GLM-5.1 IQ3_KS をローカルで動かす: CPU/GPU Hybrid 推論と expert layer 配置
GLM-5.1 IQ3_KS (744B MoE) を dual RTX PRO 6000 Blackwell Max-Q (96GB×2) + 768GB RAM の homelab で動かした実測記録。expert の head+tail GPU 配置で TG 17–19 tok/s を安定させ、Qwen3.5-397B-A17B との比較から familiar の常駐 orchestrator としては Qwen3.5 を採用する方向性までまとめた。

GLM-5.1 IQ3_KS (744B MoE, 320 GiB) を dual RTX PRO 6000 Blackwell Max-Q (96GB×2) + 768GB RAM の homelab で動かし、CPU/GPU hybrid 構成で TG 17–19 tok/s を安定させた。この記事では ik_llama.cpp での expert layer の head+tail GPU 配置、実測ベンチマーク、そして自作エージェントシステム familiar の常駐 orchestrator (grandpa) として Qwen3.5-397B-A17B と比較した。
動画リンク: https://www.youtube.com/watch?v=1JRyuCUlFeI
Hardware
| Component | Spec |
|---|---|
| CPU | AMD EPYC 9175F (16C) |
| RAM | 768GB DDR5-6400 |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB × 2 |
Model
GLM-5.1 は Zhipu の GLM 系列 MoE モデル。ik_llama.cpp の起動ログ上では n_expert = 256、n_expert_used = 8。
| Item | Value |
|---|---|
| Architecture | glm-dsa (MoE, 256 experts, 8 active) |
| Parameters | 753.864B |
| Quantization | IQ3_KS (3.65 BPW) |
| Model size | 320.216 GiB |
| Context | 65536 (max 202752) |
| GGUF | ubergarm/GLM-5.1-GGUF |
| Runtime | ik_llama.cpp |
Expert Layer 配置: Head偏重+微Tail GPU パターン
GLM-5.1 は 79 layer (blk.0–blk.78) 構成で、blk.0–blk.2 が dense、blk.3–blk.78 が MoE 層。
--cpu-moe で expert を CPU デフォルトに落としつつ、-ot で個別 tensor を GPU に戻す。今回のテスト構成は head 側 15 層 (blk.3–blk.17) を CUDA0、tail 側 4 層 (blk.74–blk.77) を CUDA1 に置き、中間 56 層は CUDA_Host (pinned host memory) に残す。
OT_ARGS=""
for i in $(seq 3 17); do
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_gate_exps=CUDA0"
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_down_exps=CUDA0"
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_up_exps=CUDA0"
done
for i in $(seq 74 77); do
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_gate_exps=CUDA1"
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_down_exps=CUDA1"
OT_ARGS="$OT_ARGS -ot blk.$i.ffn_up_exps=CUDA1"
done
配置結果 (1 MoE 層あたりの exps は gate 1,225 + down 1,638 + up 1,225 = 4,088 MiB):
| Device | Role | Buffer Size |
|---|---|---|
| CUDA0 | blk.0–2 dense + blk.3–17 experts (head 15 層) + attn/KV | 68,698 MiB (~67.1 GiB) |
