: 35-140 tok/s
オーケストレータに推論力の高いモデル、worker にコーディング特化モデルを置く構成のほうが、Gemma 4 統一構成より明確に協調が取れた。この構成の詳細はまたの機会に書く。