DeepSeek-V4-Flash を llama.cpp WIP ブランチで動かす: Blackwell Max-Q 96GB x2 の初回ローカル推論
DeepSeek-V4-Flash (284B MoE / 13B active) を RTX PRO 6000 Blackwell Max-Q 96GB x 2 上で llama.cpp の WIP DeepSeek-V4 ブランチと native FP4/FP8 GGUF を使って動作確認した記録。公式推論コードで詰まった点、GGUF 変換の試行、PP/TG 実測値、Flash Attention 未対応による制限をまとめた。

DeepSeek-V4-Flash を RTX PRO 6000 Blackwell Max-Q 96GB x 2 でローカル推論した。今回の結論はかなり限定的で、llama.cpp の WIP ブランチと community GGUF で「動くだけ」を確認した段階だ。
それでも 284B MoE / 13B active のモデルが、native FP4/FP8 GGUF のままローカルで TG 35 t/s 前後まで出ている。Flash Attention はまだ無効で、DSV4 の graph 実装も最適化途中なので、完成版の性能評価ではなく、2026-04-27 時点の実験記録として残しておく。
動画リンク: https://www.youtube.com/watch?v=Hjl4efNonxE
先に結果
使ったのは nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF と、llama.cpp PR #22378 の wip/deepseek-v4-support ブランチ。Hugging Face の model card では DeepSeek-V4-Flash は 284B params、GGUF 側は deepseek4 architecture として公開されている。
| 項目 | 値 |
|---|---|
| Model | DeepSeek-V4-Flash |
| Parameters | 284B MoE |
| Active parameters | 13B |
| Experts | 256 experts / 6 active |
| GGUF | nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF |
| Runtime | llama.cpp wip/deepseek-v4-support |
| Commit range | b8942-ba173dd08 |
| Quantization | native FP4 + FP8 |
| GGUF size | 146GB |
| BPW | 4.39 |
| GPUs | RTX PRO 6000 Blackwell Max-Q 96GB x 2 |
ベンチマークのサマリーは次のとおり。
| 指標 | 値 |
|---|---|
| Prompt eval (PP) | 36.5-39.4 t/s |
| Token generation (TG) | 34.1-41.7 t/s |
| PP average | 38.3 t/s |
| TG average | 35.7 t/s |
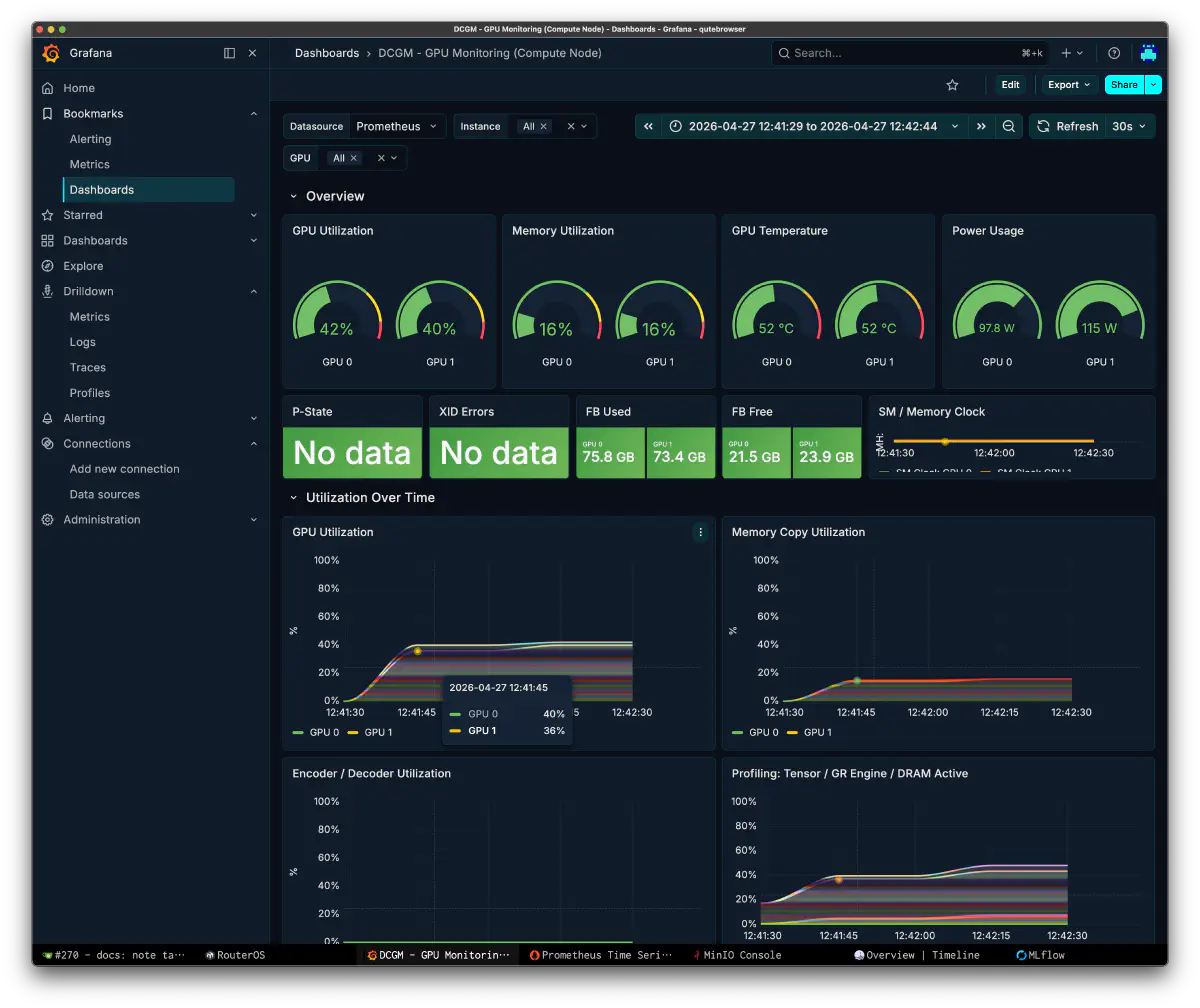
| VRAM | GPU0: 75.1GB, GPU1: 72.8GB |
| Offloaded layers | 44/44 |
| CPU mapped | 1010 MiB |
| Flash Attention | disabled |
| GPU utilization | 30-40% burst |
| Peak power | GPU0: 97.8W, GPU1: 115W |
