Go + NATS + Dagster によるAIオーケストレーション基盤:設計思想からミドルウェア選定まで
Go(Gin)によるOpenAI/Anthropic互換プロキシ、NATS JetStreamイベント中継、Dagster sensorによるジョブ実行、pgvector ANN検索、ColBERTリランキング。3ホスト構成のローカルAIオーケストレーション基盤の設計全記録。

結論
LLMを業務パイプラインに統合するために、OpenAI/Anthropic互換のAPIゲートウェイをGoで構築した。ゲートウェイはリクエストを受けてRAGオーケストレーションを行い、NATS JetStreamにイベントをfire-and-forgetでpublishする。消費側はDagster daemonのsensorがJetStreamからpullしてジョブを直接実行する。テレメトリはVector(Rust)がNATSからsubscribeしてPrometheus/Lokiに流す。
設計の核心は「gatewayはpublishだけ、consumeは各ミドルウェアが独立に行う」という責務分離にある。この判断によりgatewayのコードにDagsterの依存がなくなり、デプロイが完全に分離された。
初期にRust(axum)で設計したプロトタイプの経験を経て、Goに全面移行した。SSE中継 + NATS購読 + PG/Qdrant書き込みが同時に走る非同期コンテキストの管理がRustでは冗長であり、goroutine + channelの方がこのパターンに素直にフィットした。
前提
- 言語: Go 1.25, Gin フレームワーク
- メッセージング: NATS 2.11 (JetStream有効)
- オーケストレーション: Dagster (Python) — daemon + sensor + asset materialization
- データストア: PostgreSQL 18 + pgvector (JIT有効)
- テレメトリ: Vector 0.45 (Rust) → Prometheus + Loki + Grafana
- 推論バックエンド: vLLM, llama.cpp, LM Studio
- エンベディング + リランカー: multi-bert-inference — Rust (Axum) + ONNX Runtime (INT8, ~17MB, ~10ms)。ColBERT 256d embed + 64d token MaxSim rerank。DB依存排除、gRPCで256d vec直接送信(~1KB/candidate)
- コンテナ: Podman rootless + podman-compose
- ホスト構成: 3台 (storage server / desktop mac / compute server)
設計判断
レイヤードアーキテクチャ
Clean Architectureの依存方向ルールに従い、Transport → Domain → Infraの3層に分離した。
Client (opencode CLI, API consumer)
|
v
Transport Layer (Gin) [internal/transport/http/]
|-- middleware: RequestContext -> Logger -> Recovery
