homelab インフラ再設計 -- PostgreSQL の storage/compute 分離と devstack 整備
homelab 3台構成で PostgreSQL を on-demand GPU box から 24/7 Mac Mini に移行した設計判断の記録。pgvector 統合維持の判断、devstack の macOS 対応、バックアップ symlink 設計まで。

この記事について
homelab は3台で構成している。storage.home.arpa(Mac Mini 2018, 24/7稼働)、desktop.home.arpa(メイン開発機)、compute.home.arpa(GPU box, on-demand)。この構成で PostgreSQL がどこに居るべきか、という問題に向き合った話と、その周辺で片付けた devstack 整備の記録。
PostgreSQL がなぜ compute に居たのか
もともとの構成はこうだった:
storage.home.arpa (Mac Mini 2018, Ubuntu, 24/7)
-- MinIO, Prometheus, Loki, Vector
desktop.home.arpa
-- familiar (agent-gateway), NATS
compute.home.arpa (GPU box, on-demand)
-- PostgreSQL, Dagster, MLflow, vLLM, llama.cpp
PostgreSQL が compute に居たのは、Dagster と MLflow が同じホストで直接アクセスするのが楽だったから。Docker Compose の中でサービス名 postgres をそのままホスト名として使える。初期構築のときは深く考えずにそうした。
問題は、compute が on-demand 起動だということ。永続性が重要なメタデータを管理する PostgreSQL が、必要なときだけ起動するマシンに載っている。compute を再構築するたびにデータのことを気にしなければならない。それに、ちょっと DB の中身を確認したいだけのために GPU box を起動するのが地味に面倒だった。desktop から dbt でデータを操作したいときも compute が起きていないと始まらない。
移行先の判断: storage に集約する
storage.home.arpa に PostgreSQL を移す案を検討した。懸念は Mac Mini 2018(i7-8700B, 16GB RAM)のスペックで捌けるかどうか。
まずデータの性質を整理した。PostgreSQL が抱えているのは3つの DB:
agent_gateway: アプリの主 DB(document_chunks, chat_history, session, lineage)dagster: Dagster 実行メタデータmlflow: MLflow 実験トラッキング
これらは全部メタデータ + テキスト + ベクトルで、実体ファイル(Parquet, artifacts)はすでに MinIO に置く設計になっている。メタデータ専用なら I/O は軽い。pg_dump で数 MB に収まるサイズ感だ。