| Graph splits | 3 |
GPU 使用率は 30-40% 程度の burst に留まり、300W TDP に対して消費電力も 100-115W 付近だった。Flash Attention と expert dispatch graph が詰まれば、まだ伸びる余地は大きい。
起動コマンド
最終的に使った起動コマンドはこれ。
podman run --rm \
-p 8000:8000 \
--device nvidia.com/gpu=all \
--shm-size 8g \
-v /mnt/data/models/models--nsparks--DeepSeek-V4-Flash-FP4-FP8-GGUF:/models:Z \
llama.cpp:deepseek-v4 \
-s -m /models/snapshots/.../DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--n-gpu-layers 999 --threads 15 --threads-batch 24 \
--ctx-size 8192 --parallel 1 -b 4096 -ub 2048 \
--jinja --host 0.0.0.0 --port 8000 --alias deepseek-v4
llama-server が OpenAI 互換エンドポイントを持っているので、公式 inference/ に API wrapper を被せる必要はなかった。
検証環境
| 項目 | 値 |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x 2 |
| Compute Capability | sm_120 |
| Driver | 580.126.09 |
| CUDA | 13.0 |
| CPU | AMD EPYC 9175F |
| RAM | 768GB DDR5-6400 |
| Container | Podman |
| Native FP4 | BLACKWELL_NATIVE_FP4 enabled |
transformers で直接ロードしたときは GPU0/GPU1 とも 80GB 前後まで VRAM を使っていた。初回 response までは確認できたが、prompt を request すると落ちた。その後、公式推論コード側の問題を追ったが、最終的には GGUF 版が Hugging Face に上がっていたので、そちらで動作確認した。
リクエスト別ベンチ
短い prompt が中心なので PP の真価を見るテストではないが、実験段階の速度感はつかめる。
| # | 内容 | prompt tokens | PP (ms/t) | PP (t/s) | gen tokens | TG (ms/t) | TG (t/s) | total (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | 日本語質問 | 14 | 26.7 | 37.4 | 41 | 27.1 | 36.9 | 1.5 |
| 2 | MoE説明 | 20 | 25.9 | 38.6 | 132 | 27.8 | 36.0 | 4.2 |
| 3 | FP4 vs FP8 | 19 | 25.9 | 38.7 | 125 | 27.7 | 36.1 | 4.0 |
| 4 | system prompt | 31 | 25.8 | 38.7 | 182 | 27.8 | 36.0 | 5.9 |
| 5 | マルチターン | 50 | 25.9 | 38.6 | 512 | 28.0 | 35.7 | 15.6 |
| 6 | Go code | 23 | 25.8 | 38.7 | 230 | 27.8 | 35.9 | 7.0 |