|-- v1/ handlers (OpenAI/Anthropic 互換エンドポイント)
|-- リクエスト解析・バリデーション
+-- Presentation DTO への変換
|
| Presentation Layer [pkg/openai/, pkg/anthropic/]
| +-- OpenAI/Anthropic 互換 request/response DTO
|
v
Domain Layer [internal/domain/]
|-- knowledge/ RAG オーケストレーション
|-- llm/ マルチバックエンド LLM ルーティング
|-- vectorstore/ ベクトル検索 (pgvector ANN)
+-- pipeline/ パイプライン連携 (NATS publish, fire-and-forget)
|
v
Infrastructure Layer [internal/infra/]
|-- vllm/ vLLM クライアント
|-- llamacpp/ llama.cpp クライアント
|-- lmstudio/ LM Studio クライアント
|-- postgres/ PostgreSQL + pgvector
|-- nats/ NATS JetStream publish
|-- vector/ Vector テレメトリ publish
+-- reranker/ multi-bert-inference gRPC クライアント
Domain層は外部依存を一切持たない。LLMバックエンドの追加やデータストアの変更はInfra層の差し替えだけで完結する。
Gateway は publish only
gatewayはNATSにpublishするだけ。subscribeやtriggerは行わない。消費側(Dagster sensor, Vector)が独立してpull/subscribeする。
この判断の理由:
- gatewayのコードにDagsterの依存がない → デプロイ分離
- 消費側を後から追加・変更してもgatewayに影響しない
- gatewayの障害がパイプライン側に波及しない
Dagster sensor で JetStream pull
Dagster daemonがdurable consumerとしてJetStreamからpull subscribeし、sensor → RunRequest → ジョブ直接実行する。GraphQL trigger bridgeを排除し、Dagsterのネイティブsensor機構に一本化した。
なぜ Dagster (Python) か
Dagsterはオーケストレーター(指揮者)であり、計算の実行者ではない。重い処理はすべてPythonの外で動く。
| 実際の計算 | 実行エンジン | Python/Dagster の役割 |
|---|---|---|
| LLM 推論 | vLLM / llama.cpp (C++/CUDA) | API 呼び出しのみ |
| ベクトル検索 | PostgreSQL + pgvector (C) | SQL 発行のみ |
| エンベディング + リランキング | multi-bert-inference (Rust/ONNX Runtime) | gRPC 呼び出しのみ |