| CUDA1 | blk.74–77 experts (tail 4 層) + attn/KV | 23,473 MiB (~22.9 GiB) |
| CUDA_Host | 中間層 experts (56 層分) | 229,438 MiB (~224.1 GiB) |
GPU 側 exps は 19 層で 77,672 MiB (~75.9 GiB)、CPU pinned host には 56 層分 = 228,928 MiB の exps が載り、合計で log 上の CUDA_Host 229,438 MiB に一致する。全 exps を CPU に落とした時の理論値は 76 × 4,088 = 310,688 MiB (~303.4 GiB) で、今回は -ot で 76 GiB 分を GPU に戻した形になる。
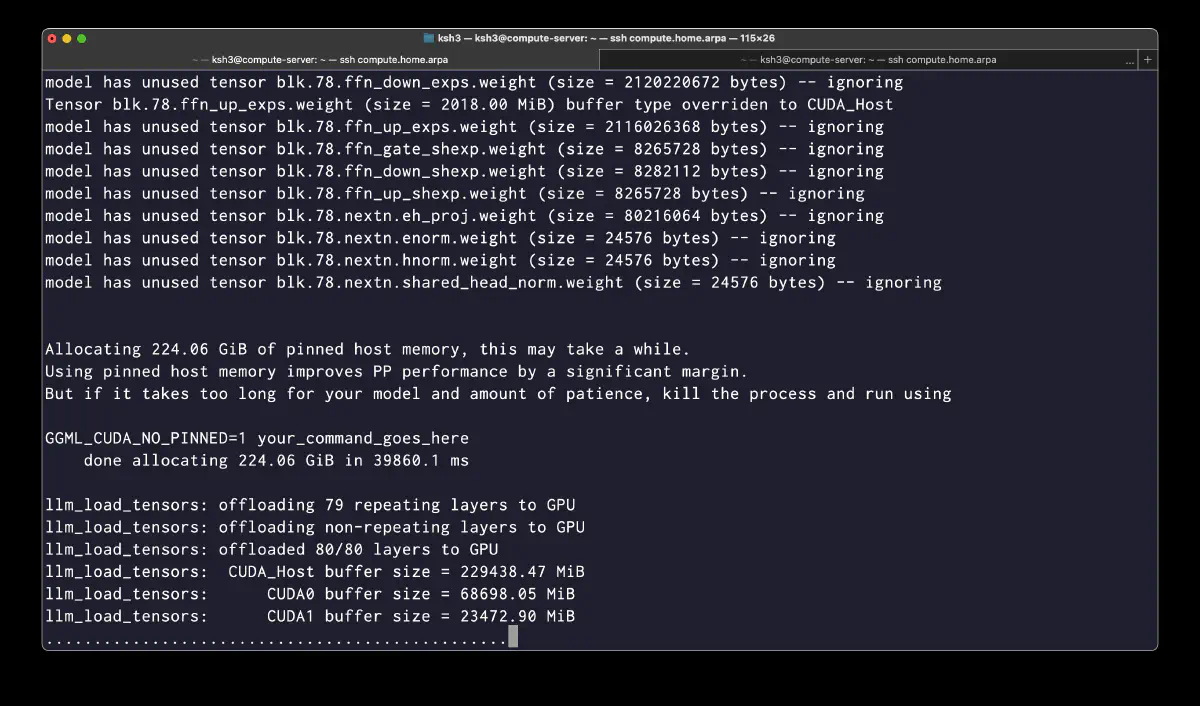
起動コマンド
podman run --rm \
--device nvidia.com/gpu=all \
-p 8000:8000 \
--cap-add=SYS_NICE \
-v /mnt/data/models/models--ubergarm--GLM-5.1-GGUF:/models:ro,Z \
registry.home.arpa/ik_llama.cpp:latest \
-m /models/.../IQ3_KS/GLM-5.1-IQ3_KS-00001-of-00008.gguf \
--ctx-size 65536 -ctk q8_0 -ctv q8_0 \
--parallel 1 --threads 15 --threads-batch 24 \
-b 8192 -ub 8192 -ngl 99 --cpu-moe \
$OT_ARGS \
-ger -muge -amb 512 --jinja \
--host 0.0.0.0 --port 8000 \
--warmup-batch --alias glm-5.1
オプションフラグ:
--cpu-moe: expert を CPU 側にデフォルト配置-ot blk.N.ffn_*_exps=CUDAX: 個別の expert tensor を GPU に override-ger -muge: grouped expert routing + multi-GPU expert-amb 512: attention memory budget--warmup-batch: 起動時にバッチ warmup
Django アプリ生成
運送業関連のテナントモジュール (モデル定義、admin、テスト、シードデータ) を一から生成させる実タスクで計測した。Zed エディタ上でzed agent利用。
Token Generation (TG)
| Metric | Value |
|---|---|
| Requests | 46 |
| Total generated tokens | 16,092 |
| Total prompt tokens | 131,985 |
| TG min | 16.39 tok/s |
| TG max | 19.38 tok/s |
| TG median | 17.94 tok/s |
| TG mean | 17.77 tok/s |
| ms/token range | 52–61 ms |
最大の生成は 8,884 tokens (PP 435 tok/s, TG 17.26 tok/s) で、約 8.5 分かけて Django models.pyコードを出力した。
TG の安定性
TG はセッションを通じて安定していたが、序盤と終盤で約 2 tok/s の低下がある。53k/64kでこれならかなり良い。
- 序盤 10 リクエスト: 18.23–18.97 tok/s (平均 18.74)
- 終盤 10 リクエスト: 16.39–16.86 tok/s (平均 16.69)
KV cache の蓄積とコンテキスト長の増大が原因と考えられる。それでも 16 tok/s を割ることはなかった。
Prompt Processing (PP)
| Prompt Size | PP Range |
|---|---|
| < 100 tokens | 19–37 tok/s |
| 100–1,000 | 54–143 tok/s |
| 1,000–5,000 | 114–280 tok/s |
| 5,000–10,000 | 235–572 tok/s |
PP は prompt が長いほど throughput が上がる。初回投入 (20,956 tokens) では 571.94 tok/s を記録。短い prompt では overhead が相対的に大きくなる。
Cache Miss 問題
ログ上で 26 回の prefix cache miss が発生していた。
Common part does not match fully
cache : ...<|assistant|><think></think>...
