Gemma 4 31BをvLLM/SGLangで実測: NVFP4/FP8、MTP比較
Gemma 4 31B ITをvLLM 0.21.0とSGLang gemma4-mtpで動かし、NVFP4/FP8 block量子化、FP8/BF16 KV cache、Gemma 4 MTP投機デコードを比較した記録。

Gemma 4 31B ITをRTX PRO 6000 Blackwell 96GB 1枚に載せて、vLLM 0.21.0とSGLang gemma4-mtpの挙動を比べた。主に見たかったのは「どちらが速いか」だけではなく、KV cache dtype、KV pool、MTP投機デコードを有効にしたとき、実際のcoding-agent作業でどのような違いが出るかだった。
今回の記録では、vLLM側をNVFP4/FP8 block、SGLang側をFP8 block + BF16 KV/FP8 KVで比較した。結論から言うと、個人的にはvLLMのNVFP4 + FP8 KV、またはSGLangのFP8 block + FP8 KVがユースケースに乗りやすい。SGLangはKV cache容量ではvLLMに及ばないが、実際のタスクではツールの使い方が上手く、出力品質も良く感じた。生成内容は動画にも残している。
動画
SGLang側の実行記録。
動画リンク: https://www.youtube.com/watch?v=YlysBl5Qg34
動画リンク: https://www.youtube.com/watch?v=cgYbqnwqygM
比較一覧
同じRedHatAIのFP8モデルをctx 256Kで確認した。NVFP4はNVIDIAのモデルで計測した。
| Config | Runtime | Weights | KV cache | KV pool | Peak TG | Typical TG | Peak accept | Notes |
|---|---|---|---|---|---|---|---|---|
| A | vLLM 0.21.0 | NVFP4 | FP8 | 876K tok | 109.8 tok/s | 90-100 tok/s | 99.5% | 262K ctx、MTP x4 |
| B | vLLM 0.21.0 | FP8 block | FP8 | 876K tok | 115.3 tok/s | 80-100 tok/s | 93.5% | 262K ctx、MTP x4 |
| C | SGLang gemma4-mtp | FP8 block | BF16 | 69.7K tok | 約80 tok/s | 55-75 tok/s | 約90% | 262K ctx、SWAKVPool、MTP x5/6 |
| D | SGLang gemma4-mtp | FP8 block | FP8 | 139.5K tok | 約93.8 tok/s | 70-90 tok/s | 約96% | 262K ctx、SWAKVPool、MTP x5/6 |
- NVFP4は繰り返しで破綻することがたまに見られた。samplingや設定に何かミスがあるかもしれない。
- vLLM + MTP + prefix cachingは、単一ストリームでは一番高いTG帯に乗る。
- vLLMのthroughputは、負荷よりもMTP accept rateに強く連動して二つの帯に分かれる。
- SGLangはFP8 KVにすると、同じSWAKVPool footprintでBF16 KVの約2倍のtoken capacityを取れる。
- SGLang FP8 KVはraw throughputではvLLMより低いが、coding-agentの体感品質は良かった。
min_pを設定できるのも良い。
比較したかったこと
この検証で切り分けた軸は次の5つ。
- Runtime:
vLLMとSGLang - Weight quantization:
NVFP4とFP8 block - KV cache dtype:
FP8とBF16 - Context budgetとKV pool topology: vLLMのflat KVとSGLangのsliding-window KV pool
- Speculative decoding: MTP x4とMTP x5/6