| テレメトリ変換 | Vector (Rust) | YAML 設定のみ |
Rust製のDagster代替は存在しない。オーケストレーターの性能要件はI/O wait + 状態管理であり、Rustの強み(CPU bound, メモリ安全)が活きない。Dagsterの価値はlineage tracking + sensor + asset materializationの設計思想にある。
LLM バックエンド選定
リクエストされたモデル名に基づいてバックエンドを自動選択する。
| バックエンド | デフォルト URL | モデル例 |
|---|---|---|
| vLLM | http://$COMPUTE_HOST:8000 | qwen3-next:80b, qwen3-coder:30b |
| llama.cpp | http://$COMPUTE_HOST:8081 | nemotron-3-nano:30b |
| LM Studio | http://$COMPUTE_HOST:1234 | lfm2.5-1.2b-instruct-mlx |
LLMルーティングはgatewayのgoroutineが担当する。レスポンス内容を見て次のバックエンドを決める制御フローはステートフルな判断が必要なため、Vectorでは代替不可。
モデルは常時検証を行っている。storage serverのコールドストレージにGGUF、NVFP4、ONNX等の各フォーマットで検証済みモデルをアーカイブし、新モデルのリリースに追随して性能・品質を評価している。

Rust から Go への移行
初期にRust(axum)でプロトタイプを設計・実装した。精密な型システムによる設計は有益だったが、大量の非同期処理の記述コストが高かった。
- SSEの中継 + NATSの購読 + PG/pgvectorへの書き込みが同時に走る非同期コンテキストの管理がRustでは冗長
- goroutine + channelの方がこのパターンに素直にフィットする
- 実行時オーバーヘッドの差はこのユースケースでは無視できるレベル
Go移行後も設計原則は保持した: OpenAI互換エンドポイント、NATS Pub/Subイベント駆動、trace_id付きの全ログ、冪等設計。Rust版の設計ドキュメントはそのまま仕様書として機能した。
実装
エンドポイント
| Method | Path | 説明 |
|---|---|---|
| POST | /v1/chat/completions | チャット補完 (OpenAI互換) |
| POST | /v1/messages | Anthropic Messages API |
| POST | /v1/responses | Responses API |
| POST | /v1/embeddings | エンベディング |
| GET | /v1/models | モデル一覧 |
| GET | /healthz | ヘルスチェック |
ミドルウェアチェーン
Gin ミドルウェア: RequestContext → Logger → Recovery
- RequestContext —
X-Correlation-IDまたはX-Request-IDヘッダからリクエスト追跡IDを抽出。未指定時はタイムスタンプベースのIDを自動生成し、コンテキストとレスポンスヘッダに設定 - Logger — HTTPリクエストごとに method, path, status, duration を