prompt: ...<|assistant|></think>...
<think> タグの有無・位置のズレで prefix が壊れ、7k–10k token 級の prompt 再評価が発生する。これが TTFT を 1 秒台から 40 秒台まで押し上げる最大の原因。
| Prompt Tokens | TTFT (est.) |
|---|---|
| 23 | 1.05 s |
| 7,487 | 17.25 s |
| 9,247 | 39.28 s |
| 9,761 | 40.87 s |
GPU メトリクス
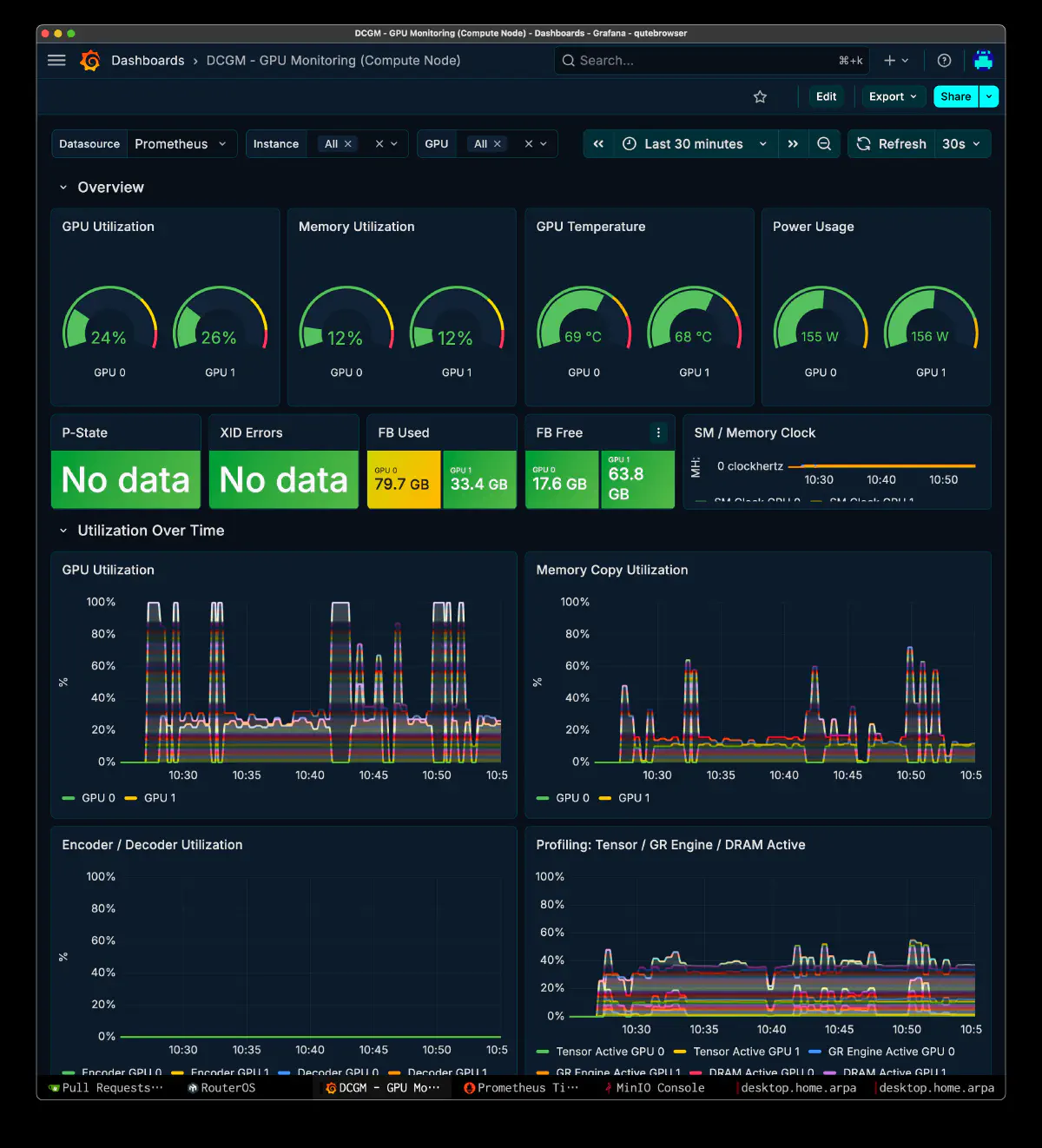
GPU utilization は常時張り付きではなく、リクエストごとに波打つパターン。これは hybrid 構成の特徴で、host 側 expert の読み出しとの interleave が発生するため。
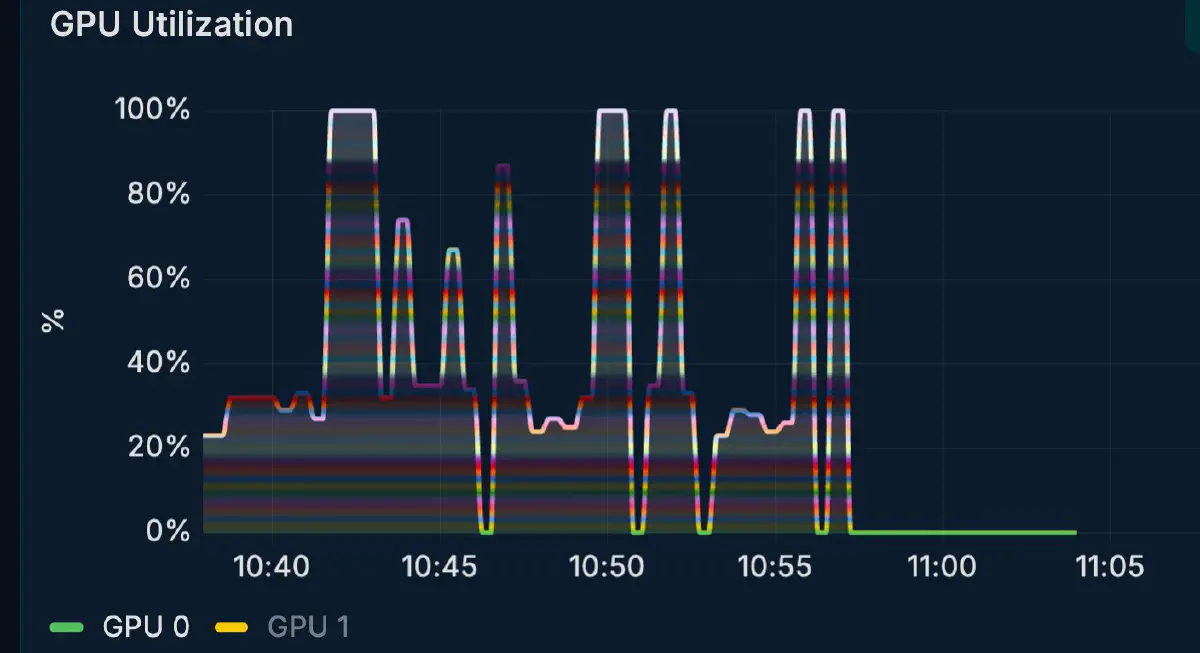
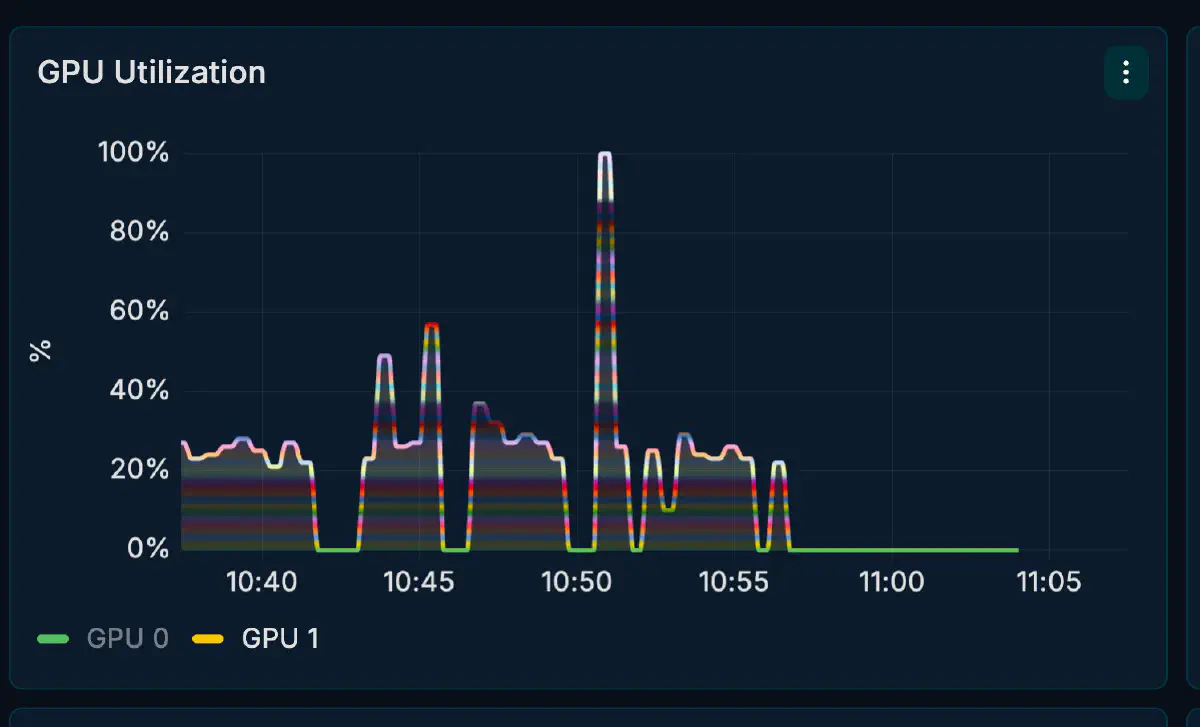
CUDA0 に 68.7 GiB、CUDA1 に 23.5 GiB のモデルバッファが載っており、head 側 (CUDA0) のほうが VRAM 使用量・利用率ともに高い。tail 側の CUDA1 には 70 GiB 以上の余裕があり、coder モデルや他のサービスと併走する余地がまだ残る。
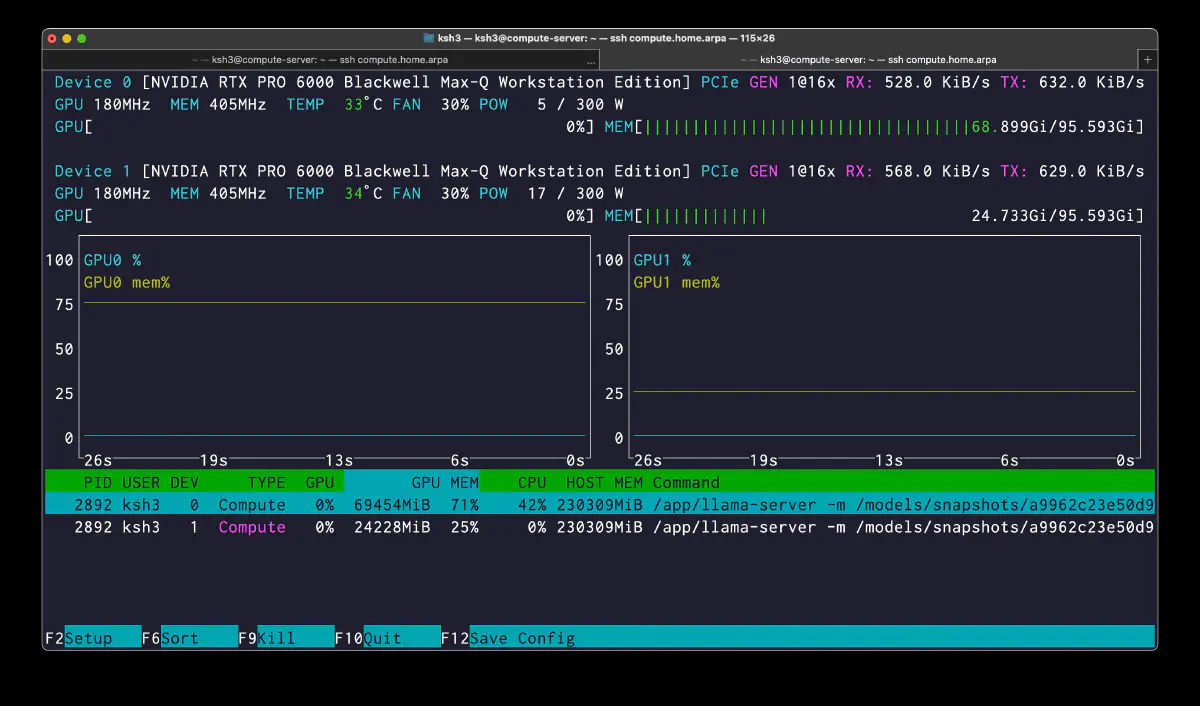
CPU / Host Memory
CPU は計算の主役ではなく、host-resident expert tensor の供給と pinned memory の保持を担当している。利用率が高くても、それは expert の DMA 転送と runtime orchestration のため。
推論環境は 4 ノードの homelab 上で動いている。compute.home.arpa (GPU server) で推論、storage.home.arpa で PostgreSQL / Prometheus / MinIO / Dagster / MLflow、desktop.home.arpa で Grafana を動かしている。
Orchestrator 選定: GLM-5.1 vs Qwen3.5-397B
このベンチマークにはもう一つの目的があって、自作のエージェントオーケストレーションシステム familiar の常駐オーケストレーター (grandpa) としてのモデル選定を兼ねている。候補は GLM-5.1 (744B-A40B) と Qwen3.5-397B-A17B の 2 つ。
