Kimi-K2.6 をローカルで実行: ik_llama.cpp と Blackwell で 1T MoE を実用化する
Kimi-K2.6 (1T MoE, 384 experts × 8 active) を IQ3_K / Q4_X で RTX PRO 6000 Blackwell Max-Q 96GB 環境に載せ、ik_llama.cpp の MLA 最適化、expert tensor 配置、mainline llama.cpp との差、Django 生成タスクでの実用性をまとめた。

Moonshot AI の Kimi-K2.6 は 1T 級の MoE モデルで、384 expert のうち 8 つだけを活性化する DeepSeek2 系アーキテクチャ。総パラメータは重いが、活性パラメータは絞られているので、CPU メモリと GPU VRAM の役割分担をうまく作れれば、ソロ開発者のローカル worker として現実的な速度まで持っていける。
今回は ubergarm/Kimi-K2.6-GGUF の IQ3_K と Q4_X を、EPYC 9175F + RTX PRO 6000 Blackwell Max-Q 96GB x 2 で検証した。見たかったのは、ik_llama.cpp で MLA と expert placement を使ったときに、実際の coding task でどこまで崩れずに回るかだった。Vision未対応なのでtext-generationのみサポート。mainlineは対応しているので–no-cacheでビルドして試したがtool_call_parserが壊れていたので後日。
動画リンク: https://www.youtube.com/watch?v=skTE19_JRYg
動画の内容を先に要約すると、今回の検証は RTX PRO 6000 Blackwell Max-Q 96GB + EPYC 9175F + 768GB DDR5-6400 上で、Kimi-K2.6 (1T MoE, 384 experts × 8 active) を ik_llama.cpp でいくつかのパターンを試して、実用的な歩留まりのIQ3_Kに決めて、最後動画を撮った。ubergarmさん の IQ3_K (3.85 bpw, 460 GiB) を中心に、expert layer を 4 〜 10 層だけ GPU に戻し、それ以外を CPU pinned memory に置く head/tail split を試した。
- TG は
17.9〜21 t/s、PP cold は223〜377 t/s。-ubサイズと-ot配置で大きく変わる 14,707tokens の連続生成でも19.57 t/sを維持し、long generation でも崩れにくかった。自作のMCPツールのみで、あまりコールされないことが多いが、これはローカルネットワークにあるgiteaにISSUE/MS/PRまで自力で作れるから本当にすごい。opus4.6みたいなツールの使い方でTGがもう少しでればといったところ。256k qtv ctv f16でも確かvram 150GBいかないくらいだったIQ3_Kは TG17.9〜20.9 t/s、Q4_Xは16.6〜19.0 t/sで、最終的にはIQ3_Kを優先した。ぱっと見だけどあまり差は感じなかった。同一のAGENTS.mdを与えてほぼ同じ動きだった- 実タスクでは