slogで記録 - Recovery — Gin 標準のパニックリカバリ
RAG データフロー
Client
|
v
Chat Completion Request
|
v
Knowledge Service (RAG オーケストレーション)
|-- 1. ユーザクエリ抽出
|-- 2. エンベディング生成 (multi-bert-inference -> 256d ColBERT)
|-- 3. ベクトル検索 (pgvector HNSW ANN) + リランキング (ColBERT MaxSim)
|-- 4. コンテキスト付与
|-- 5. LLM バックエンドへ送信
|-- 6. NATS publish (pipeline.* + telemetry.*) <- fire-and-forget
+-- 7. レスポンス返却
システムトポロジー
NATS JetStream :4222
+----------------------+
| pipeline.* |
| telemetry.* |
+---+----------+--------+
publish ------+ | pull subscribe
(fire & forget) | (durable consumer)
|
+-- agent-gateway :8080 ------+ +-- Dagster daemon -----------------------+
| | | |
| Client Request | | sensor: nats_dagster_chat_persist |
| | | | sensor: nats_dagster_embedding |
| v | | sensor: nats_dagster_retrieve |
| Knowledge Service | | sensor: nats_dagster_compose |
| |-- embed (multi-bert) | | sensor: nats_dagster_flow_lineage |
| |-- vector search (pg) | | sensor: nats_dagster_tool_call |
| |-- rerank (ColBERT) | | | |
| |-- LLM inference -------|-->-| vLLM / llama.cpp / LM Studio |
| | | | | |
| |-- NATS pub: pipeline.* | | v |
| |-- NATS pub: telemetry.*| | RunRequest -> Dagster job 実行 |
| +-- Response | | |-- chat persist -> pg |
| | | |-- embedding event -> pg |
| LLM Backends | | |-- retrieve event -> pg |
| |-- vLLM :8000 | | |-- compose event -> pg |
| |-- llama.cpp :8081 | | |-- flow lineage -> pg |