grandpa はタスクの分解、coder モデルへの委譲判断、生成結果の品質評価、エラー時のリカバリを担う役割で、長時間常駐しながら 2 つの LLM バックエンドを協調させて使うことを想定している。求めているのはタスクスケジューリング・状態管理・コンテキストマネージングの能力で、ctx を大きく取ることや長文生成そのものは coder に任せたい。この使い方では GPU 側には少しだけ余裕があればよく、hot な layer だけ割り当てる感覚。ざっくり dev01:25/25 GB くらいで収まる構成をイメージしている。
スペック比較
| GLM-5.1 | Qwen3.5-397B | |
|---|---|---|
| Total / Active params | 744B / 40B | 397B / 17B |
| Experts / Active | 256 / 8 | 512 / 10 |
| Quantization | IQ3_KS (3.65 bpw) | Q4_K_M mixed (4.93 bpw) |
| Model size | 320 GiB | 228 GiB |
| n_ctx_train | 202,752 | 262,144 |
| License | MIT | Apache-2.0 |
テスト構成の違い
比較を正しく読むために、2 モデルの実測構成は分けて書く。
GLM-5.1 (今回の構成): --cpu-moe + -ot で head 15 層 + tail 4 層の expert を GPU に戻している。GPU 側 exps 19 層 ≈ 76 GiB、CPU pinned host 側 exps 56 層 ≈ 224 GiB (log 上 CUDA_Host 229,438 MiB)。これは orchestrator 専用ではなく coding bench 向けに組んだ配置。
Qwen3.5-397B (別セッションの構成): --n-cpu-moe 15 を指定した起動ログでは、blk.0–blk.14 (先頭 15 層) の exps が CUDA_Host に配置され、残り 45 層 (blk.15–blk.59) の exps は GPU 側に載った。