DwarfStar4 RTX PRO 6000 Blackwell: DeepSeek V4 Flash Q2 First Look 43 tok/s
NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB 上で antirez の DwarfStar 4 推論エンジンを検証。DeepSeek V4 Flash 284B の Q2-imatrix 量子化が単一GPUに収まり、43 tok/s の生成速度、disk KV cache、directional steering、コーディングエージェント運用までをファーストルックとしてまとめた。

antirez さんの DwarfStar 4 (ds4.c) で DeepSeek V4 Flash を RTX PRO 6000 Blackwell Max-Q Workstation Edition 96GB に載せた。結論から言うと、Q2-imatrix 量子化の DeepSeek V4 Flash 284B が単一 GPU に収まり、短い生成では 43 tok/s、50K context でも 31 tok/s 台を維持した。
まだ alpha 段階の実装ではあるが、挙動は現行の Codex や Claude Code のようなhead tail指定ができるようにみえた。自作エージェントのオーケストレーションモデルとして、RTX PRO 6000 Blackwell 96GB なら十分フィットする。実用上のスイートスポットは 32K-64K あたりで、用途によっては 96K運用も見えてくる。128Kで起動はできたが余白があまりないので、今は96Kが天井と思って良さそう。今後の最適化で変わるかもしれないけど。
動画リンク: https://www.youtube.com/watch?v=A4aGNHEdrxE
先に結果
| 項目 | 値 |
|---|---|
| Model | DeepSeek V4 Flash |
| Parameters | 284B MoE / 13B active |
| Runtime | DwarfStar 4 (ds4.c) |
| Build | cuda-generic |
| Quant | IQ2_XXS + Q2_K routed expert, Q8 attention/shared/output |
| GGUF | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition |
| GPU memory | 96GB GDDR7 ECC |
| Memory bandwidth | 1,792 GB/s |
| Model tensor cache | 80.76 GiB |
| Peak observed VRAM | 93,142 MiB / 95,593 MiB |
| Short generation | 43.6 tok/s |
| 50K context generation | 31.4 tok/s |
| 20K prefill | 262 tok/s |
前回は llama.cpp の WIP DeepSeek-V4 ブランチで DeepSeek V4 Flash を dual RTX PRO 6000 に載せた。今回は ds4.c のモデル特化ランタイムを使い、単一 RTX PRO 6000 Blackwell Max-Q 96GB に 80GiB 級の Q2-imatrix GGUF を載せている。
重要なのは、単に「動いた」だけではなく、コーディングエージェントの実タスクで使える速度まで出ていることだった。50K context でも tool call generation が 31 tok/s 以上を保ち、複数ターンのエージェントセッションも安定して完走した。
DwarfStar 4 の設計
DwarfStar 4 は汎用 GGUF runner ではなく、DeepSeek V4 Flash だけに絞ったネイティブ推論エンジンだ。公式 README でも、モデルロード、prompt rendering、tool calling、RAM/on-disk KV state、server API を DeepSeek V4 Flash 向けに自前実装していると説明されている。
この割り切りはかなり良い。汎用エンジンは新モデル対応を追い続ける必要があるが、DwarfStar 4 は単一モデルに対して logit validation、長文 context 検証、agent integration までまとめて品質確認している。ローカル LLM を coding agent として使う側から見ると、推論エンジン、量子化、server API、tool calling の形が一体で検証されているのは大きい。
一方で、現時点では alpha quality と明記されている。CUDA backend も今後さらに詰める余地があり、今回の数字は「完成版の上限」ではなく、2026-05-14 時点の first look として見るのがよい。
検証環境
| 項目 | 内容 |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition |
| GPU architecture | SM_120 (Blackwell) |
| VRAM | 96GB GDDR7 ECC |
| Memory bandwidth | 1,792 GB/s |
| CPU | AMD EPYC 9175F |
| RAM | 755 GiB |
| Storage | NVMe 3.5T (xfs) |
| OS | Ubuntu 24.04 |
| CUDA | 13.2.1 |
| Container | Podman rootless |
| Model | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix |
| Engine | DwarfStar 4 (cuda-generic build) |
RTX PRO 6000 Blackwell Max-Q は 96GB の GDDR7 ECC と 1,792 GB/s のメモリ帯域を持つ。DeepSeek V4 Flash のような MoE decode はメモリ帯域の影響を強く受けるので、単一 GPU でどこまで行けるかを見るにはかなり相性が良い。
ビルドと起動
CUDA 版は次のターゲットでビルドできた。
make cuda-generic
実際に grandpa 用として焼いた container image は、CUDA 13.2.1 の devel image から ds4 を clone して cuda-generic build するだけの薄いものにした。
FROM docker.io/nvidia/cuda:13.2.1-cudnn-devel-ubuntu24.04
RUN apt-get update && apt-get install -y --no-install-recommends \
git make gcc g++ ca-certificates && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
RUN git clone --depth 1 https://github.com/antirez/ds4.git . && \
make cuda-generic -j$(nproc)
EXPOSE 8000
ENTRYPOINT ["./ds4-server"]
Build と push は次の形。
podman build -t registry.home.arpa/dwarfstar4:latest .