全体のデータアーキテクチャを整理するとこうなる:
| 保管先 | 役割 | データ例 |
|---|---|---|
| PostgreSQL (storage) | メタデータ + 集計 + pgvector | session, lineage, embeddings, dbt materialized |
| MinIO (storage) | 実体ファイル | Parquet, Iceberg data, MLflow artifacts |
| DuckDB (compute) | 変換・集約ワークベンチ | Dagster パイプライン中間データ |
DuckDB は揮発的な作業台。消えても Dagster job で再生成できるキャッシュ。正本は PostgreSQL と MinIO にある。
データ設計がフラットであれば、負荷をかけてもボトルネックにはなりづらい。PostgreSQL が 24/7 で動いていると、desktop マシンから dbt でいつでもデータを操作できるのが想像以上に快適だった。
pgvector を分離するか問題
移行にあたって、pgvector を PostgreSQL から分離して Qdrant を compute に置く案も検討した。
Qdrant を使えば HNSW 検索を GPU box のリソースで回せる。compute の CPU/メモリを専有できるし、pgvector より高 RPS に対応できる。ただし問題がいくつかある:
document_chunksテーブルの二重管理が発生する(PG にテキスト + メタデータ、Qdrant にベクトル)- Go アプリのリポジトリコードを Qdrant client 用に書き換える必要がある
- compute が on-demand なので、embedding 検索したいときに compute が落ちていると詰む
最後の点が決定的だった。外部 API(Gemini 等)を使うときは compute なしで embedding 検索したい場面がある。
pgvector に統合したままのメリットを改めて確認:
- embedding + メタデータ + chat_history が同一 DB で JOIN できる
correlation_idで横断クエリが1発- 二重管理なし
- バックアップ1箇所
RPS も冷静に見直した。embedding 検索はユーザクエリ1回につき1回の HNSW 検索。人間がクエリを打つ速度で 18 RPS なんて出ない。同時に aichat + Zed を使っても現実的には RPS 2-5。18 RPS は NATS 経由の Dagster イベントの話で、それは metadata INSERT だから軽量。
結論: pgvector を PostgreSQL に統合したまま storage に移行。問題が出たら ef_search チューニング -> shared_buffers 調整 -> 最終手段として Qdrant@compute、という段階的フォールバック。
実装: Go config と compose の書き換え