Qwen3.5 は full_attention_interval = 4 の hybrid 構造で attention の種別は 4 層おきに切り替わるが、exps 自体は全 60 層が持つ (ログの Layer sizes でも Layer 3, 7, 11... の行に 3,839 MiB の exps 成分が計上されている)。非 exps (attention、SSM、dense、output) は graph split で両 GPU に分散され、CUDA_Split で 176 GiB を確保。CUDA_Host の実測は 56,710 MiB で、15 × 3,712 MiB = 55,680 MiB と概ね一致する。
つまり GLM-5.1 のほうは「大半の expert を CPU」、Qwen3.5 のほうは「先頭 15 層の expert だけ CPU」で動かしている。どちらもフル CPU ではなく、CPU pinned 量はテスト構成の違いで大きく変わる。orchestrator 用途を見据えるときは、両方を expert 完全 CPU に揃えた時の VRAM 要件を別途見積もる必要がある。
Expert 全 CPU 時の VRAM 要件
両モデルの起動ログの Layer sizes から非 exps 部分のみを合算し、KV cache と compute buffer を足した VRAM 要件。
| GLM-5.1 | Qwen3.5-397B | |
|---|---|---|
| Non-exps weight (attn+dense+output) | 6,518 MiB | 7,058 MiB |
| KV per 1k ctx (q8_0) | ~46 MiB | ~16 MiB |
| KV cache (ctx 65k, q8_0) | 2,984 MiB | ~1,040 MiB |
| KV cache (ctx 200k, q8_0, est.) | ~9,228 MiB | ~3,200 MiB |
| KV cache (ctx 262k, q8_0) | — | 4,080 MiB |
| Compute buffer | ~12 GiB | ~11 GiB |
| VRAM total (exps=CPU, ctx 65k) | ~22 GiB | ~19 GiB |
| VRAM total (exps=CPU, ctx 200k) | ~28 GiB | ~21 GiB |
| VRAM total (exps=CPU, ctx 262k) | — | ~22 GiB |