単体のベンチマーク値だけならピークthroughputを見れば済むが、実際のcoding-agentでは長い文脈、反復するtool call、自由記述、構造化された出力が混ざる。MTPが高く受理される区間と落ちる区間の差を見るほうが、日常運用の見積もりには使いやすい。
Hardware
| 項目 | 値 |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell 96GB (SM120) |
| Host | AMD EPYC、768GB DDR5 ECC |
A. vLLM 0.21.0: NVFP4 weights + FP8 KV
最初の基準点は、Gemma 4 31BをNVFP4 4-bit weightsで載せ、KV cacheをFP8にし、Gemma 4 Assistant draft modelでMTP投機デコードを有効化した構成。contextは262,144、MTPはnum_speculative_tokens=4。(*公式cookbook)
Configuration
| 項目 | 値 |
|---|---|
| Runtime | vLLM 0.21.0 |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | ModelOpt NVFP4 weights |
| KV cache | FP8 |
| Context length | 262,144 |
| Tensor parallel | 1 |
| Speculative decoding | Gemma 4 MTP、4 speculative tokens |
| Attention backend | Triton Attention |
| Sampling backend | FlashInfer |
| Compile backend | torch.compile / Inductor |
起動コマンド
実行コマンド。使いまわしで不要なenvあり。
podman run --rm \
--name test-model \
--device nvidia.com/gpu=0 \
--ipc=host \
-p 8000:8000 \
-v /mnt/data/models:/hf/hub:ro \
-e HF_HOME=/hf \
-e HF_HUB_OFFLINE=1 \
-e TORCH_CUDA_ARCH_LIST=12.0 \
-e VLLM_FLASHINFER_MOE_BACKEND=throughput \
-e VLLM_TARGET_DEVICE=cuda \
-e VLLM_USE_FLASHINFER_MOE_FP4=1 \
registry.home.arpa/vllm/vllm-openai:v0.21.0-ubuntu2404 \
/hf/hub/models--nvidia--Gemma-4-31B-IT-NVFP4/snapshots/e5ef03afa233c35cb000323ff098d4291e1dd07c \
--host 0.0.0.0 \
--port 8000 \
--served-model-name test-model \
--dtype auto \
--kv-cache-dtype fp8 \
--tensor-parallel-size 1 \
--trust-remote-code \
--gpu-memory-utilization 0.85 \
--max-num-seqs 1 \
--async-scheduling \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--speculative-config '{"model":"/hf/hub/models--google--gemma-4-31B-it-assistant/snapshots/4735700dca7bd22fad5dc348c228b50ec6cbac6d","num_speculative_tokens":4}' \
--max-model-len 262144 \
--override-generation-config '{"temperature":0.9,"top_p":0.85,"top_k":64,"presence_penalty":0.0,"repetition_penalty":1.13}'
実測ログ
実行中の代表値はこうだった。
Generation throughput: 95.9 tok/s acceptance length: 4.28 draft acceptance: 82.0%