Go 側の変更は最小限で済んだ。config.go の DSN 導出が COMPUTE_HOST から組み立てる設計だったので、POSTGRES_HOST を新設して分離するだけ:
// internal/config/defaults.go
const DefaultPostgresHost = DefaultStorageHost // storage.home.arpa
// internal/config/config.go
postgresHost := envOr("POSTGRES_HOST", DefaultPostgresHost)
ユーザも変更:
| 用途 | ユーザ | DB |
|---|---|---|
| アプリケーション | agent | agent_gateway |
| インフラメタデータ | system | dagster, mlflow |
| 管理 | ksh3 | 全 DB |
compute-compose.yaml は大幅に再構成した:
# 削除: postgres サービスブロックと postgres-data volume
# MLflow: backend-store-uri を storage に向ける
mlflow:
environment:
BACKEND_STORE_URI: postgresql://system@storage.home.arpa:5432/mlflow
# Dagster: 環境変数で PG ホストを注入
dagster-webserver:
environment:
DAGSTER_PG_HOST: storage.home.arpa
DAGSTER_PG_USER: system
POSTGRES_DSN: postgresql://agent@storage.home.arpa:5432/agent_gateway
# 全サービスに restart: on-failure を追加(PG 接続リトライ用)
depends_on: postgres を全部削除し、代わりに restart: on-failure で PG 起動待ちをカバー。Dagster も MLflow も接続リトライを内蔵しているので、storage 上の PostgreSQL が起動していれば自動で繋がる。
storage 側の PostgreSQL は systemd quadlet で管理。イメージは postgres:18-trixie ベースで JIT + pgvector 拡張を有効にしたカスタムビルド。Mac Mini 向けにチューニング:
shared_buffers = 2GB # 16GB RAM を他サービスと共有
effective_cache_size = 6GB
work_mem = 64MB
shm_size = 2GB # compute の 4GB から削減
初期化スクリプトは .sql から .sh に変更し、ユーザ作成・DB 作成・pgvector 拡張・権限設定を一括で実行する形にした。
go build ./... # 問題なし
devstack の macOS 対応
PostgreSQL 移行と並行して、homelab/desktop-containers/compose.yaml を macOS で動くよう修正した。