real_estate_salesモジュールを生成し、15 models / 772 lines のv6対応したちゃんとした Django コードを生成できた - ライセンスは Modified MIT だが、月商30億 または
100M MAU以下なら商用で使えるし、その規模まで行ったら出口はあるのでほぼMIT
検証環境
| 項目 | 構成 |
|---|---|
| CPU | AMD EPYC 9175F (16C/32T L3 512MB, Zen 5) |
| RAM | 768 GB DDR5-6400 ECC RDIMM |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x 2 |
| OS | Ubuntu 24.04-LTS (minimal) |
| Runtime | ik_llama.cpp |
モデル側の前提は次のとおり。
| 項目 | 値 |
|---|---|
| モデル | Kimi-K2.6 |
| アーキテクチャ | DeepSeek2 系 MoE + MLA |
| 総パラメータ | 1T class |
| Experts / Active | 384 / 8 |
| 主な量子化 | IQ3_K (3.85 bpw), Q4_X (4.55 bpw) |
なぜ mainline llama.cpp ではなく ik_llama.cpp なのか
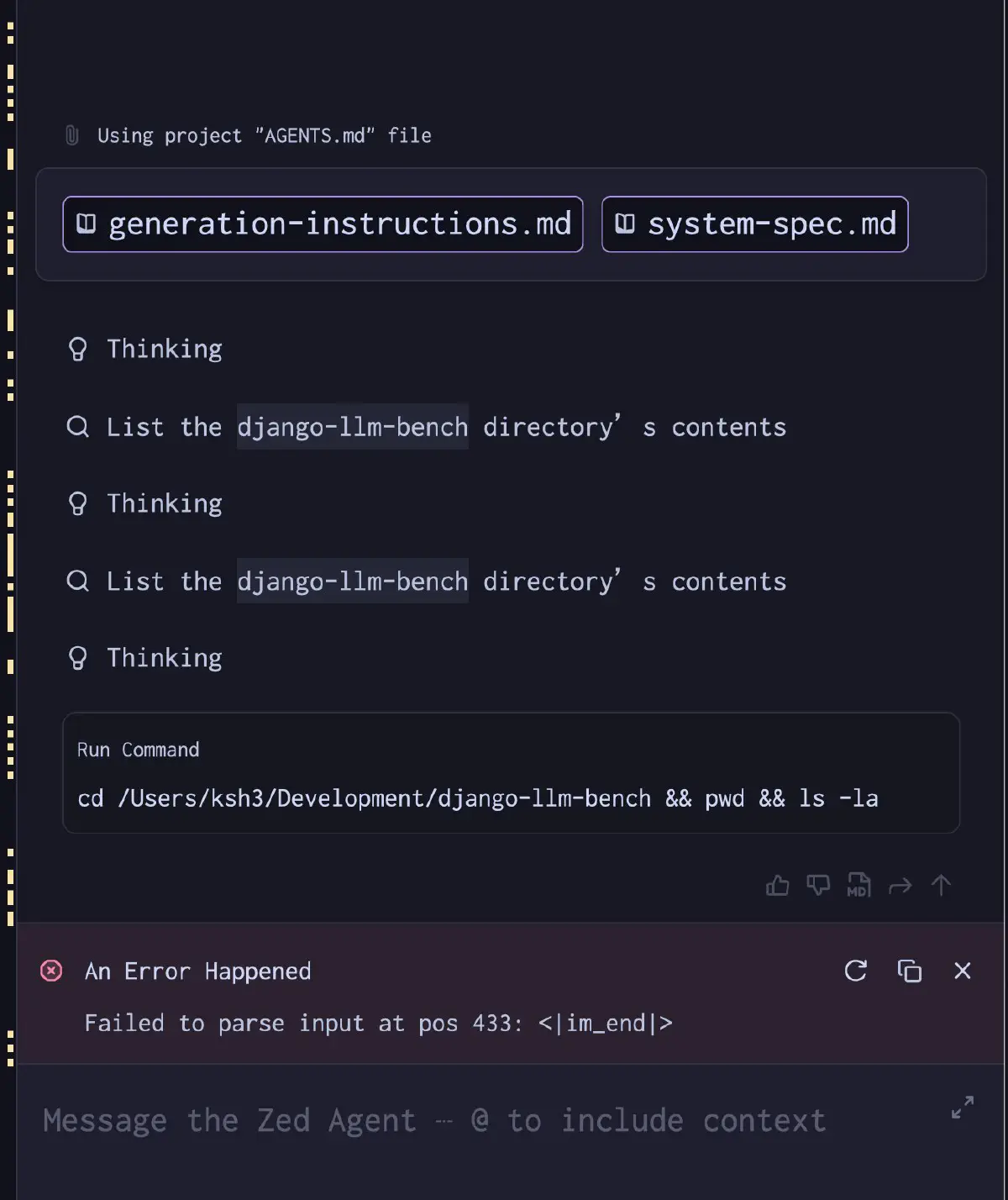
Kimi-K2.6 は DeepSeek2 アーキテクチャの MLA(Multi-head Latent Attention)を採用しており、推論エンジン側に専用の対応が要る。mainline llama.cpp でもモデルの読み込みと起動はできるが、 MLA 吸収モード(-mla 3)に相当するフラグがないため standard KV path で処理され、TG が本来の性能を出せない。さらに深刻なのが chat template parser の問題で、Kimi-K2.6 の <|tool_call_begin|> 系 special token を peg-native parser が処理できず、tool_call を含むレスポンスで Failed to parse input at pos 433: <|im_end|> を出してクラッシュする。–no-cache でビルドし直しても解消しなかった。(2026/04/22) template周りだと思うので、しばらくしたら再度落として試してみるとよいかと。
Failed to parse input at pos 433: <|im_end|>
Expert Tensor Placement が TG を決める
