DeepSeek-V4-FlashをDwarfStar4で2ノード起動し、オーケストレーション
RTX PRO 6000 Blackwell Max-Q 2枚にDeepSeek-V4-Flash IQ2XXSを1ノードずつ載せ、DwarfStar4の2ノード構成でマルチエージェントcodingシステムのオーケストレータ、ワーカーとして分散評価した記録。TG、worker failure、tool call、GPU占有率、tool-call-as-text失敗モードまでまとめる。

ローカルのマルチエージェントcodingシステムで、オーケストレータ役のモデルを差し替えながら評価している。最近Step-3.7-Flashを単一モデルのマルチエージェント構成にしたら、思いのほか2段飛びで改善できた。そこで今回はDeepSeek-V4-Flash(IQ2XXS量子化)をDwarfStar4で2ノード起動し、オーケストレーションとコーディングに分散させる構成を試した。
結論から書くと、Step-3.7-Flash、Qwen3.6-27B-EAGLEと比べるとTG31.7-35.8t/sは厳しい印象だった。開発初期は1ショットが10-20分だったのだが、現在は完走するがゆえにTG100でも60-70分かかる。 この長さをマルチエージェント開発でベースにするとPDCAを回すのがつらい。ツールは不安定だが、出力内容はやはり良い印象。オーケストレータ専用なら十分に実用的で、コーディング側をspeculative decodingを効かせた軽量workerと組み合わせるとバランスが良いと思う。
DwarfStar4/DeepSeek-V4-Flashをctx 44kのorchestratorに置き、Qwen3.6-27Bをctx 144kのworkerに置く組み合わせはまあまあ良い。DwarfStar側は最近のcommitを見ると単体モデルでagent化していく方向が進んでいるので、またcommitが増えたタイミングで試したい。