| 7 | 論理問題 | 23 | 25.9 | 38.7 | 207 | 27.8 | 35.9 | 6.4 |
| 8 | 比較分析 | 30 | 25.8 | 38.7 | 427 | 28.0 | 35.8 | 12.7 |
| 9 | JSON出力 | 26 | 27.4 | 36.5 | 122 | 29.3 | 34.1 | 4.3 |
| 10 | DSV4アーキテクチャ | 45 | 25.8 | 38.7 | 414 | 27.9 | 35.8 | 12.7 |
品質面では、MoE 説明、コード生成、論理問題のいずれも短いテストでは大きく破綻しなかったけど、日本語ストリーミングで 東東京圜 のようなおかしいのも幾度が出る場面があった。まだテストブランチなので品質は意味ないのでTG予想として見ておくといいと思う。
Flash Attention が無効
今回のログでは Flash Attention は自動で disabled になった。
sched_reserve: layer 0 is assigned to device CUDA0 but the Flash Attention tensor is assigned to device CPU (usually due to missing support)
sched_reserve: Flash Attention was auto, set to disabled
DeepSeek-V4 は CSA + HCA + Indexer を含む custom attention architecture で、WIP ブランチではこの graph の Flash Attention がまだ実装途中に見える。GPU utilization が 30-40% で止まっているのも、ここが主因だと見ている。
PP は Flash Attention 対応後にかなり伸びるはず。一方、TG は 4.39 BPW の native FP4/FP8 GGUF を 2GPU に分散して毎 token 読んでいるので、Flash Attention の有無よりもメモリ帯域と expert dispatch のほうが効く。現状の 35 t/s 前後は、実験としてはかなり良い。
公式推論コードで試したこと
最初は GGUF ではなく、公式 repository の inference/*.py をそのまま使う方向で試した。公式コードは generate.py でローカル生成する構成で、HTTP endpoint は付いていない。そのため generate.py 側の tokenizer / model / distributed runtime を呼び出す FastAPI + uvicorn の薄い wrapper を作り、OpenAI 互換の /v1/chat/completions として叩けるようにした。
weight 変換は MP=2 で成功した。transformers 直ロードでは両 GPU に 80GB 前後ずつ載り、公式 inference/*.py 経由でも初回 response までは確認できた。起動時の nvtop では GPU0/GPU1 それぞれに 79680MiB 程度の process が立ち、VRAM 使用率は約 81% まで上がっていた。
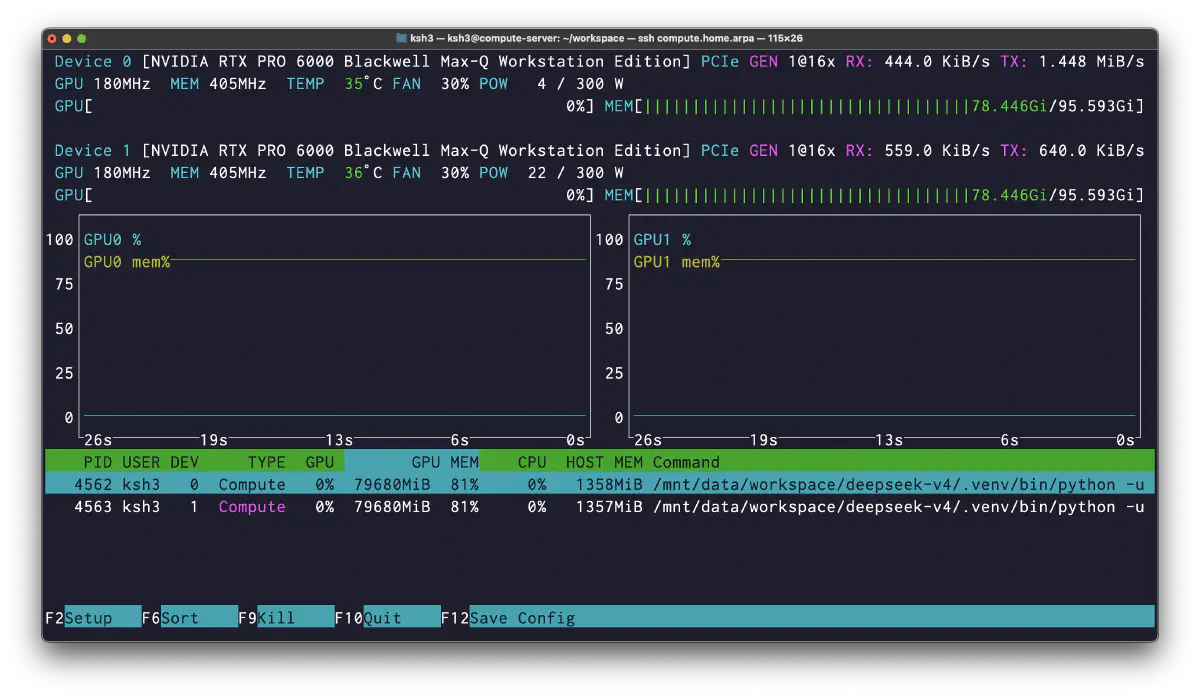
ただし、prompt を request すると落ちた。そこから下の問題を順番に潰したが、最終的には NGC コンテナの torch version と DSV4 の FP4 dtype 要件が残り、公式コードでの安定運用は断念した。
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} \
--n-experts 256 --model-parallel 2
NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 PYTHONPATH=. \
torchrun --standalone --nproc-per-node 2 main.py \
--ckpt-path ${SAVE_PATH} --config ${CONFIG} --port 8000
主な問題は次のとおり。
| 問題 | 状態 |
|---|---|
| NCCL segfault | broadcast 時に ncclNetPluginInit 周辺で segfault。NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 で回避 |
| tilelang が CUDA を検出しない | ベアメタル側に CUDA toolkit がなく、container overlay から nvcc を symlink して回避 |
| sparse attention の shared memory | tilelang の CSA sparse attention kernel が 104KB dynamic shared memory を要求 |
| block size 調整 | sparse attention の block size を 64 -> 32 に落として shared memory 側は回避 |
| NGC torch が古い | nvcr.io/nvidia/pytorch:25.04-py3 は torch 2.7.0 |
| DSV4 FP4 dtype | DeepSeek-V4-Flash が使う torch.float4_e2m1fn_x2 は torch 2.11+ 前提 |
Blackwell は 228KB/SM まで dynamic shared memory を使える。tilelang の sparse attention kernel が要求する 104KB はハードウェア上は届くはずで、実際に block size を 64 -> 32 に落とすことで shared memory の壁は越えられた。
残った blocker は torch だった。NGC コンテナ側は torch 2.7.0 に pin されていて、DeepSeek-V4-Flash が使う float4_e2m1fn_x2 に届かなかった。constraints が強く、単純な差し替えでは解決しない。ここで公式 inference/*.py での追跡はいったん止め、Hugging Face に上がっていた native FP4/FP8 GGUF で検証を続けた。
GGUF 自前変換で試したこと
次に nsparks の WIP ブランチにある convert_hf_to_gguf.py で自前変換を試した。
python3 convert_hf_to_gguf.py ${HF_SNAP} \
--outtype native \
--torch-threads 16 \
--outfile dsv4-flash-native.gguf
ここでも段階的に詰まった。
| 段階 | 結果 |
|---|---|
| torch 2.6 | F8_E8M0 KeyError |
| torch 2.11 CPU | F8_E8M0 は通る |
| transformers | deepseek_v4 model_type 未認識 |
| tokenizer | PreTrainedTokenizerFast への差し替えで一部回避 |
| pre-tokenizer | joyai-llm 未対応で断念 |
この時点で community GGUF が公開されていたので、自前変換を追うよりも動作確認を優先した。
最終的に使った GGUF