Qwen3.5 は attention が hybridで KV 効率が良く、16 MiB/1k に収まる。GLM-5.1 は MLA 相当の attention を持っているが、ヘッド数・dim が大きく KV は 46 MiB/1k と重い。結果として ctx 200k 運用だと GLM-5.1 が +7 GiB ほど重くなる。
CPU Pinned Host の差
| GLM-5.1 | Qwen3.5-397B | |
|---|---|---|
| Exps per layer | 4,088 MiB | 3,712 MiB (+一部 3,839 MiB) |
| Exps 保持層数 | 76 (blk.3–blk.78) | 60 (全層) |
| Total exps (全 CPU 時、理論値) | ~303 GiB | ~218 GiB |
| 本テストでの CPU pinned | 229 GiB (56 層) | 55 GiB (15 層) |
| Pinned alloc time (test) | 40s | 9s |
推論性能
| GLM-5.1 | Qwen3.5-397B | |
|---|---|---|
| TG (序盤) | 18–19 t/s | 55–59 t/s |
| TG (終盤、ctx 充填時) | 16–17 t/s | 17–18 t/s |
| PP max | 572 t/s | 1,500 t/s |
| Cache restore | N/A | 14–18 ms (checkpoint) |
| Cache miss | <think> タグ不整合で頻発 | checkpoint restore で安定 |
序盤の TG 差は大きいが、長いセッションでは両方とも 17–18 t/s に収束する。orchestrator の出力は短い (委譲指示、ルーティング判断) ので、TG の絶対値よりも思考の質のほうが効いてくる気がする。
Qwen3.5 の PP が 3 倍速いのは cache miss 時のリカバリに効く。GLM-5.1 の cache miss は <think> タグ起因なので、thinking off で起動すれば解消する余地はありそう。
思考の質
インフラ面の数字だけを見れば Qwen3.5 が有利に見える。PP 3 倍、CPU pinned 軽い、ctx 262k、cache 安定。一方で orchestrator に求めているのは、タスクを下位ワーカーにスケジューリングし、状態を管理し、ctx をマネージングする仕事だ。