| +-- LM Studio :1234 | | +-- tool call -> pg |
| | | |
+-----------------------------+ +-----------------------------------------+
|
+------------+
| pull subscribe
v
+-- Vector (Rust) ----------------------+
| source: nats (telemetry.*) |
| |-- sink: Prometheus exporter |
| +-- sink: Loki (CorrelationID) |
+--------------------------------------+
NATS イベント設計
同一のCorrelationIDで2つの独立したパスを通る。
Pipeline (Dagster sensor → ジョブ実行):
| トピック | Dagster ジョブ |
|---|---|
pipeline.knowledge.chat.persist | knowledge_chat_persist + knowledge_chat_pair_materialize |
pipeline.knowledge.embedding | knowledge_embedding |
pipeline.knowledge.retrieve | knowledge_retrieve |
pipeline.knowledge.compose | knowledge_compose |
pipeline.knowledge.flow.lineage | knowledge_flow_lineage |
pipeline.knowledge.tool_call | knowledge_tool_call |
Telemetry (Vector → Prometheus / Loki):
| トピック | 内容 |
|---|---|
telemetry.knowledge.chat | モデル, バックエンド, トークン使用量, ストリーミング有無 |
telemetry.knowledge.embedding | モデル, 入力数, 次元数 |
telemetry.knowledge.retrieve | TopK, ヒット数, スコア |
telemetry.knowledge.tool_call | 関数名, モデル |
JetStreamストリーム設定:
PIPELINE— subjects:pipeline.>, retention: limits, max-age: 72h, storage: fileTELEMETRY— subjects:telemetry.>, retention: limits, max-age: 24h, storage: file
Dagster Assets と Jobs
Dagster側はasset materialization + sensorパターンで構成されている。
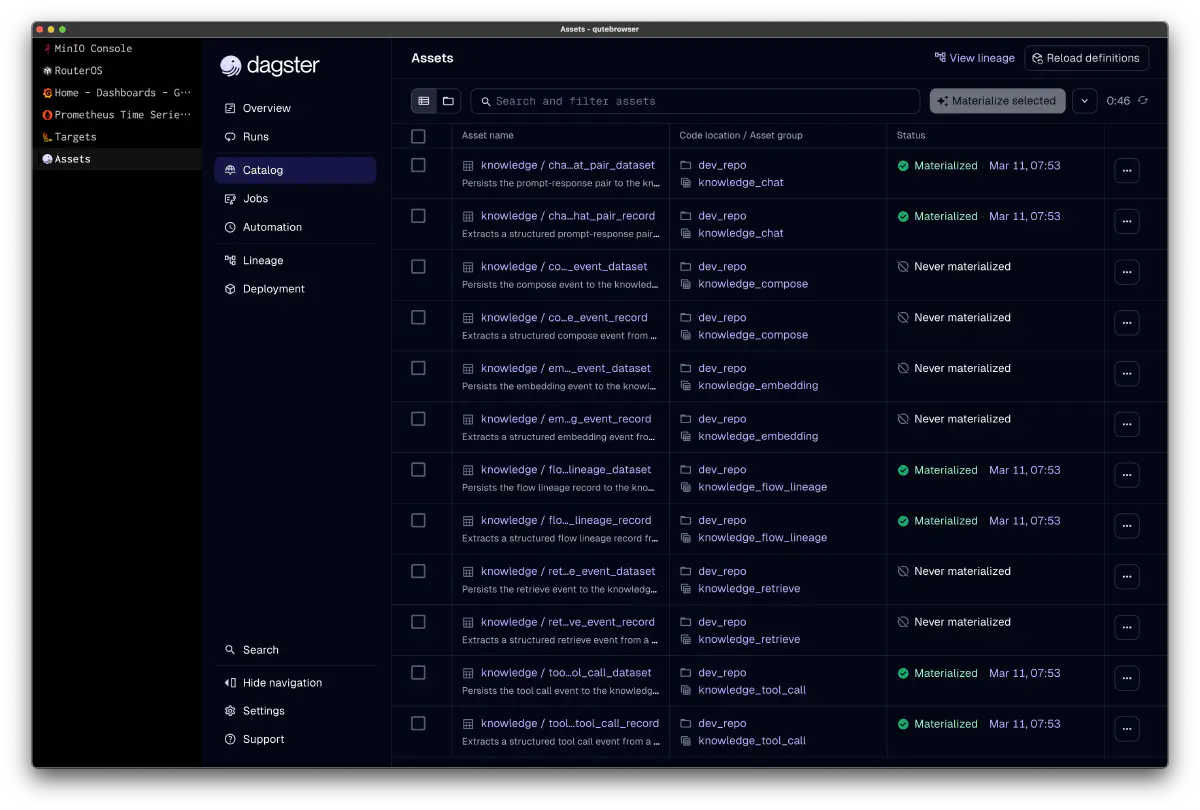
各sensorがNATS JetStreamからpull subscribeし、イベントを検知するとRunRequestを発行してジョブを直接実行する。GraphQL APIを経由しない。