Kimi-K2.6 のような巨大 MoE を CPU/GPU hybrid で回すと、どの expert layer を GPU に戻すかで TG が変わる。全 expert を CPU pinned memory に置いたベースラインでは、生成は成立しても decode が伸びにくい。そこで head 側と tail 側の expert を -ot で GPU に戻し、CPU 側には中間層だけを残す配置を試した。
ベンチ結果
| Config | Expert on GPU | TG avg (t/s) | PP cold (t/s) | VRAM/GPU |
|---|---|---|---|---|
Baseline (--cpu-moe) | 0 層 | 18.9 | 185 | ~11 GiB |
| 6-layer head/tail split | 6 層 (3+3) | 20.9 | 223 | ~52/60 GiB |
| 10-layer head-heavy | 10 層 (8+2) | 20.3 | 377 | ~43/44 GiB |
6-layer の balanced split が TG では最良だった。10-layer の head-heavy は -ub 4096 と組み合わせたときの PP がかなり伸びる一方で、decode は head に寄せすぎたぶん少し鈍った。
最終的に残した -ot 配置
-ot "blk\.(1|2)\.ffn.*=CUDA0" \
-ot "blk\.(59|60)\.ffn.*=CUDA1" \
-ot "exps=CPU"
CUDA0 に head 2 層(blk.1-blk.2)、CUDA1 に tail 2 層(blk.59-blk.60)を置く。残り 56 層の expert は CPU pinned memory に残す。 この構成だと、Blackwell 96GB × 2 のうち片側 39 GiB 台後半、もう片側 35 GiB 弱を使いながら、decode を 17-19 t/s 台に乗せやすい。1T 級モデルをローカルで常駐させるときに、GPU を完全に埋めきらず decode を優先する配置として、かなり扱いやすかった。
IQ3_K と Q4_X では向いている局面が違う
同じ Kimi-K2.6 でも、IQ3_K と Q4_X は体感がかなり違った。
| Quant | BPW | Model Size | TG avg (t/s) | PP cold (t/s) | CUDA_Host |
|---|---|---|---|---|---|
| IQ3_K | 3.85 | 460 GiB | 20.9 | 223 | 368 GiB |
| Q4_X | 4.55 | 544 GiB | 18.6 | 567 | 455 GiB |
同じ Kimi-K2.6 でも、IQ3_K と Q4_X は体感がかなり違った。Q4_X は PP が圧倒的に速いが、TG は IQ3_K より遅い。expert tensor が重くなるほど毎 token の CPU→GPU 転送コストが増えるため、quant が大きいほうが decode では不利になる。実タスクを回していると、最初の system prompt や大きめの context を飲み込む速さより、数千 token を吐き続ける decode の安定性のほうが効いてくる。RAM 消費も 87 GiB 少ない IQ3_K が sweet spot だった。