GLM-5.1 は active 40B、Qwen3.5 は active 17B。タスク分解の精度、エラーリカバリの戦略立案、生成結果の品質評価といった判断タスクは active parameter 数の影響を受けやすく、ctx に情報を詰め込めば解決するものでもない。地頭で考えれば GLM-5.1 を選びたくなるが、賢さと「常駐で走り続けられるか」はまた別の話で、結局のところ実運用で動かして観測・記録・評価を繰り返すしかないと感じている。今のところの肌感覚だと Qwen3.5 のほうが長く生き残りそう、というのが正直なところ。
ctx 戦略: RAG で軽くするか、詰め込むか
n_ctx_train は GLM-5.1 で 202k、Qwen3.5 で 262k。ctx max の 70% 程度を実効上限とすると、GLM-5.1 は約 141k、Qwen3.5 は約 183k が使える。差は大きいが、どちらも「全ての情報を入れる」には十分広い。問題は運用方針だ。
GLM-5.1 + RAG shaping (ctx ~64k 運用):
orchestrator に必要な情報だけを RAG で引いて渡す方針。Gitea にコードを集約し、ColBERT + maxsim reranker でインデックスしている前提で、argus (Gitea symbol DB) と voracle (Obsidian vault semantic search) が常時インデックスを保持しており、orchestrator はこれらの MCP tool を叩いて必要なコンテキストだけを取得する。ctx を 64k 程度に抑えれば KV cache は ~3 GiB に収まり、TTFT も短く、TG の劣化も最小限。
この使い方なら Mac Studio でも成立しそう。unified memory で CPU/GPU の境界が薄い分、ctx を絞って軽く回す方針なら取り回しはむしろ良いかもしれない。
Qwen3.5 + power play (ctx ~183k):
会話履歴も tool 結果もコードも ctx に入れてしまう方針。情報の取捨選択を省ける分、orchestrator 側の判断負荷が下がる。active 17B でこの量の情報を適切にフィルタできるかは未知数で、ここは実運用で観測するしかない。KV が軽いので、YaRN で 1M ctx まで伸ばしても容量面の余地はあるが、そのサイズでの品質維持は別の課題になる。
選定の方向性