検証の目的
自作のマルチエージェントcodingシステムは、orchestrator/planner/coder/tester/reviewer/integratorという複数ロールを持ち、それぞれにモデルを差し替えられる。orchestratorは1ターンごとに「次に何をやるか」を判断してワーカーへ作業を割り当てる司令塔だ。
orchestratorは生成トークン数より、長いコンテキストでもprefix cacheを安定させることや、ctx windowのローリングでどの程度cache hitを維持しながら意味と構造のバランスを取れるかが大事になる。生成スループットはあるに越したことはないが、workerほど支配的ではない。
構成
| 項目 | 内容 |
|---|---|
| Model | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf |
| Runtime | DwarfStar4 (ds4-server) |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x 2 |
| Node A | PID 5435 / GPU0 / port 8001 |
| Node B | PID 5543 / GPU1 / port 8002 |
| VRAM | 各 95.3 GiB / 95.6 GiB 使用 |
| Host RAM | 各 ~83.5 GB |
| Context | 98304 |
| Balancing | オーケストレーション層で起動した2ノードへ分散 |
quadletはノードごとに--portとGPU割り当てだけを変えた2ユニットを起動している。
[Unit]
Description=familiar orchestrator backend (DwarfStar 4 / DeepSeek V4 Flash) node-a
After=network-online.target