Generation throughput: 95.3 tok/s acceptance length: 4.18 draft acceptance: 79.5%
Generation throughput: 109.8 tok/s acceptance length: 4.97 draft acceptance: 99.2%
Generation throughput: 107.6 tok/s acceptance length: 4.98 draft acceptance: 99.5%
集約すると次の通り。
| 指標 | 値 |
|---|---|
| Generation throughput | 最大109.8 tok/s |
| Typical active generation | 90-100 tok/s前後 |
| Mean MTP acceptance length | 最大4.98、max 5相当 |
| Average draft acceptance rate | 80-90%前後 |
| Best draft acceptance rate | 99.5% |
| GPU memory used for model load | 32.06 GiB |
| KV cache size | 876,006 tokens |
throughputは95 tok/s前後の帯と107 tok/s以上の帯に分かれた。差はGPU loadというよりMTP accept rateに引っ張られている。
KV cacheは876K tokens確保されており、262K context windowの約3.3倍ある。ただし--max-num-seqs 1なので、単一セッションでは余剰分を使い切らない。
tool-call iterationの安定性を上げるためにsamplingもいくつか試した。今回のモデルではvLLM + MTP、text-only、min_pが使えなかったため、temperature、top_p、top_k、repetition_penaltyを調整したが、このworkloadで「これで決まり」と言える設定にはならなかった。
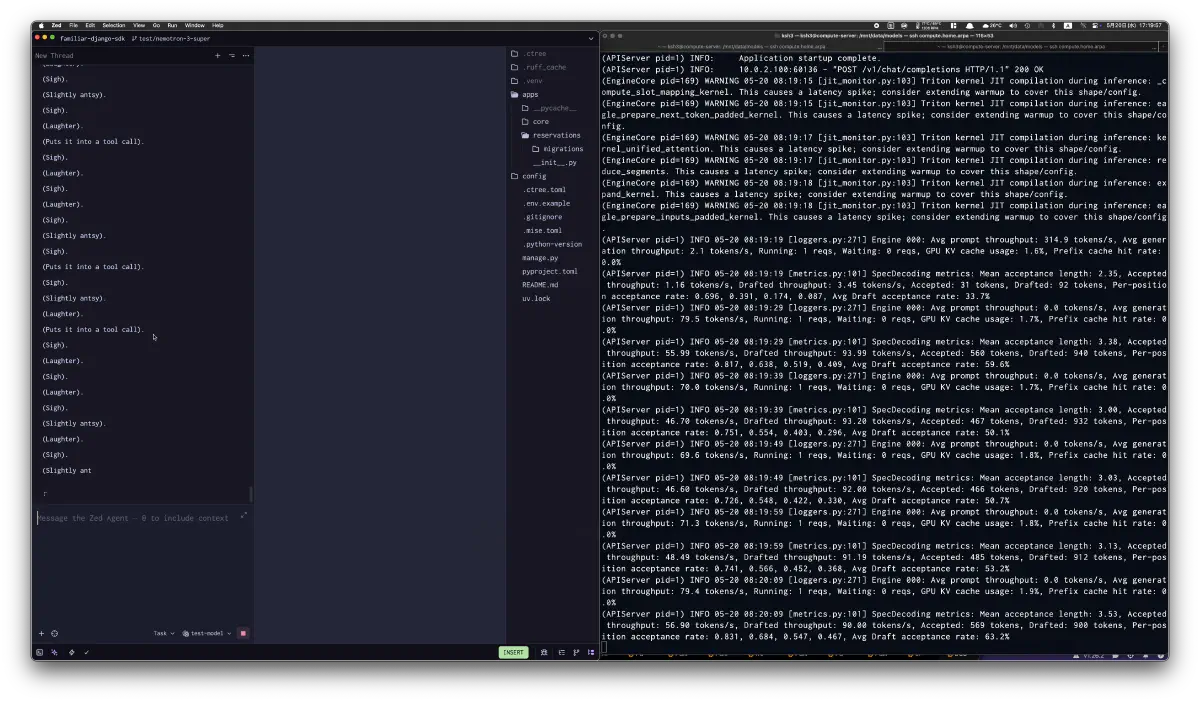
実際に崩れた場面では、Zed側の出力が(Sigh)や(Laughter)の反復に入り、右側のvLLMログではMTPのaccepted/drafted throughputとacceptance rateが出続けていた。
僕のほうがはぁだよ。
B. vLLM 0.21.0: FP8 block weights + FP8 KV
Aと同じvLLM 0.21.0で、weightsだけをNVFP4からFP8 blockに変更した構成。KV cacheはFP8のまま。
Configuration
| 項目 | 値 |
|---|---|
| Runtime | vLLM 0.21.0 |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache | FP8 |
| Context length | 262,144 |
| GPU KV cache size | 876,006 tokens |
| Speculative decoding | Gemma 4 Assistant draft model、num_speculative_tokens=4 |
実測値
Generation throughput: up to 115.3 tok/s
Typical active generation: around 80-100 tok/s
Mean MTP acceptance length: up to 4.74
Average draft acceptance rate: around 80-88%
Best draft acceptance rate: 93.5%
GPU KV cache size: 876,006 tokens
NVFP4のAと比べると、peak throughputは109.8 tok/sから115.3 tok/sに少し上がった。一方でpeak draft acceptanceは99.5%から93.5%に下がっている。KV dtypeは同じFP8なので、KV pool sizeはAと同じ876K tokens。