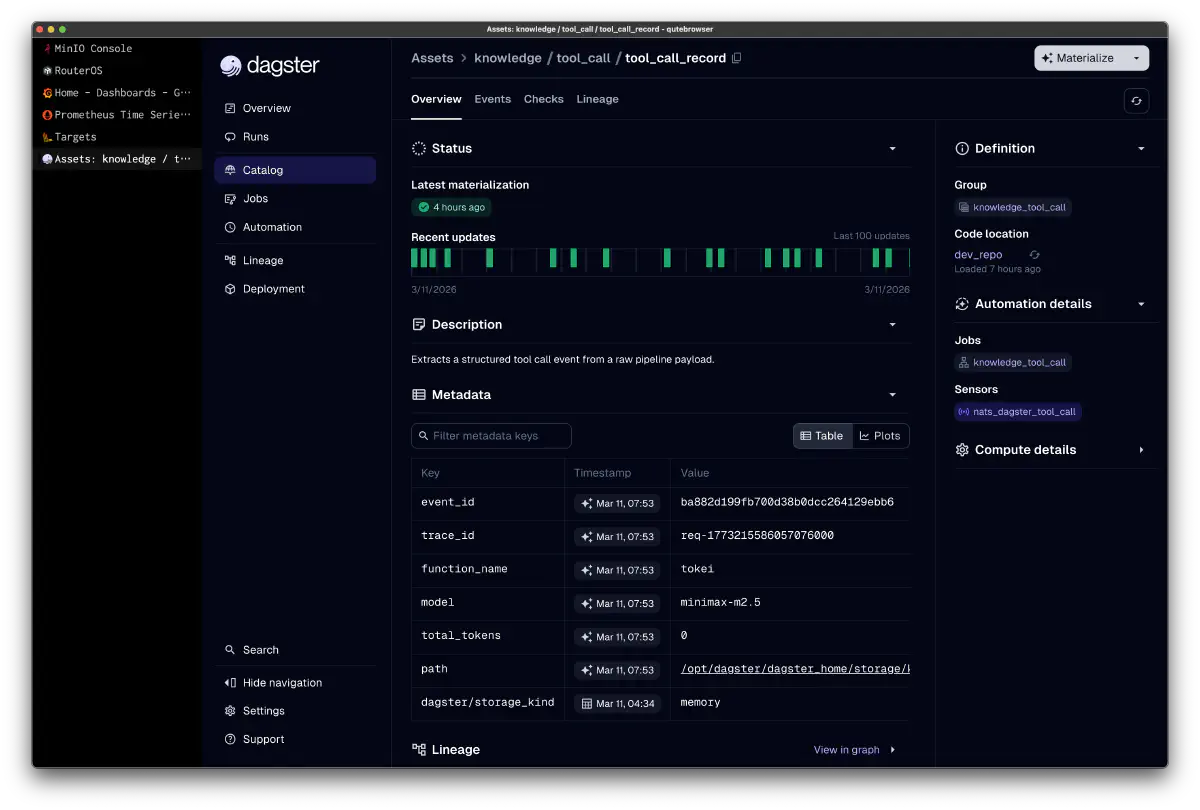
tool_call_recordの例: function_name: tokei, model: minimax-m2.5 — LLMがどのツールをどのモデルで呼び出したかをイベントとして記録し、Dagsterのlineageで追跡可能にしている。
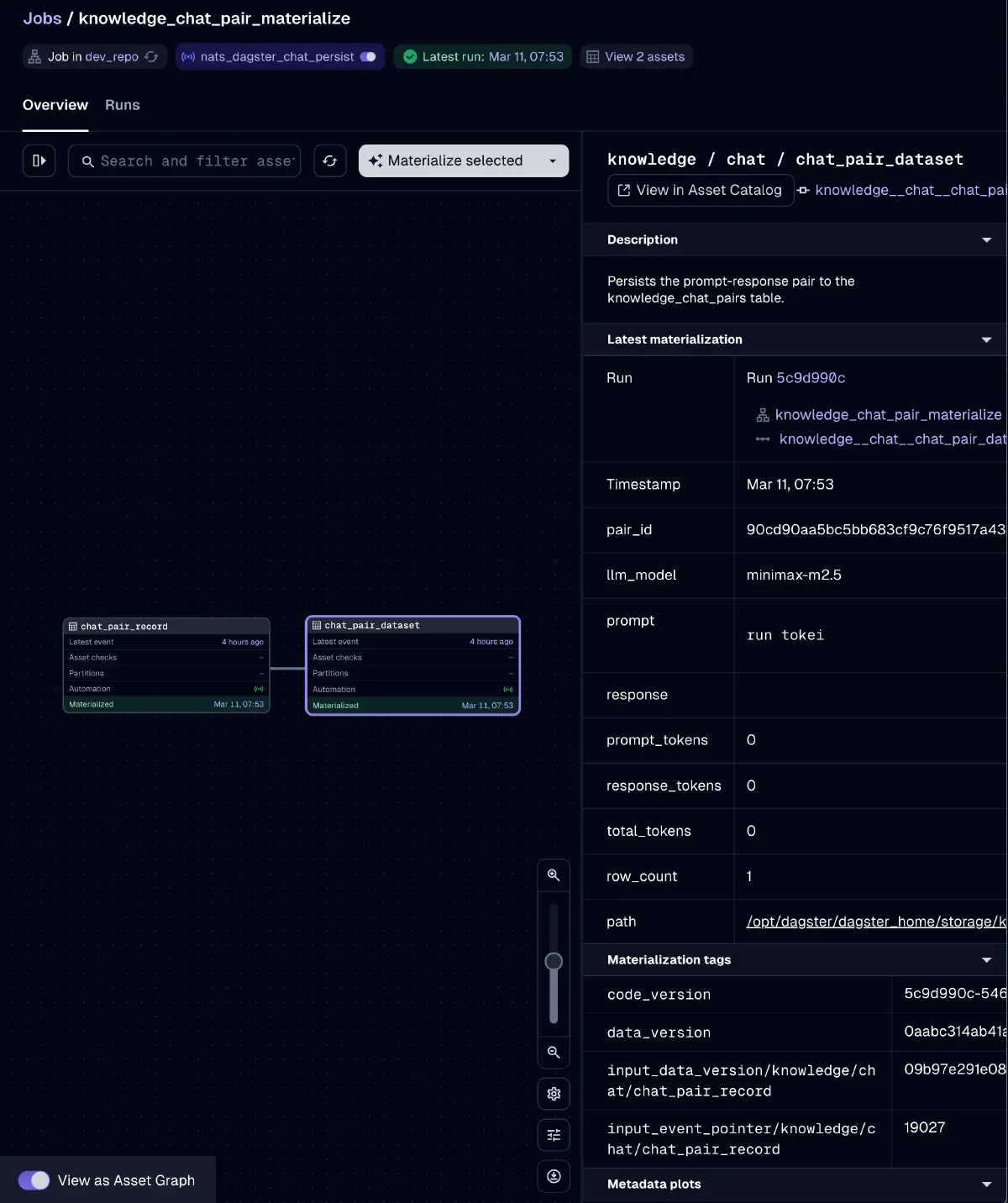
knowledge_chat_pair_materialize ジョブはchat_pair_recordとchat_pair_datasetの2つのアセットをmaterializeする。prompt-responseペアをPostgreSQLに永続化し、将来のfine-tuning用データセット構築の原料とする。
devstack コンテナ構成
podman-compose で全ミドルウェアをrootlessコンテナとして起動する。
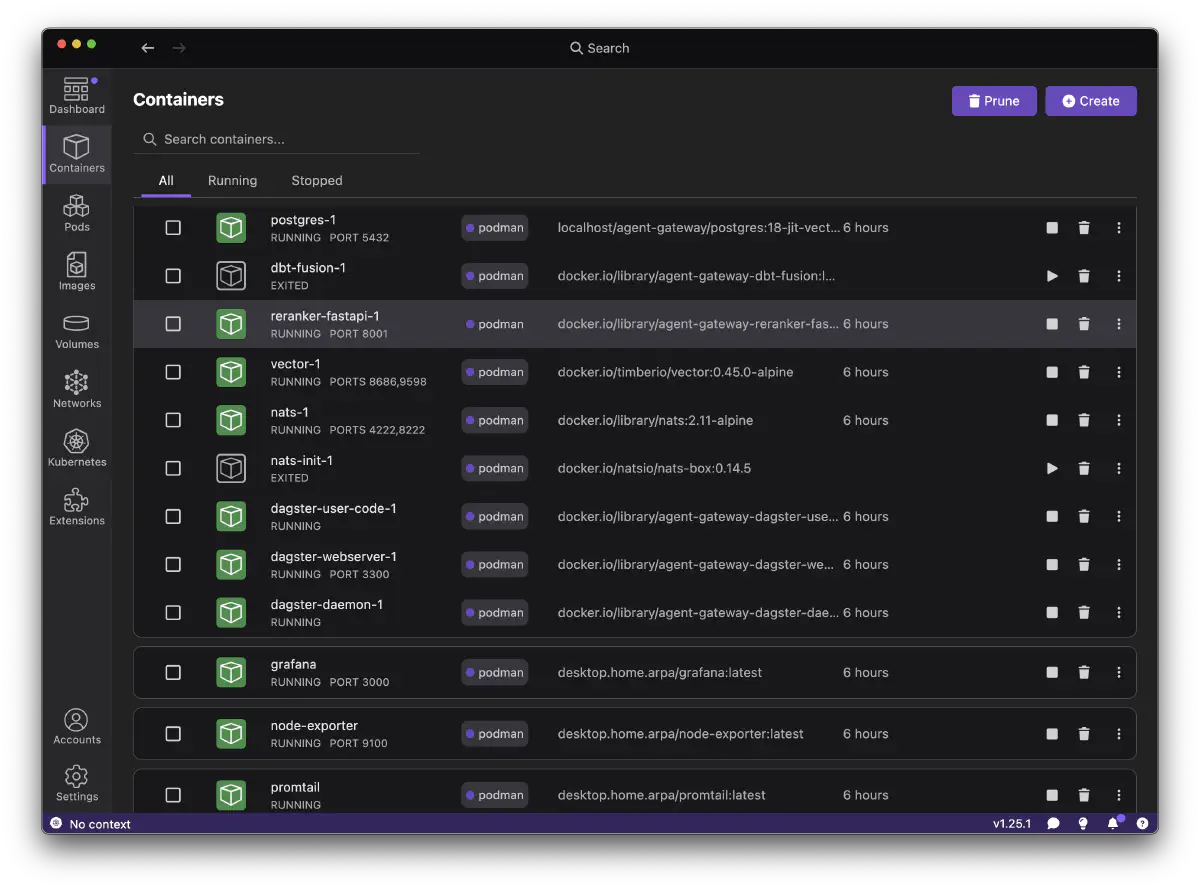
| サービス | イメージ | ポート | 役割 |
|---|---|---|---|
| NATS | nats:2.11-alpine | 4222, 8222 | JetStream メッセージング |
| PostgreSQL | postgres:18-jit-vector | 5432 | pgvector + JIT、agent_gateway / dagster DB |
| Dagster | カスタムビルド | 3000 | Webserver + Daemon + User-code gRPC |
| Vector | timberio/vector:0.45.0-alpine | 8686, 9598 | NATS テレメトリ → Prometheus/Loki |
| multi-bert-inference | Rust (Axum) + ONNX Runtime | 3001 (HTTP), gRPC | ColBERT embed (256d) + rerank (64d MaxSim) |
Lakehouse profile(Phase 2用、明示的に起動):
- Nessie (19120) — Iceberg メタデータカタログ (git-like ブランチ)
- Trino (8081) — Iceberg カタログ付き SQL エンジン
- dbt-fusion — dbt CLI コンテナ
3ホスト ネットワークトポロジー
NATSをgatewayと同居させ、左右どちらも1 hop以内に収める。
+-- storage server (observability) --+ +-- desktop mac (gateway) ----------+ +-- compute server (inference) ------+
| | | | | |
| Prometheus <-- scrape --------------|-- :9598 (Vector exporter) | | vLLM :8000 (GPU inference) |
| Grafana | | | | llama.cpp :8081 |
| Loki <-- push ----------------------- Vector (nats source) | | |