Wants=network-online.target
[Container]
ContainerName=ds4-node-a
Image=registry.home.arpa/dwarfstar4:ad0209f
Pull=always
Network=host
AddDevice=nvidia.com/gpu=0
Volume=/mnt/data/models/.../snapshots/<rev>:/model:ro
Volume=/mnt/data/models/.../kv_cache:/kv
Exec=-m /model/DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf \
--ctx 98304 --host 0.0.0.0 --port 8001 \
--warm-weights --kv-disk-dir /kv/node-a --kv-disk-space-mb 4096 \
--trace /kv/trace.node-a.log
[Service]
TimeoutStartSec=900
TimeoutStopSec=30
Restart=on-failure
RestartSec=30
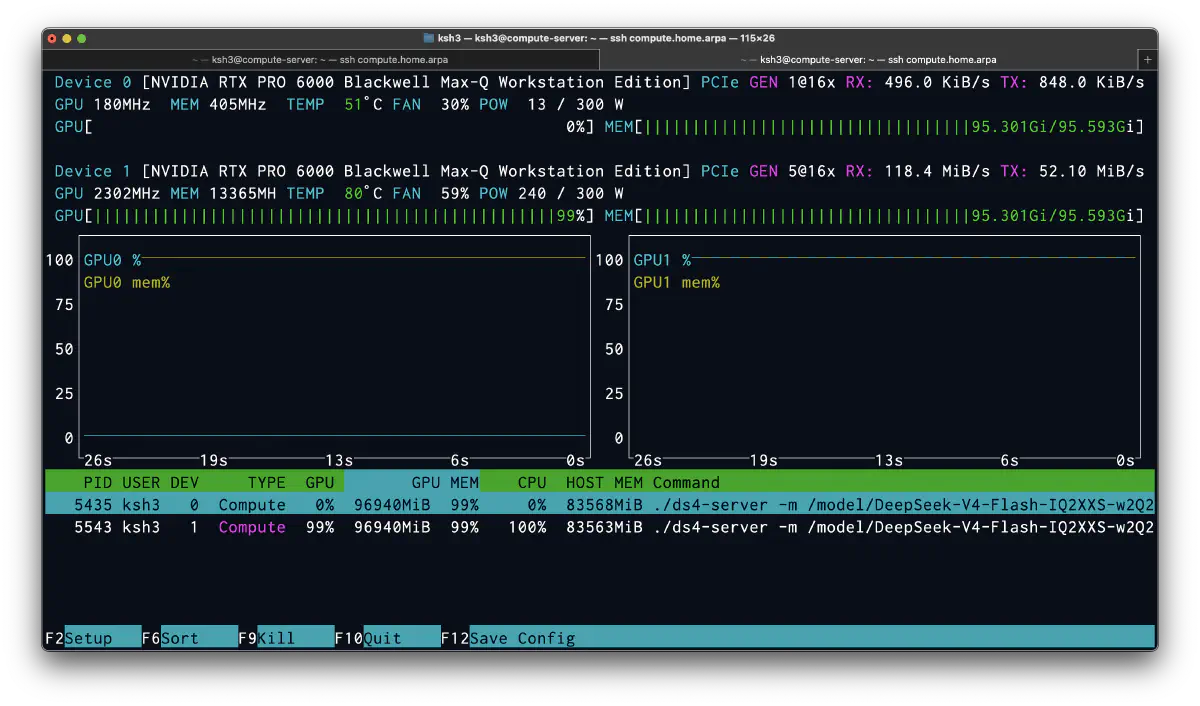
nvtopでは2プロセスがそれぞれ別GPUに張り付き、各ノードが96GB近くまでVRAMを使っていることが確認できた。
実測結果
生成スループット
decodeは概ね31.7-35.8t/sのレンジだった。ツール応答後のTHINKINGフェーズで35.7t/s前後、長い再計画パスでも35.7t/sを安定維持していた。prefillは227-241t/s程度。