使ったモデルは nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF。model card 上では upstream が deepseek-ai/DeepSeek-V4-Flash、変換コマンドは次の形で示されている。
python3 convert_hf_to_gguf.py /mnt/models/hf/DeepSeek-V4-Flash \
--outtype moe-f8-e4m3-mxfp4 \
--torch-threads 96 \
--outfile DeepSeek-V4-Flash-FP4-FP8-native.gguf
DeepSeek 公式の Hugging Face repository は MIT License。
追跡している upstream
2026-04-27 時点では、llama.cpp 本家の DeepSeek-V4 対応は WIP のまま。
| PR / Discussion | 内容 |
|---|---|
| llama.cpp PR #22378 | wip/deepseek-v4-support。runtime graph、FP4/FP8 support、performance hot path を含む draft PR |
| llama.cpp PR #22359 | DeepSeek-V4 GGUF conversion script |
| Discussion #22376 | DeepSeek-V4 support discussion |
| nsparks GGUF | native FP4/FP8 GGUF |
| official HF | official DeepSeek-V4-Flash weights |
PR #22378 の履歴を見る限り、FP4/FP8 support、DeepSeek4 runtime state save、F8 decode tuning、TOP_K fast path、RMSNorm/copy kernel tuning などが短期間で積まれている。TGは-ot exps=CPUしたときに近い数字へ寄るかもしれない。
所感
まず、幸運なことに自分のワークステーションにマッチするサイズ感だったこと、284B MoE がローカルで普通に response を返し、TG 35 t/s 前後で動いていること自体が大きい。今回の結果は実験的なもので最適化されれば全く変わる。Flash Attention は無効、graph splits は 3、GPU utilization は 30-40% で、PP は特に伸びしろが大きいはず。
TG はすでに実用域に入っている。ライセンスもクリアで、SFT,DPO用途の蒸留データ元、パイプライン、バッチ用途なら35 t/s あれば実用的だ。GLM-5.1, Kimi-k2.6, Qwen3.5-397B を 自作エージェント の オーケストレーターとして見ていたが、DeepSeek-V4-Flashもik_llama.cpp, llama.cppで最適化されればcpu/gpuのhybrid構成でベストなオーケストレーターとなりえる。GPUフルロード単体としてもKV-90%削減しているとの情報もあったので、ctx多めの単体利用も期待している。 DSV4のattentionは V3.2比でKV cache 93%削減、FLOPs 90%削減と公称してる。 現状の構成: VRAM合計: 192GB モデル: GPU0 75.1GB + GPU1 72.8GB = 147.9GB 空き: GPU0 21.5GB + GPU1 23.9GB = 45.4GB KV cacheが通常の7%しか使わないなら、32-45GBの空きVRAMで巨大なコンテキストが入る。今、苦労して複数のモデルをロールベースで協調させて、ctx管理、最適化を工夫しているが、まさにそれを単一モデルで実現するためのモデルだと思う。そうなるとオーケストレーションも不要になるかもしれない。