| Vector (aggregator) | | | | | Dagster :3000 |
| |-- nats source -------------------- NATS JetStream :4222 <---------|--|---- daemon sensor (pull subscribe) |
| |-- -> Loki sink | | ^ publish | | |-- webserver |
| +-- -> Prometheus exporter | | | (fire-and-forget) | | |-- daemon (sensor -> job) |
| MinIO :9000 | | | | | +-- user-code gRPC |
| | | agent-gateway :8080 | | |
| | | |-- proxy API | | PostgreSQL 18 :5432 |
| | | | (OpenAI/Anthropic/ | | +-- pgvector (ANN + full-text) |
| | | | Responses) | | |
| | | |-- knowledge orchestrator | | multi-bert-inference :3001 |
| | | +-- NATS pub ----------------|---> pipeline.* + telemetry.* |
| | | | | |
| | | LM Studio :1234 (CPU inference) | | Trino :8080 |
| | | | | Nessie :19120 |
+------------------------------------+ +-----------------------------------+ +-------------------------------------+
| ホスト | 役割 | 主要サービス | 稼働 |
|---|---|---|---|
| storage server | Observability + オブジェクトストレージ | Prometheus, Grafana, Loki, Vector, MinIO | 24/7 |
| desktop mac | Gateway + メッセージング | agent-gateway, NATS JetStream, LM Studio | 作業時のみ |
| compute server | GPU 推論 + データ基盤 | vLLM, llama.cpp, Dagster, PostgreSQL, Trino | 作業時のみ |
NATSをdesktop macに配置した理由: gateway(最大のpublisher)と同居でpub latencyゼロ。desktop/computeは同時に起動・停止する前提なのでNATSの可用性は問題にならない。storage serverだけが常時稼働し、Vectorは接続断を検知して自動再接続する。
データ保管戦略
データの性質に応じてPostgreSQL (pgvector) と Iceberg (Parquet) を使い分ける。
PostgreSQL (pgvector) Iceberg (Parquet via Trino/Nessie)