GPU占有を見ると、スナップショット時点ではGPU1のみが2302MHz/240W/99%でdecode中、GPU0は180MHz/13Wのアイドルだった。2ノード構成でも、あるターンでは片側だけが走っている瞬間が普通に発生する。オーケストレーションは本質的に逐次依存が強く、ターン内では1ノードに寄りやすい。2ノードの効果は並行ターンや並行ワーカーがあるときに出る。 最近はとくに暑いので、片側を冷やしながら交互に回せるのは耐久性の面では良いと思う。 Broadcomの10GbE NICはlink downしても熱を出すのが恨めしい。最近はRealtekの8127だったかな。あれは熱を出さなくて良いのだけれど、帯域を使い切るとSSH接続が不安定になるのが残念なところ。
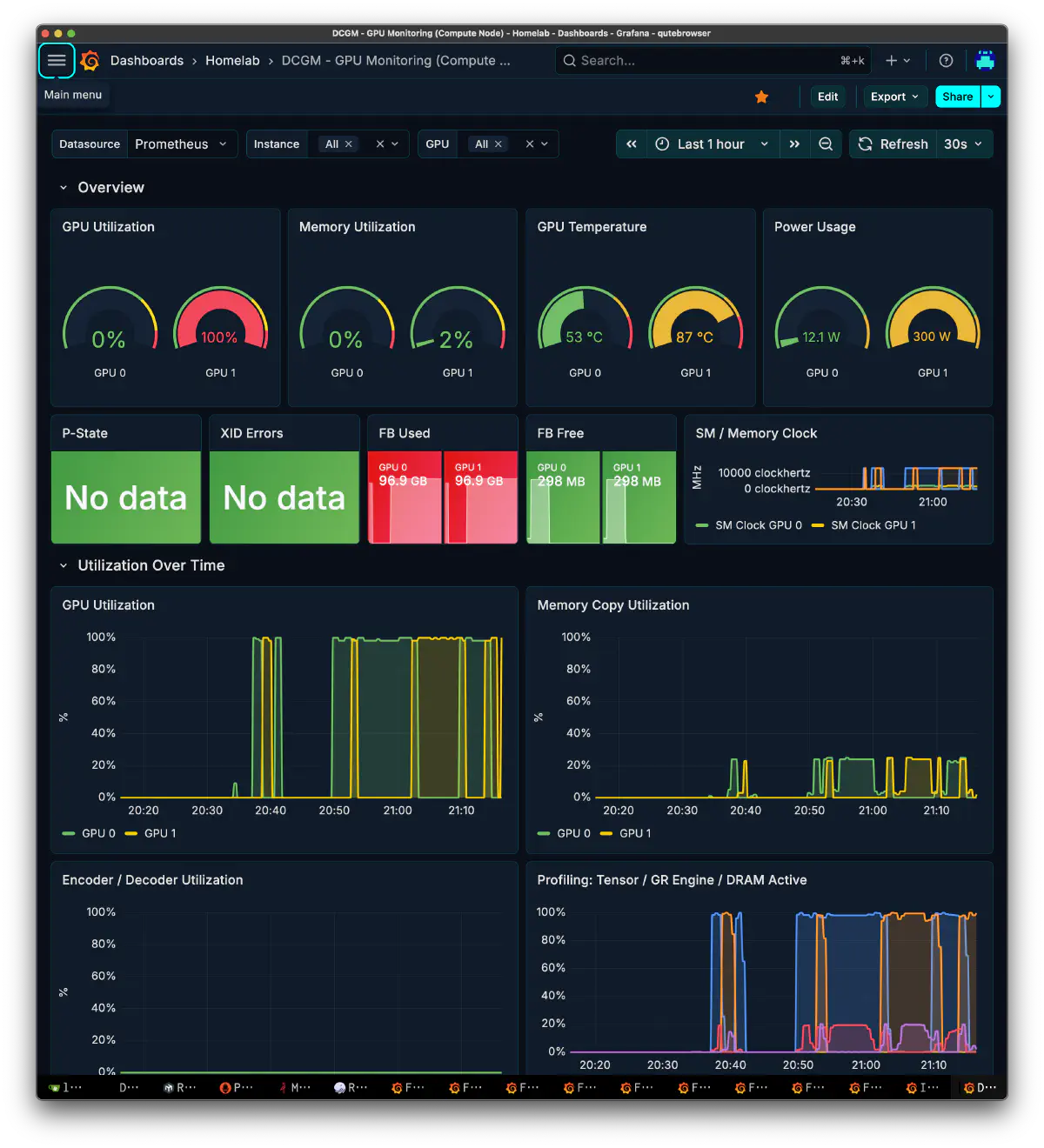
単体worker、つまり実装を長く書く役にこのTGを充てると、1リクエストあたりの待ち時間がそのまま体感に響く。worker用途では厳しい。
オーケストレーション結果
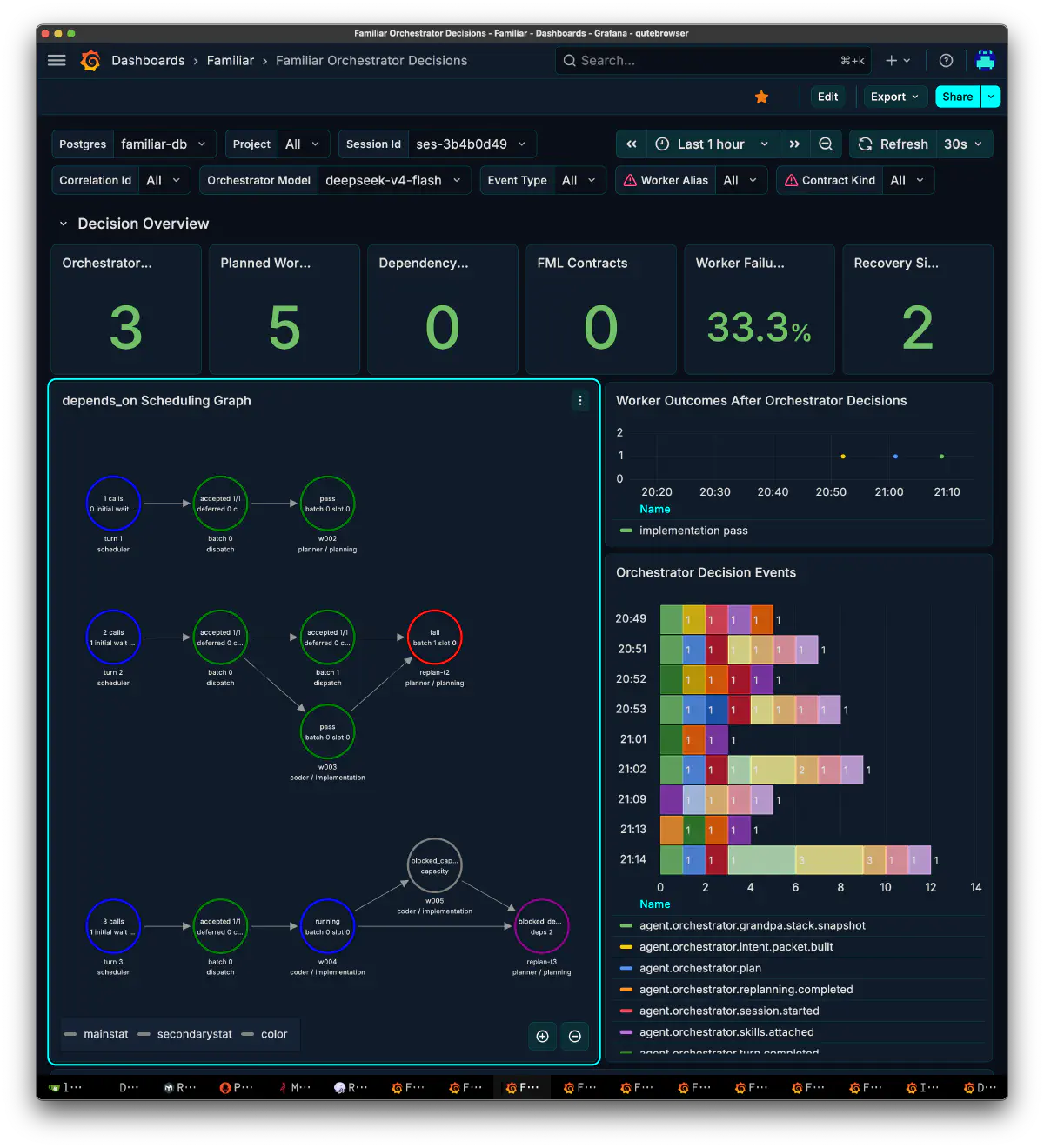
1セッション、3ターンの集計は次のとおり。
| 指標 | 値 |
|---|---|
| orchestrator 判断回数 | 3 |
| planned worker | 5 |
| dependency block | 0 |
| worker failure rate | 33.3% |
| recovery | 2 |
3ターンで5ワーカーを計画。1ワーカーがfailし、再計画が2回走った。replan-t2はfail判定、replan-t3はcapacityと依存関係でブロックされた。司令塔としてのDAG構築、依存解決、再計画ループ自体は破綻なく回っており、ここは想定どおり良好だった。
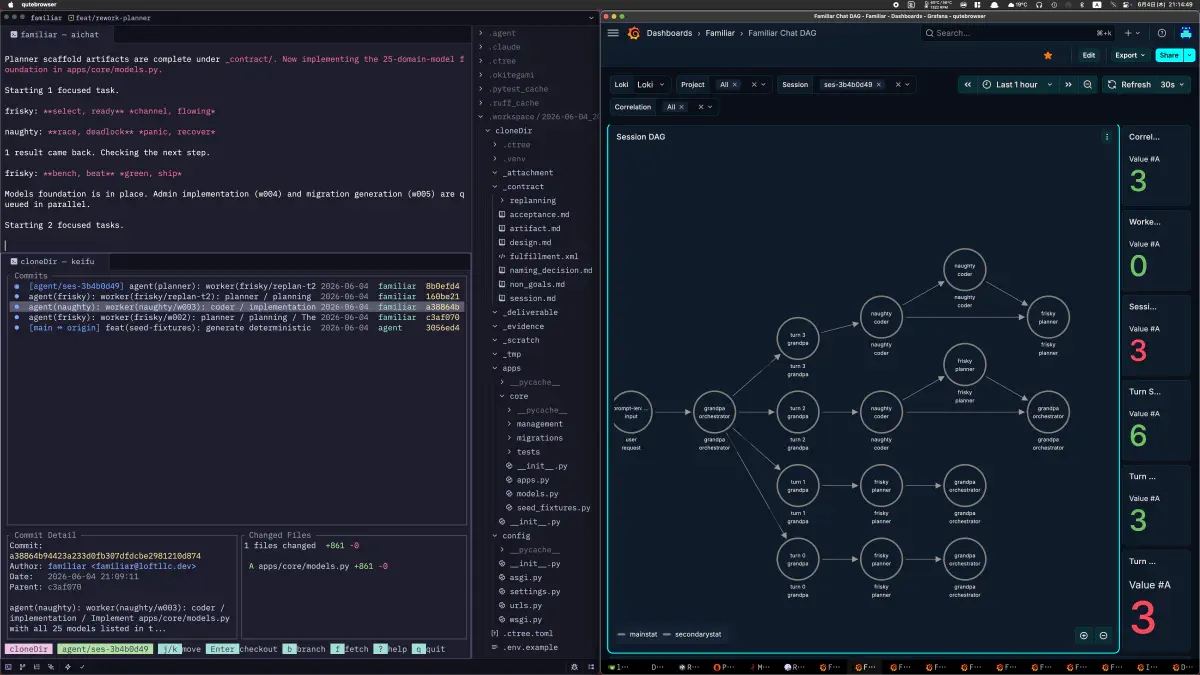
Chat DAGで見ると、user requestからorchestratorがturnごとにplanner/coderへ分岐し、結果が戻ってくる形が確認できた。
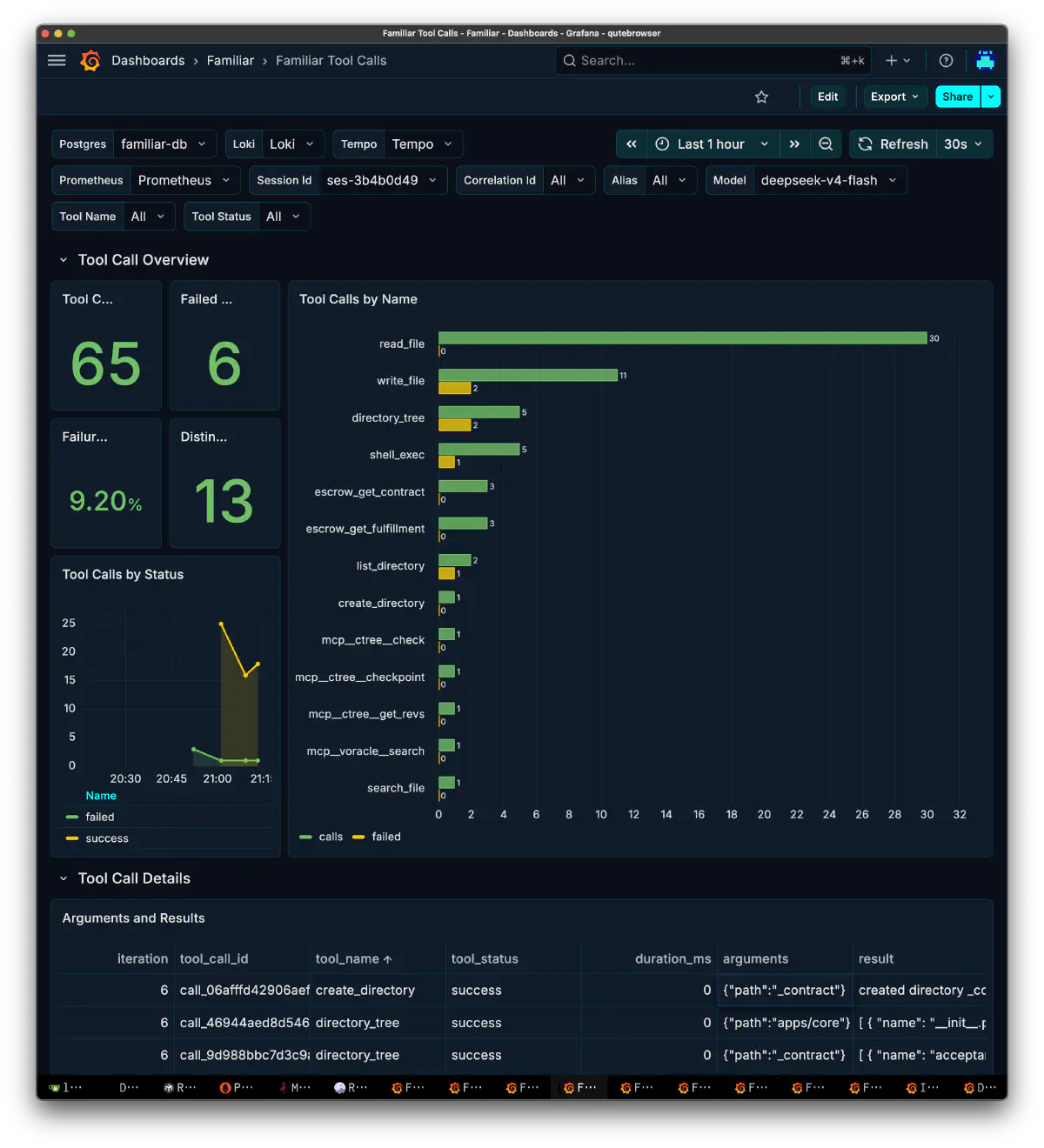
ツール呼び出し