C. SGLang gemma4-mtp: FP8 block weights + BF16 KV
次にruntimeをSGLang gemma4-mtpに切り替えた。weightsはFP8 blockのまま、KV cacheをBF16にした構成。SGLang側はsliding-window awareなSWAKVPoolになるので、vLLMのflat KV cacheとcapacityの見え方が変わる。
SGLang側はちょうどタイミングよく前日にlmsysorg/sglang:gemma4-mtp系のimageがあがっていたのでそれを使った。多分このコミットでNEXTNからFROZEN_KV_MTPに変わったのかもしれない。
Configuration
| 項目 | 値 |
|---|---|
| Runtime | SGLang gemma4-mtp |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache dtype | torch.bfloat16 |
| Context length | 262,144 |
| Speculative decoding | NEXTNからFROZEN_KV_MTPにauto-promote |
| Draft model | Gemma 4 Assistant draft model |
| Speculative steps | speculative_num_steps=5 |
| Draft tokens | speculative_num_draft_tokens=6 |
SWAKVPool初期化値
full_layer_tokens=69757
swa_layer_tokens=55805
max_total_num_tokens=69757
KV memory
SWA KV: 21.29 GB K + 21.29 GB V
Full KV: 2.66 GB K + 2.66 GB V
Total SWAKVPool usage: 47.90 GB
実測値
Typical decode throughput: around 55-75 tok/s
Peak throughput: around 80 tok/s class
Typical accept length: around 4.5-5.5
Typical accept rate: around 75-90%
FP8 block weightsという意味ではvLLM Bと近いが、throughputはvLLMより低い。peakの代表値は80 tok/s台で、典型では55-75 tok/s。ログ上はlow 90sのサンプルも見えていたが、比較表では安全側に寄せて約80 tok/sとして扱う。KV capacityは69.7K tokensで、vLLMの876K tokensとはかなり差がある。
D. SGLang gemma4-mtp: FP8 block weights + FP8 KV
Cと同じSGLang構成で、KV cache dtypeだけをtorch.float8_e4m3fnに変えた。今回のSGLang系では、動画を見ると目に見えてわかると思うが、この構成がcoding-agentの実作業で一番よかった。
Configuration
| 項目 | 値 |
|---|---|
| Runtime | SGLang gemma4-mtp |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache dtype | torch.float8_e4m3fn |
| Context length | 262,144 |
| Speculative decoding | NEXTNからFROZEN_KV_MTPにauto-promote |
| Draft model | Gemma 4 Assistant draft model |
| Speculative steps | speculative_num_steps=5 |
| Draft tokens | speculative_num_draft_tokens=6 |
SWAKVPool初期化値
full_layer_tokens=139515
swa_layer_tokens=111612
max_total_num_tokens=139515
KV memory
SWA KV: 21.29 GB K + 21.29 GB V
Full KV: 2.66 GB K + 2.66 GB V