Linux 専用の設定がいくつか混ざっていた:
| 問題 | 修正 |
|---|---|
node-exporter の privileged: true + pid: host | 削除(macOS VM では意味がない) |
/:/host:ro,rslave マウント | rslave 除去(macOS Docker Desktop 非対応) |
version: "3.9" | 削除(deprecated) |
/private/var/log パス | macOS では /var/log が symlink |
Grafana や Prometheus は macOS でもそのまま動くので変更なし。node-exporter は macOS では機能が制限されるが、compute と storage のメトリクスは正常に取れるので実用上の問題はない。
バックアップと symlink の設計
compute-containers/runtime/backup/backup-runner.sh での symlink 重複リスクを確認した。
BACKUP_ROOT=/srv/persistent/backup
WORKSPACE_ROOT="${WORKSPACE_ROOT:-/mnt/data/workspace}"
/opt -> /mnt/data/workspace の symlink を作った場合に二重バックアップにならないか。結論: ならない。backup-runner.sh は WORKSPACE_ROOT を直接指定しており、/opt を経由しない。tar はデフォルトで symlink を追跡しない(symlink 自体をアーカイブする)。ただし --follow-symlinks を使ったり、別のバックアップ処理が /opt を対象にする場合は注意。
ctree チェックポイントと argus
この時期に argus プロジェクトで ctree の create_checkpoint ツールも追加した。get_revs は diff 表示用だが、作業の節目ごとにチェックポイントファイルを高頻度で生成する単純なアクセサが欲しかった。
作業中に ctree のバグも見つかった。get_affected と get_depends がシンボル参照を正しく検出できないケースがある:
ctree.get_affected(name="reject_removed_paging_args") -> 参照なし(実際は dispatch から呼ばれている)
ctree.get_depends(dep="reject_removed_paging_args") -> "no dependencies found"
これは別セッションで修正した。
familiar の最新アーキテクチャでは Application Layer が追加されていて、エージェントモード時のオーケストレーション責務(ツール実行、ワークスペース管理、MCP サーバー管理)を担う層として設計されている:
Transport Layer (Gin)
|
+--- (agent mode) ---> Application Layer [internal/agent/]