-------------------- -----------------------------------
特性 構造化 + ベクトル検索 ファイル指向 + 大量蓄積
クエリ WHERE + ANN (近傍探索) SQL JOIN + time-travel
更新パターン UPSERT (行単位) append-only (immutable Parquet)
バージョン管理 なし (行履歴は自前) Nessie ブランチ + Iceberg snapshot
Phase 1(リアルタイム)では全データがPostgreSQLに直書きされる。Phase 2以降でDagster batchがPGからParquet変換 → Iceberg appendし、dbt-fusionで分析用データセットを構築する設計。
PostgreSQL スキーマ
- document_chunks — 256次元ColBERTエンベディング + HNSW vectorインデックス
- chat_history — correlation_id別の会話履歴
- rerank_scores — クエリ × ドキュメント × モデル別のリランクスコア
- api_responses — Responses API 永続化
注意事項
- desktop mac / compute server 停止時はNATSも落ちるが、JetStreamの永続化データはdesktop macのディスクに保持され、次回起動時に未消費メッセージから再開する
- Vectorは接続断を検知して自動再接続するが、NATS停止中のtelemetryイベントは失われる(pipeline側はJetStreamのdurable consumerで保護される)
- PostgreSQL 18のJIT有効化は
shm_size: 4gbの設定が前提。不足するとOOM killのリスクがある
検証
- Dagster UIでasset materialization状態を確認: chat_pair, flow_lineage, tool_callが正常にMaterialized
- NATSモニタリング (
:8222) でstream状態とconsumer lagを監視 - Vector exporter (
:9598) → Prometheusでtelemetryメトリクスの到達を確認 - インテグレーションテスト:
go test -tags=integration ./internal/infra/integration ./internal/domain/pipeline
次のアクション
現在Phase 1(リアルタイム基盤)が稼働中。以降のロードマップ:
| Phase | 内容 | 状態 |
|---|---|---|
| 1 | gateway → NATS → Dagster/pg, Vector → Prometheus/Loki | 稼働中 |
| 2 | pg → Parquet → Iceberg バッチ, dbt-fusion 加工 | devstack済 |
| 3 | MCP server tool 定義, Trino クエリ tool, 仮説検証自動化 | 未着手 |
| 4 | fine-tuning パイプライン, MOE expert pruning, 合成データ増幅 | 未着手 |