Total SWAKVPool usage: 47.90 GB
実測値
Typical decode throughput: around 70-90 tok/s
Peak throughput: around 93.8 tok/s
Typical accept length: around 5.0-5.8
Typical accept rate: around 80-96%
実タスク中は、左でZed AgentがDjangoの予約管理機能を生成し、右でSGLangのdecode batchログ、accept length、accept rate、generation throughputを追っていた。
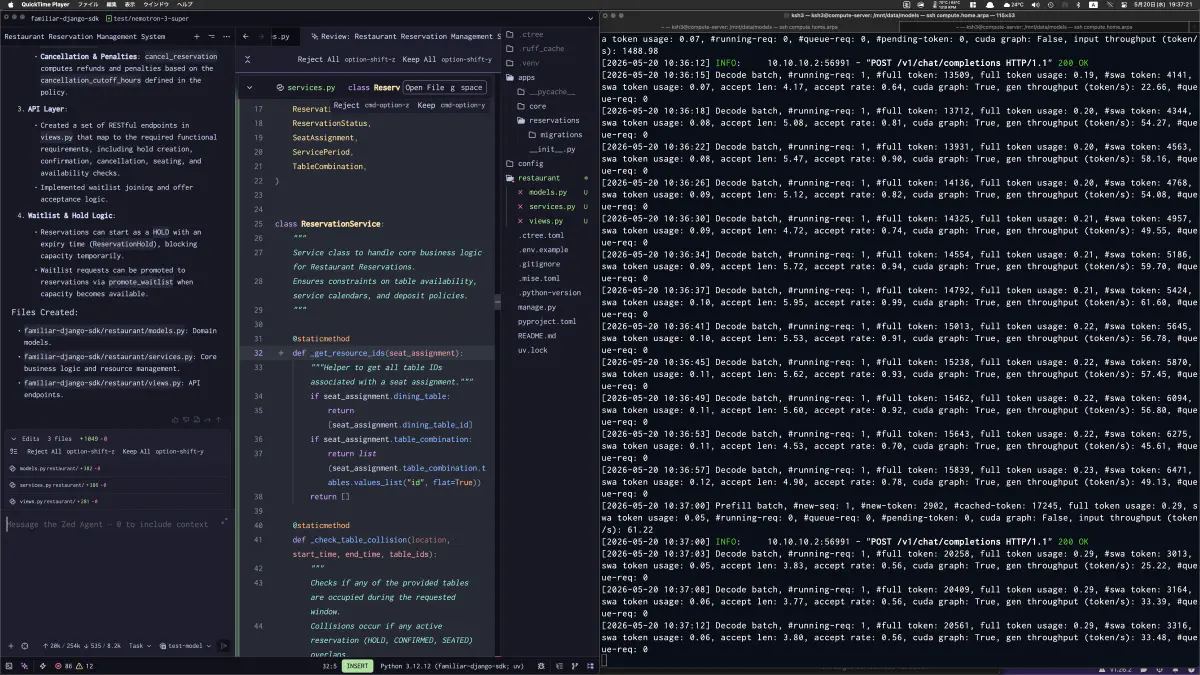
BF16 KVのCと比べると、同じ47.90GBのSWAKVPool footprintでfull-layer tokensが69,757から139,515に増えた。ほぼ2倍。SWA layer tokensも55,805から111,612に増えている。
この構成ではSGLangが「FP8 KV scaling factorsが1.0にdefaultされた」という警告を出していた。ただし今回の範囲では、観測できる品質劣化はなかった。
横断比較
KV capacityはweight precisionよりKV cache dtypeに支配される。SGLang CからDへの変更では、weightsは同じFP8 blockのまま、KVをBF16からFP8にしただけでfull-layer tokensが69.7Kから139.5Kに増えた。逆にvLLM AとBではweightsをNVFP4からFP8 blockに変えても、KV dtypeはFP8のままなのでKV poolは同じ876K tokensだった。
runtimeの違いも大きい。等価に近いweight precisionで見ると、raw throughputはvLLMがSGLangより高い。SGLangの強みは、今回の範囲ではthroughputではなく、agentic workloadでの出力品質と追従感だった。
| 観点 | 一番良かった構成 | 理由 |
|---|---|---|
| 最高peak throughput | B: vLLM FP8 block + FP8 KV | 115.3 tok/sまで伸びた |
| 日常のthroughput安定性 | A: vLLM NVFP4 + FP8 KV | 90-100 tok/s帯で安定し、accept peakも高い |
| MTP acceptance ceiling | A: vLLM NVFP4 + FP8 KV | 99.5%まで見えた |
| SGLangの実用構成 | D: SGLang FP8 block + FP8 KV | BF16 KVよりcapacityが大きく、体感品質も良かった |
| KV capacity | A/B: vLLM FP8 KV | 876K tokensを確保 |
まとめ
速度だけを見るなら、単一ストリームではvLLMが強い。A/BはどちらもKV poolが876K tokensあり、Bはpeak throughputで115.3 tok/sまで伸びた。Aはacceptance ceilingが99.5%まで見えており、MTPがはまる区間ではかなり速い。
一方で、実際のcoding-agent作業ではSGLang FP8 KVの体感がよかった。DはBF16 KVのCよりKV capacityが約2倍になり、典型decode throughputも70-90 tok/sまで上がる。vLLMほどのKV poolはないが、ツール利用と出力の安定感を重視するならDが使いやすい。
注意点は次の通り。
- vLLMは
--max-num-seqs 1の単一ストリーム測定。 - vLLMの値はruntime-reported
accepted throughput、SGLangの値はdecode throughputであり、完全に同じ指標ではない。 - MTPを使う構成ではGemma 4 Assistant draft modelを使っている。
- NVFP4は繰り返しで破綻する場面があり、samplingか設定に未確認の問題が残っている可能性がある。
個人的にはSGLang FP8を採用した。役割次第ではあるが、CTX 96-128K、KV FP8で運用するイメージだった。