podman push registry.home.arpa/dwarfstar4:latest
Blackwell 世代の SM_120 では -arch=native が適切な architecture を選択した。実行環境は Podman rootless container で、NVIDIA CDI passthrough と host networking を使っている。
起動ログでは、CUDA backend の初期化、80GiB 級 tensor cache の device load、NVMe からのモデルロードが確認できた。
ds4: CUDA backend initialized on NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (sm_120)
ds4: CUDA loading model tensors into device cache: 80.04 GiB
ds4: CUDA startup model cache prepared 80.76 GiB of tensor spans in 16.198s
NVMe からの model cache 準備は約 16.2 秒。284B MoE のローカルランタイムとしては、起動時の待ち時間もかなり扱いやすい。
Q2-imatrix 量子化
今回使った GGUF は、DeepSeek V4 Flash の routed expert だけを強く圧縮する非対称量子化になっている。
| Tensor class | Quant |
|---|---|
| routed expert up/gate | IQ2_XXS |
| routed expert down | Q2_K |
| shared experts | Q8_0 |
| attention projections | Q8_0 |
| output head | Q8_0 |
| router / embedding / auxiliary blocks | F16 / F32 |
MoE では routed expert がモデルサイズの大半を占める一方、各 token が通る expert は一部だけになる。そこで routed expert を aggressive に圧縮し、router、attention projection、shared expert、output head のような品質影響が大きい部品は高めの精度で残す。結果として 284B モデルを 80GiB 級に収めつつ、コーディングエージェント用途で破綻しにくい品質を狙っている。
生成速度
生成速度は短文で 43.6 tok/s、50K context で 31.4 tok/s だった。
| Context / generation | 生成速度 | 備考 |
|---|---|---|
| 短文 約100 tokens | 43.6 tok/s | Thinking mode |
| 中程度 約400 tokens 生成 | 41.7 tok/s | Thinking mode |
| 長文 4,058 tokens 生成 | 平均 38.5 tok/s / 最低 37.3 tok/s | Thinking to Text |
| 20K context | 36.3 tok/s | Tool calling 有効 |
| 33K context | 35.3 tok/s | 安定 |
| 50K context | 31.4 tok/s | 非常に安定 |
Context が深くなるにつれて TG は落ちるが、落ち方はかなり穏やかだった。43 tok/s から始まり、50K context でも 31 tok/s 台を維持しているので、ローカル coding agent の orchestrator としては十分現実的な速度に入っている。
自分の用途では、32K-64K あたりが一番扱いやすい sweet spot だと思う。256K のような長文運用も DwarfStar 4 の設計上は魅力があるが、エージェント用途では context をただ伸ばすより、再利用できる prefix と session 管理をどう設計するかのほうが効いてくる。
Prefill
Prefill は 2048 token 単位の chunked prefill で進む。深い context でも 245 tok/s 以上を保っていた。
| Token count | Prefill 速度 |
|---|---|
| 13K tokens | 267 tok/s |
| 20K tokens | 262 tok/s |