今のところは Qwen3.5-397B-A17B を grandpa (常駐 orchestrator) に置く方向 で検討している。地頭 (active params) だけ見れば GLM-5.1 の active 40B が有利だが、「常駐して他のモデルと協調させる」役割では Qwen3.5 の特性のほうが噛み合いそう、というのが現状の感触。
- ctx 262k + KV が軽い: KV 16 MiB/1k なので ctx を広く取る余地があり、画像を扱う使い方にも寄せやすい
- PP 1,500 t/s: cache miss 時のリカバリが GLM-5.1 比 3 倍速い。orchestrator は頻繁に system prompt や stack 中の messages[] を書き換えるので、再評価の安さがそのまま体感レイテンシに効く
- ライセンスと最適化: どちらも MIT / Apache-2.0 で SFT/DPO/LoRA の flywheel として使えるが、GLM-5.1 は規模的にファインチューニングの試行錯誤が費用面で厳しい。Qwen3.5-397B-A17B はぎりぎり射程に収まる
進捗具合
開発を始めて 2 ヶ月ほど経過した。平日の空きが週 2 しかないので土日も含めて手を動かしている感じだけど、ローカル LLM 向けの MCP ツールを claude や codex と一緒に作り込んでみて、改めて感じたのは「ctx は小さく、高密度に、そしてタイミングを制御する」ことが肝心だということ。いちばん試行錯誤しているのはモデル間のオーケストレーションをどう協調させるかで、散歩しながら思索し、壊しては作り直しを繰り返す日々。これがとても楽しい。
まとめ
GLM-5.1 IQ3_KS は head 15 + tail 4 の expert GPU 配置で TG 17–19 tok/s を安定して出せた。 おそらくだが、head側寄りにGPUに載せておくとヒットしやすいと思う。Active40Bでそれなりの重さはあるが、 RAGとあわせてctxを小さく運用するにはすごく良いと思う。
自作の familiar の常駐 orchestrator (grandpa) には、今のところ Qwen3.5-397B-A17B を置く方向で検討している。active 40B の思考力は GLM-5.1 が勝るが、ctx 262k と KV 16 MiB/1k、PP 1,500 t/s、cache checkpoint restore、余力的側面もあって Qwen3.5 に寄っている。
あとは実運用で動かして、委譲成功率・リカバリ回数・セッション長あたりのメトリクスを見ながら、この方向性で良いかを検証、データ集め、ツール最適化などやることは山積みだ。