| +- loop.go orchestration loop
| +- orchestrator_runtime.go
| +- intent_packet.go
| +- tools.go MCP tool definitions
| +- executor/ file, git, shell
| +- mcp/ MCP server management
| +- workspace/ session management
v |
Domain Layer <-----------------------+
通常の API リクエストは Transport -> Domain -> Infra だが、エージェントモードでは Transport が Application Layer を通じてオーケストレーションループを回す。
移行後の構成
最終的な3台構成:
storage.home.arpa (Mac Mini 2018, Ubuntu, 24/7)
-- PostgreSQL :5432 (pgvector, 3 DBs)
-- MinIO :9000
-- Prometheus :9090
-- Loki :3100
-- Vector
desktop.home.arpa
-- familiar :8080
-- NATS :4222
-- multi-bert-inference :50051
-- Grafana :3000
compute.home.arpa (GPU box, on-demand)
-- Dagster :3300
-- MLflow :5050
-- vLLM :8000
-- llama.cpp :8081
-- DuckDB (パイプライン内ワークベンチ)
永続データの正本が storage に集約された。compute は純粋に計算リソースとして使い、落としても再構築してもデータは失われない。
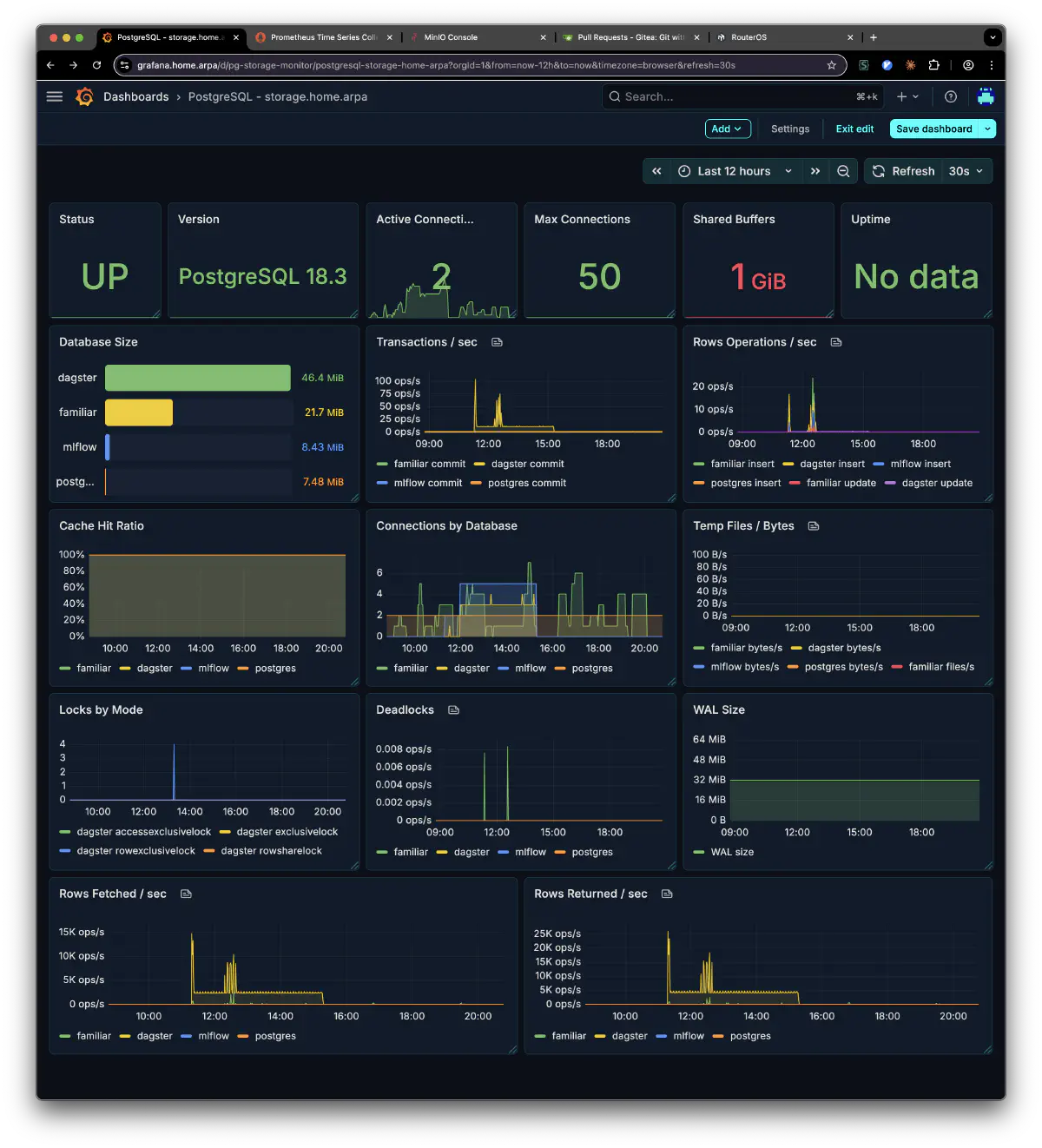
移行後の PostgreSQL の状態。familiar, dagster, mlflow, postgres の4 DB が storage 上で動いている:
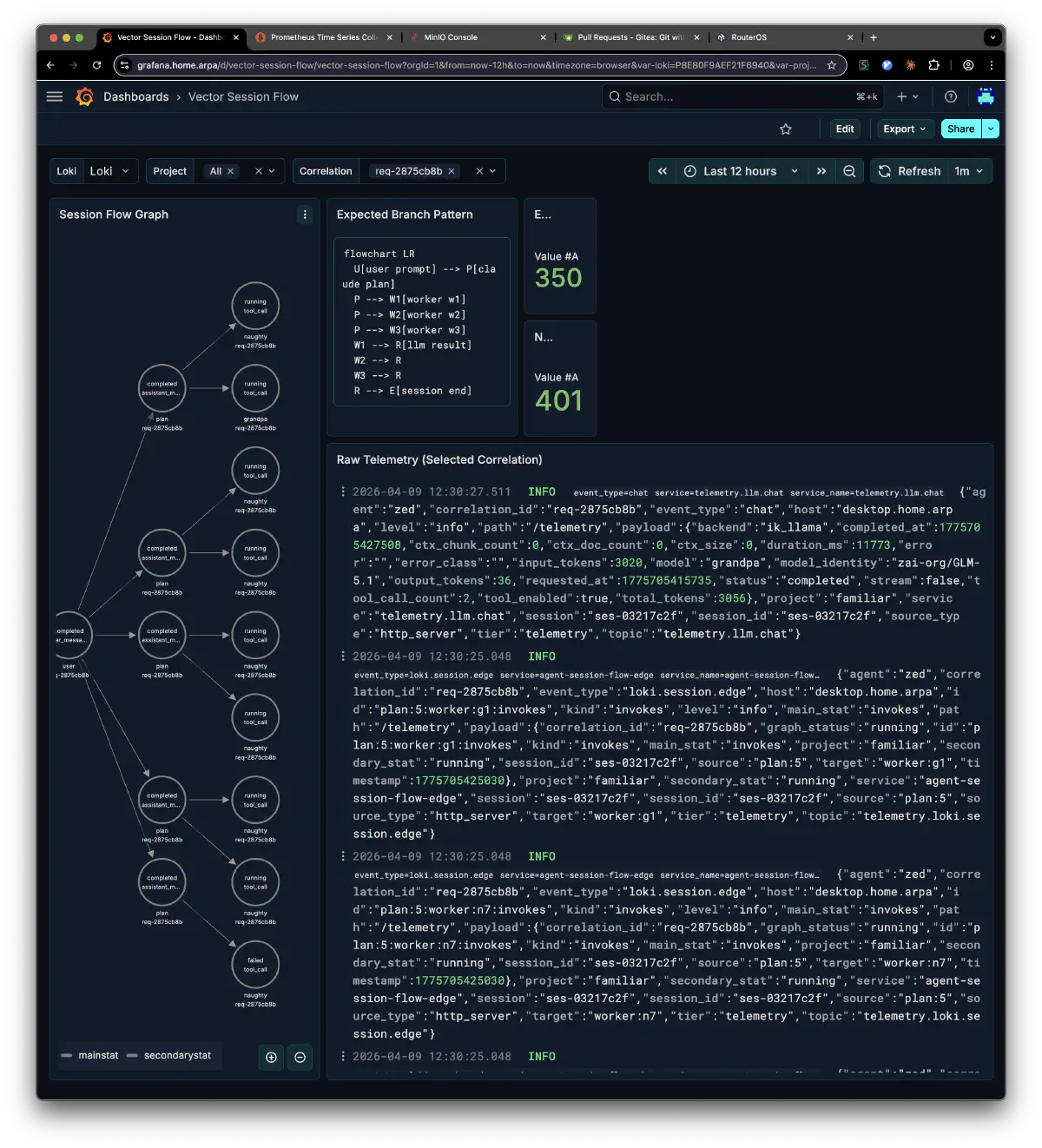
familiar のセッションフローもテレメトリとして可視化できるようになった。correlation_id で一連のリクエストを追跡できる:
storage に集約したことで restic のバックアップ先としてもきれいにまとまった。各ノードからのバックアップ集積所が1箇所に収まる。サービス数はそれなりに多いが、ツール関連はほぼ Rust と Go で実装しているので CPU 負荷もメモリ使用量も全く問題になっていない。
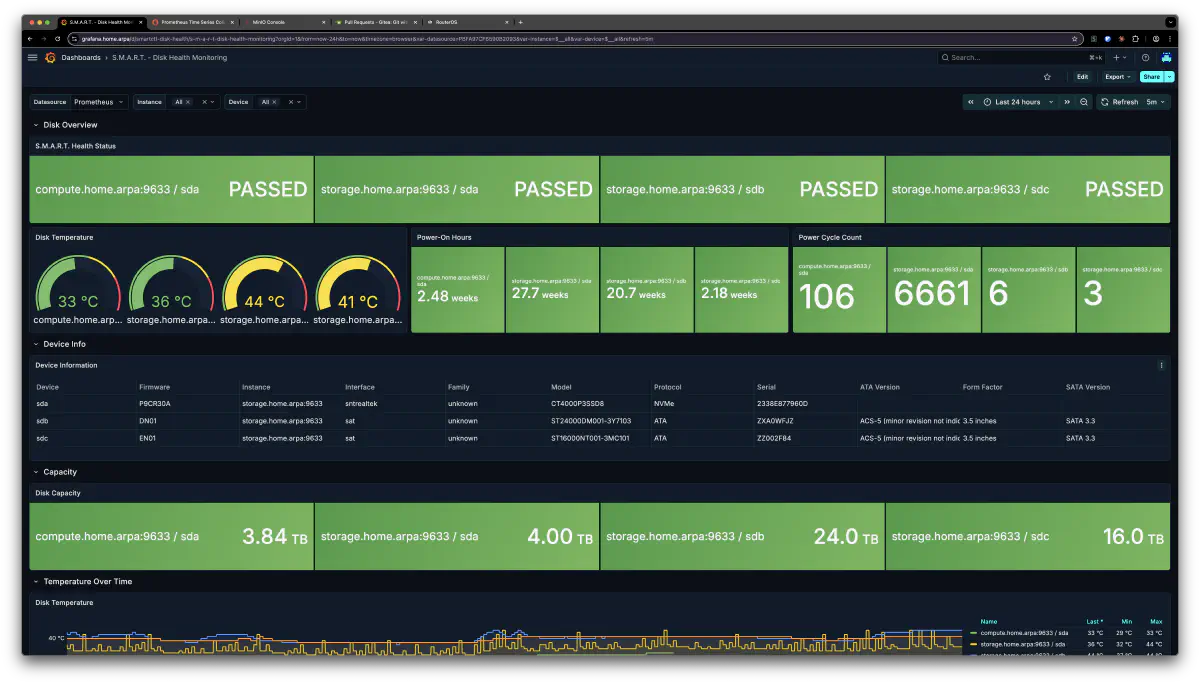
この storage サーバーはじゃんぱらで4万円くらいで手に入れた Mac Mini Late 2018 の 2TB モデルだ。購入時に SMART を確認したら Power-On Hours がほぼゼロ、全く使った形跡がない掘り出し物だった。ubuntu-minimal に OS を入れ替えて、今は 24/7 で酷使している。