| 30K+ tokens incremental | 245-251 tok/s |
ここで prefill が遅すぎると実用感がかなり悪くなるが、今回の 20K context で 262 tok/s だった。うーん、これはどうなんだろう。 GLM-5.1 のチューニングを最適化しているが、TG23, PP700ほどまで詰めている。オーケストレーターの場合、どちらかというとprefillが欲しいところ。 ただ、リポのcommitにはMTPのPRが入っていたのでそれが使えると、話はだいぶかわってくる。現状は使えるけどあまり効果は得られていないとか。
VRAM 使用量
VRAM はほぼ使い切る。
GPU MEM: 93,142 MiB / 95,593 MiB (95%)
モデル本体の tensor cache が 80.76 GiB あり、そこに context buffer と計算用 pool が載る。CPU offload なしの完全単一 GPU 動作なので、RTX PRO 6000 Blackwell 96GB をかなりきれいに使い切る構成になった。
Dual GPU や CPU/GPU hybrid の巨大 MoE と比べると、運用はずっと単純になる。1 枚の GPU に model/runtime/context を閉じ込められるので、Zed や自作 agent から OpenAI 互換 API として叩く構成が作りやすい。
Disk KV Cache
DwarfStar 4 で特に面白いのは、disk KV cache を第一級機能として扱っている点だ。DeepSeek V4 Flash の圧縮 KV cache と高速 NVMe を組み合わせ、KV state をディスクへ退避・再利用する。LMCacheのようなイメージかな。サーバー用品でなくていいので、最速のm.2.外付け買ってきてkvとして使えば熱も気にならないし良さそう。
今回のログでは、evict 時の KV 保存が 200-370ms 程度で終わっていた。
kv cache stored tokens=3405 size=67.56 MiB save=198.9 ms reason=evict
kv cache stored tokens=54163 size=734.07 MiB save=371.9 ms reason=evict
cold、continued、evict の各 trigger pattern が正常動作することを確認した。Prefix reuse も実測で効いていた。
| 実行 | 応答時間 |
|---|---|
| 初回実行 | 0.148 s |
| 再実行 | 0.073 s |
ほぼ半分の時間で応答している。巨大 system prompt や repository context を何度も読む coding agent では、この prefix reuse が TTFT を左右する。
ただし、自分の環境ではここが一番設計上の注意点でもあった。自作エージェントはマルチセッション前提の context manager を持っていて、DwarfStar 4 の KV reuse とそのまま組み合わせると相性が悪い。そこで、DwarfStar 4 専用の context manager,とadapter を作り、orchestration session 側で single-session に近い前提を吸収する形にした。
他プラットフォームとの比較
厳密な同一条件比較ではないが、公開情報や手元で見た値を並べると、decode はメモリ帯域の差と同じ方向に伸びている。
| Platform | Memory bandwidth | Generation | 備考 |
|---|---|---|---|
| DGX Spark GB10 | 273 GB/s | 10-14 tok/s | 参考値 |
| Mac Studio / Apple Silicon | 構成依存 | 16-36 tok/s | 参考値 |
| RTX PRO 6000 Blackwell Max-Q | 1,792 GB/s | 43.6 tok/s | 今回の実測 |
MoE decode は毎 token で expert weights を読むため、メモリ帯域にかなり引っ張られる。RTX PRO 6000 Blackwell Max-Q は 1,792 GB/s の GDDR7 帯域を持つので、単一 GPU でも 43 tok/s 台まで届いた。RTX MAX-Qでなければもう少しPPは伸びるかもしれない。
まだalpha段階なので、今後伸びる余地は大きいと思う。
- CUDA backend が alpha 段階
- MTP対応