| 指標 | 値 |
|---|---|
| tool call 総数 | 65 |
| failed | 6 |
| failure rate | 9.20% |
| distinct tool | 13 |
内訳はread_fileが支配的で30回、次いでwrite_fileが11回、directory_treeが5回、shell_execが5回だった。失敗はwrite_fileが2回、directory_treeが2回、shell_execが1回、その他が1回。コード生成タスクらしく、読み取りが書き込みの3倍近い比率になっている。
ただし、これはツール自体の呼び出しに失敗したものだけではない。独自のガードルールや論理ロジック上のfailなど、偽陽性も含まれている。失敗率というより、どのくらいcallしているかを見るくらいがよい。
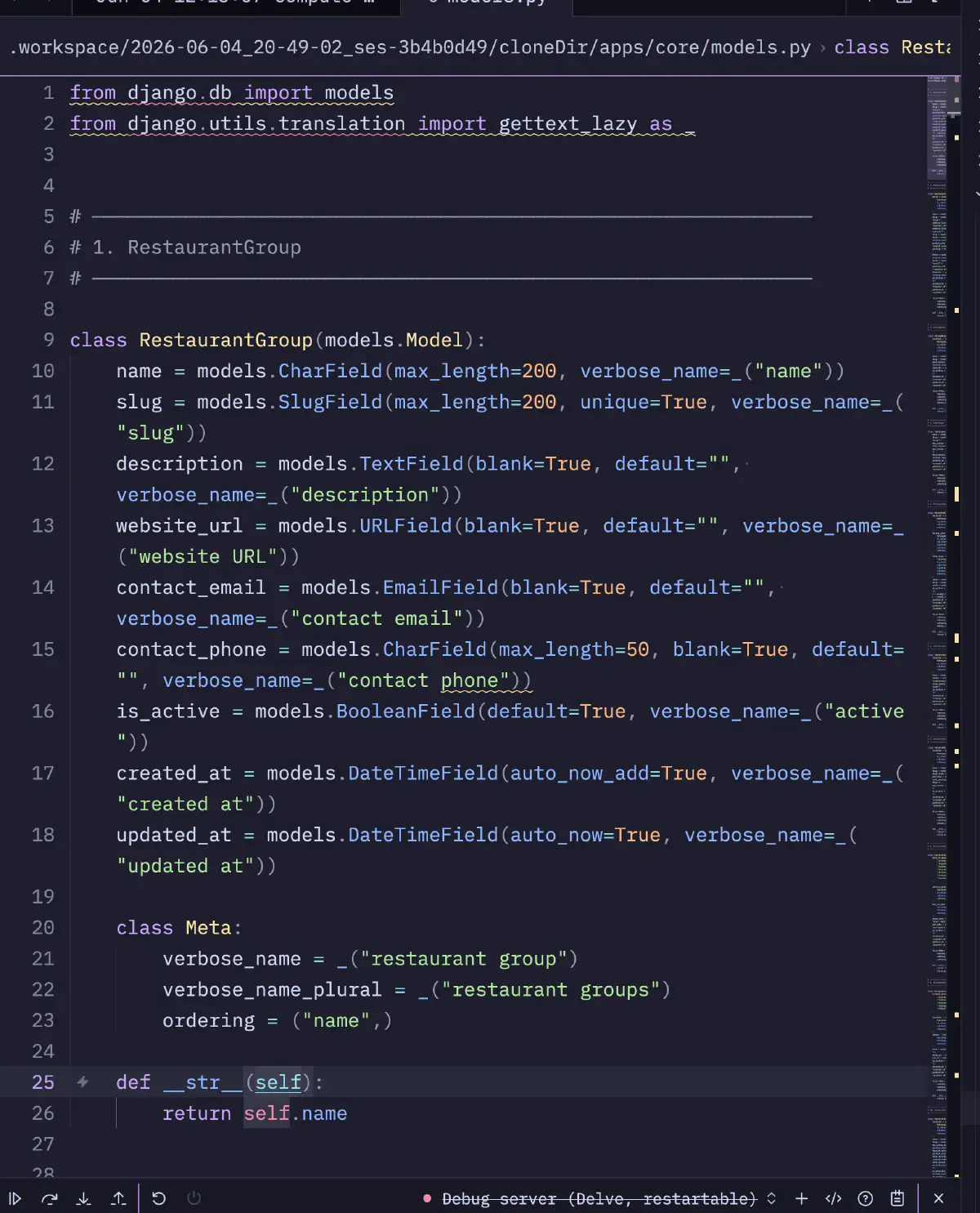
実際に生成された成果物
「司令塔として回った」だけでは記事にならないので、実際にワーカーが生成したコードも確認した。今回のタスクはDjangoの25ドメインモデル基盤、apps/core/models.pyをスキャフォールドから実装するものだった。コミットa38864bとして1ファイルにまとまり、差分は+861 -0。
そのうちモデル1つ目のRestaurantGroupを抜粋する。
from django.db import models
from django.utils.translation import gettext_lazy as _
# ──────────────────────────────────────
# 1. RestaurantGroup
# ──────────────────────────────────────
class RestaurantGroup(models.Model):
name = models.CharField(max_length=200, verbose_name=_("name"))