コーディングエージェント運用
Zed エディタの AI Assistant を ds4-server の OpenAI 互換 API に接続し、実際の coding task を流した。
DwarfStar 4 は DeepSeek V4 Flash の DSML tool format を native support しており、次のような tool call を自律的に実行できた。
roots_listdirectory_treeread_fileterminalspawn_agent
Tool call の内訳を見ると、自作のbuiltin tools read_text_file と list_directory が多く、ctree や pathfinder も使えていた。一方で、terminal 経由では _contract/architecture.md に対して grep -c を繰り返す癖も見えた。これは既存の Codex / Claude 系 agent にも近い挙動で、手早く局所確認するには有効だが、構造把握では ctree や pathfinder 側へ寄せたほうが context 効率は良くなるので、このへんは矯正するなどが必要そうだった。
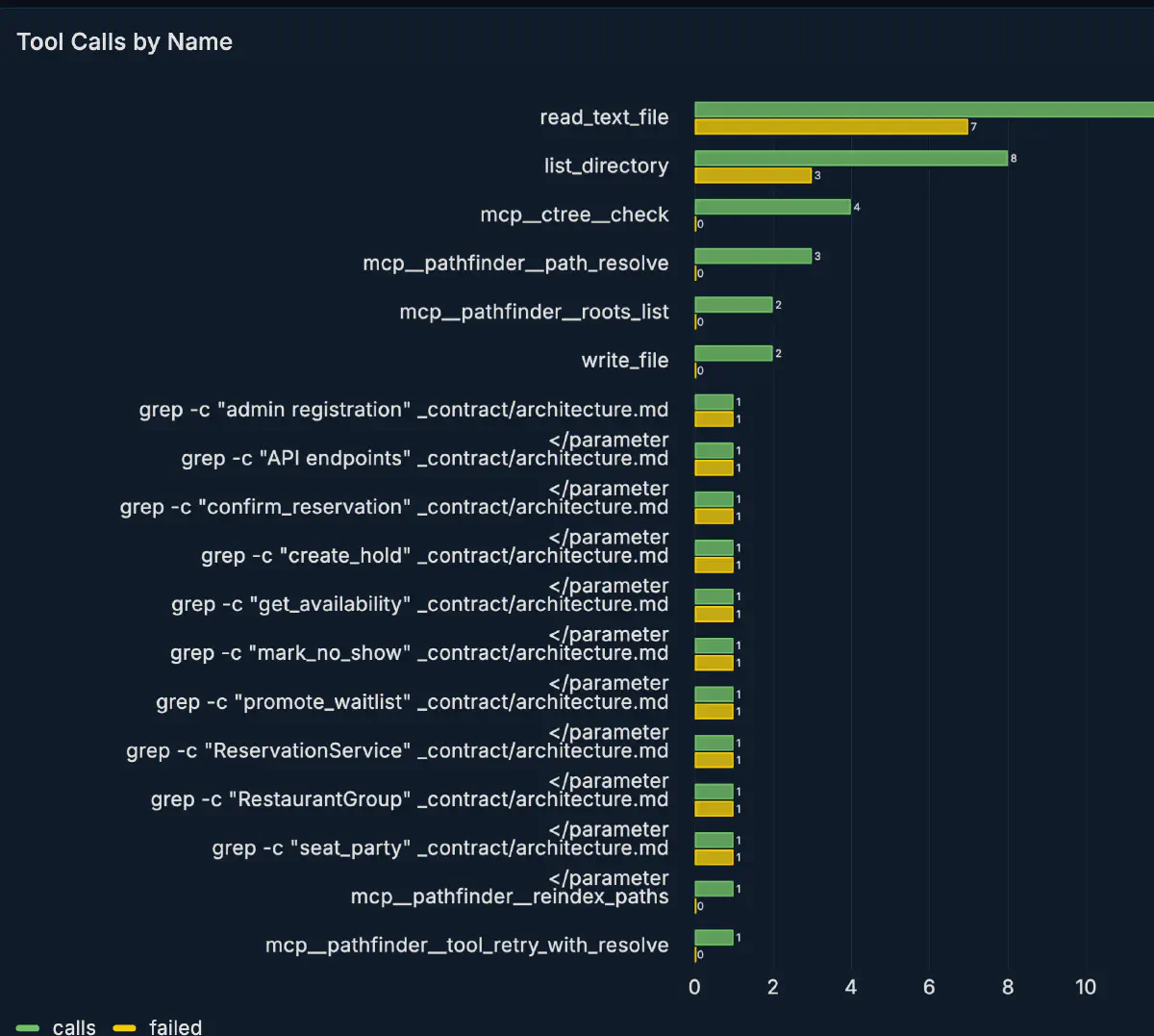
50K context 状態でも tool call generation は 31 tok/s 以上を維持した。複数ターンの agent session も安定して完走しており、ベンチマークだけでなく実作業の感触もかなり良い。サンプリングは公式の値だとオーケストレーターでは微妙だったので微調整した。
特に印象的だったのは、振る舞いが現行の Codex や Claude に似ていることだった。もちろんまだ全然検証しきれていないので、完全な置き換えとして評価するにはまだ早いが、少なくとも「ローカルLLMの orchestrator model」としては条件が揃っている。
自作エージェントにも早速入れ替えて検証を始めた。まだ本格評価ではなく first look だが、RTX PRO 6000 Blackwell 96GB に載せるモデルとしては、速度、context のバランスがかなり良い。
DwarfStar 4 にはこの用途に合う材料が揃っている。
model=deepseek-chatで non-thinking mode を選べる--warm-weightsで初回推論時の stutter を減らせる--dir-steering-fileと--dir-steering-ffn -1で verbosity steering を当てられる-n 4096のように default output budget を絞れる- disk KV cache で長い orchestration session の prefix reuse を維持できる
コードレビュー用 worker には thinking mode や長い context を残し、orchestrator は model=deepseek-chat 固定の non-thinking で dispatch に徹するのが役割として自然だと思う。
ヘルプ上では non-thinking の選択条件が明記されていた。
thinking={type:disabled}, think=false, or model=deepseek-chat selects non-thinking mode.
ds4-server の主なパラメータ
| 分類 | パラメータ | 見立て |
|---|---|---|
| Model | -m, --model | ds4 専用 GGUF を指定する。汎用 GGUF runner ではない |
| MTP | --mtp, --mtp-draft, --mtp-margin | 投機デコード用。まだ experimental で、grandpa 常用では優先度低め |
| Context | -c, --ctx | 起動時に確保する context。grandpa は 32768 で十分、frisky は 131072 まで伸ばす余地あり |
| Output | -n, --tokens | max_tokens 省略時の default。grandpa は 4096 程度に絞る |
| CPU | -t, --threads | Tokenize / prompt rendering などの補助用。未指定でよい |
| Quality | --quality | 厳密カーネルに寄せる。品質評価や benchmark 用で、常駐 grandpa では基本不要 |
| Steering | --dir-steering-file, --dir-steering-ffn, --dir-steering-attn | grandpa は FFN 側に -1 を当てて簡潔方向を増幅。attention 側は実験用 |
| Warmup | --warm-weights | 常駐サービスなら付けておく。初回推論の page fault/stutter を減らす |
| Backend | --cuda, --metal, --cpu, --backend | RTX PRO 6000 では CUDA。CPU は診断用 |
| API | --host, --port | grandpa=8000, frisky=8001 のように role ごとに分ける |
| Trace | --trace | prompt、cache 判断、出力、tool call を human-readable に保存。fulfillment log や DPO データ化に使えるかもしれない |
| Thinking | reasoning_effort, thinking, think, model | grandpa は model=deepseek-chat で non-thinking。reviewer / frisky は thinking を使う価値あり |
| Disk KV | --kv-disk-dir, --kv-disk-space-mb, --kv-cache-* | grandpa は 4GB でも足りそう。長い review 履歴を持つ worker は 16GB もあり |
| Tools | --disable-exact-dsml-tool-replay, --tool-memory-max-ids | tool calling を使わない grandpa ではほぼ無関係 |
grandpa 本採用時の常駐設定はこの形になりそうだ。実運用では --ctx 65536、--tokens 4096、disk KV 32GB、--trace 付きで立てる。ツールを使わない dispatch 専用としてさらに絞るなら、--ctx 32768、disk KV 4GB まで落とせる。
[Container]
ContainerName=grandpa
Image=registry.home.arpa/dwarfstar4:latest
Pull=always
Network=host
AddDevice=nvidia.com/gpu=0
Volume=/mnt/data/models/models--antirez--deepseek-v4-gguf/snapshots/c566ab6d7c696ddd0c7f124e115228af1a326824:/model:ro
Volume=/mnt/data/models/models--antirez--deepseek-v4-gguf/kv_cache:/kv
Exec=-m /model/DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf --ctx 65536 --tokens 4096 --host 0.0.0.0 --port 8000 --warm-weights --kv-disk-dir /kv --kv-disk-space-mb 32768 --trace /kv/trace.log
同じ設定を手元で一回だけ検証するなら podman run --rm -it で直接叩ける。
podman run --rm -it \
--device nvidia.com/gpu=0 \
-v /mnt/data/models/models--antirez--deepseek-v4-gguf/snapshots/c566ab6d7c696ddd0c7f124e115228af1a326824:/model:ro,Z \
-v /mnt/data/models/models--antirez--deepseek-v4-gguf/kv_cache:/kv:Z \
--network host \
registry.home.arpa/dwarfstar4:latest \
-m /model/DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf \
--ctx 65536 \
--tokens 4096 \
--host 0.0.0.0 \
--port 8000 \
--warm-weights \
--kv-disk-dir /kv \
--kv-disk-space-mb 32768 \
--trace /kv/trace.log