slug = models.SlugField(max_length=200, unique=True, verbose_name=_("slug"))
description = models.TextField(blank=True, default="", verbose_name=_("description"))
website_url = models.URLField(blank=True, default="", verbose_name=_("website URL"))
contact_email = models.EmailField(blank=True, default="", verbose_name=_("contact email"))
contact_phone = models.CharField(max_length=50, blank=True, default="", verbose_name=_("contact phone"))
is_active = models.BooleanField(default=True, verbose_name=_("active"))
created_at = models.DateTimeField(auto_now_add=True, verbose_name=_("created at"))
updated_at = models.DateTimeField(auto_now=True, verbose_name=_("updated at"))
class Meta:
verbose_name = _("restaurant group")
verbose_name_plural = _("restaurant groups")
ordering = ("name",)
def __str__(self):
return self.name
gettext_lazyによるi18n、blank=Trueとdefault=""の併用、Metaのverbose_name/ordering、__str__まで、Django modelとしての定石は押さえている。25モデル分これが大きくブレずに出ている。ただ、Qwen3.6でもこれに近い形で出るので、TG100超とTG30台の差を考えると微妙なところ。
観測された失敗モード
TGとは別軸で、再計画パスのplannerに次のログが出た。
invalid tool call returned as assistant text finish=stop
[text_len=1864 saw_start=1 saw_end=1]
何が起きたか。plannerは「これは再計画パスなので新しい成果物は宣言しない」と判断し、write_fileツールの引数であるcontentの中に、ワイヤプロトコルの宣言XMLをネストして書こうとした。構造化出力の開始・終了マーカー、つまりsaw_start=1 saw_end=1を検出したが、これをtool callとしてではなくassistant textとして返してしまった。
<...DSML...tool_calls>
<...DSML...invoke name="write_file">
<...DSML...parameter name="content" string="true"><familiar wire=....
<thought>Re-planning pass: ... No deviations requiring corrective scope. ...</thought>
つまり「ツール引数の中に、本来トップレベルで返すべき構造化ドキュメントを入れ子にした」結果、パーサがどちらの文脈にも確定できず、テキストへフォールバックした。
これは次の両面が噛み合った失敗だと思う。
- モデル挙動: 再計画時に成果物宣言とツール呼び出しの境界を取り違える
- パーサ厳格性: 入れ子の構造化マーカーを安全側にテキスト扱いする