Steering を使う場合は、ds4 repository 側の dir-steering/ で vector を生成し、それを container に mount して --dir-steering-file で渡す。verbosity.f32 は container image 内に最初から存在するわけではないので、ホスト側で生成して mount するのが現実的だと思う。
cd ~/src/ds4
python3 dir-steering/tools/build_direction.py \
--ds4 ./ds4 \
--model ds4flash.gguf \
--good-file dir-steering/examples/succinct.txt \
--bad-file dir-steering/examples/verbose.txt \
--out dir-steering/out/verbosity.json \
--component ffn_out \
--ctx 512
ls -lh dir-steering/out/verbosity.f32
ds4-server は、ik_llama.cpp の cache pool とは考え方が違う。f_keep で部分再利用する。一方 ds4 は live KV cache を 1 本だけ VRAM に持つ。session を切り替えると、現在の KV を disk に evict save し、次の request の prefix が disk cache に hit したら読み戻して live session を差し替える。
Directional Steering
y = y - scale * direction[layer] * dot(direction[layer], y)
同梱されている verbosity vector は 43 layers × 4096 dimensions で、サイズは約 704KB。scale によって出力の詳細度を実行時に変えられる。
| Scale | 挙動 |
|---|---|
-1 | 出力長を約半分へ圧縮 |
2 | 詳細説明を強化 |
これは multi-agent role tuning と相性が良い。たとえば、orchestrator は -1 で短く判断させ、reviewer は 2 で詳細に検討させる。Fine-tuning なしで role ごとの出力密度を変えられるので、ローカル multi-agent runtime の制御面としてかなり面白い。
まとめ
| 項目 | 内容 |
|---|---|
| Model | DeepSeek V4 Flash 284B |
| Runtime | DwarfStar 4 |
| GPU | RTX PRO 6000 Blackwell Max-Q 96GB x 1 |
| Quant | Q2-imatrix |
| Short generation | 43.6 tok/s |
| 50K context | 31.4 tok/s |
| Prefill | 245-267 tok/s |
| Model cache | 80.76 GiB |
| Peak VRAM | 93.1 GiB |
DeepSeek V4 Flash 284B を単一 RTX PRO 6000 Blackwell に載せ、43 tok/s の generation と 50K context で 31 tok/s 台を維持できたのはかなり印象的だった。 もしかすると EPYC 9175F L3 512MB キャッシュの効果もあるかもしれない。
DwarfStar 4 はまだ alpha 段階だが、推論エンジン、量子化設計、disk KV cache、tool calling、directional steering を DeepSeek V4 Flash のために一体設計している。その結果、巨大 MoE モデルをローカルで「実用速度」の coding agent として運用できる形にかなり近づいている。 私のエージェントではすくなくとも振る舞いはいけそうな感触だった。 収斂しているGLM-5.1と比べると、まだ内容がちょっと微妙だったが、まだ最適化の検証を始めたばかりなので楽しみだ。
今後 CUDA backend、disk KV cache、directional steering が成熟していけば、DwarfStar 4 はローカル multi-agent runtime の有力な基盤になりそうだ。 ついでにコンシューマー向けのAMD MI350Pが最近発表されたのでリンクに追加しました。とてもフィットすると思う。