DeepSeekはまだそれほど試していないので分からないが、Qwen系は特にXML定着が強い。ワイヤプロトコルにXMLを使っていると、ツールコールミスが増えてくる。TOMLベースのワイヤプロトコルも実装して試したところ、ツールコールミスは減ったが、XMLがよく学習されていることによるメリットも同時に失う。 最近考えているのは、HTMLベースのワイヤプロトコルは案外いいかもしれない、ということ。モデルの学習データに多く入っているので、構造を理解しやすいはずだから。
現時点の評価
TG ~34t/sはworkerとしては弱い。 実装を長く書かせる用途には向かない。DeepSeek-V4-Flash/DwarfStar4はworkerとして押し切るより、判断回数が少なく、出力トークンが比較的短いorchestrator用途や、ライセンスが緩いことを活かした蒸留データ元として利用するのが現実的かなと思う。
オーケストレータ専用なら良好。 DAG構築、依存解決、再計画ループは破綻なく回り、生成物の質も問題なかった。2ノード分散の効果はターン内で常に効くものではなく、並行ターンや並行ワーカーがあるときに効く。IQ2XXSは量子化がきつすぎるように見えるけど、GLM-5.1もsmol-IQ2KSで長く運用していた。量子化がきついかどうかより、むしろ100B以下のモデルのQ4/5あたりのほうが破綻することが多い。量子化のキャリブレーション、PPL次第ではあるが。
ツール抽出の信頼性にはリスクが残る。 再計画パスでのtool-call-as-textフォールバックは、TGとは独立した「パーサ×モデル挙動」の問題として残る。Qwen系と同じで、XMLに引きずられやすいかもしれない。
現状の手触りではStep-3.7-Flashのほうが強い。 直近のcommitでDwarfStar4/DeepSeek-V4-Flashも再度試したが、今のfamiliarのorchestratorとしてはStep-3.7-Flashのほうが良かった。