-mla の選び方
Kimi-K2.6 のような DeepSeek2 系モデルでは、-mla の違いもそのまま速度差になる。
| Flag | KV cache 方式 | VRAM 使用量 | 速度 |
|---|---|---|---|
-mla 0 | Standard KV | 最大 | 最遅 |
-mla 1 | Compressed latent KV | 最小 | 遅い |
-mla 3 | Absorbed MLA | 最大 | 最速 |
132k context でも KV cache は約 8.9 GiB で済む。VRAM を詰める必要があるなら -mla 1 に逃がせるが、今回の 96GB × 2 構成では -mla 3 で TG を優先。
実タスクで見えた品質
ベンチ数字だけでは分からないので、Zed から Kimi-K2.6 に Django tenant module を作らせて、tool-call 前提の coding task を実際に流した。IQ3_K、non-thinking mode、4~10-layer -ot で回した。
massage_salon モジュール
約 15 分で、Gitea issue 作成、独自のセマンティック差分ctxツール.ctree.toml の調整、Django v6でmodels/admin/apps まで一気に生成した。モデル数は 15、最終的なコード量は 839 行だった。
restaurant モジュール
10-layer head-heavy の構成で、調達、収益、労務、売上、マスタを domain ごとに分けてモデル化した。RestaurantSettings proxy パターンや TextChoices、UniqueConstraint、MinValueValidator を自力で使い分けていて、構造化能力はかなり高かった。
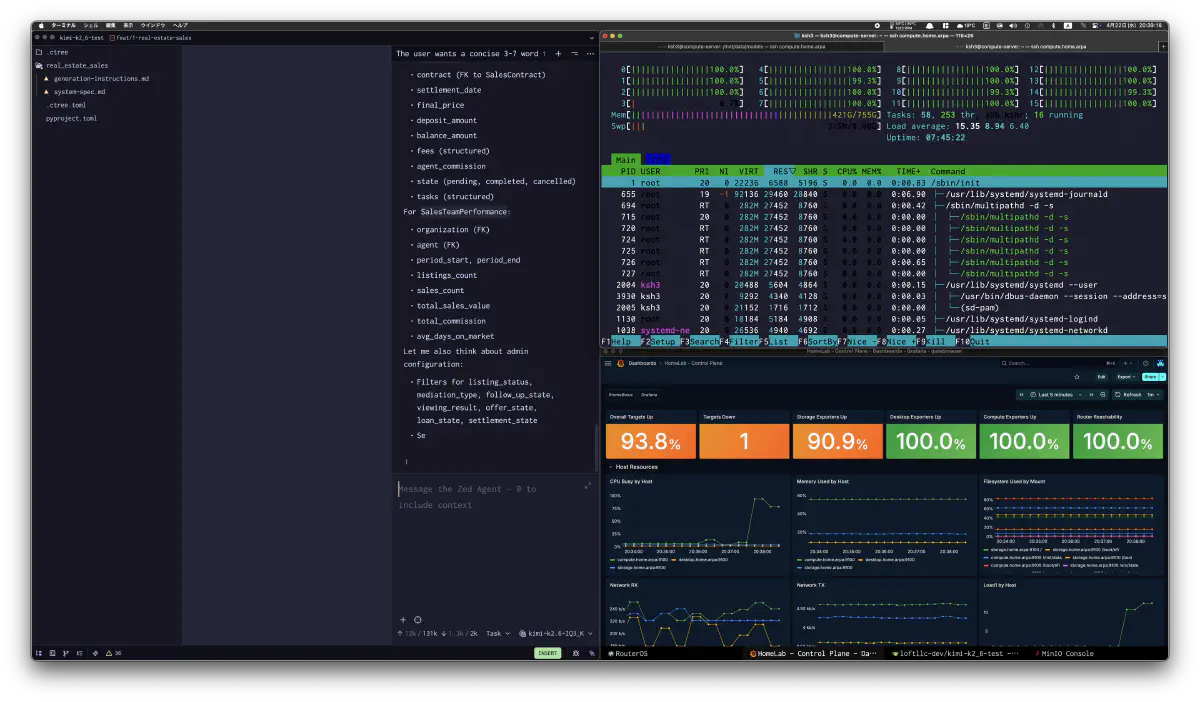
real_estate_sales モジュール
3+3 split の配置で、1 リクエスト 14,707 tokens を約 12.5 分かけて生成し、TG 19.57 t/sだった 。15 model classes、772 行の出力で、物件、査定、媒介契約、内覧、購入申込、ローン審査、売買契約、決済までを一気に繋いでいる。
特に印象に残ったのは、学習データにない自作MCPの ctree MCP 設定を system prompt だけから推測して、実際に scope を切り替えながらコード生成を進めた点だった。ここはベンチ表には出ないが、いろんなモデルを試しているが、500B超えてくるとやっぱり地頭が良いみたいな印象を受ける。
Kimi-K2.6 は単に token を速く吐くだけではなく、複数ファイルの生成、テスト観点の列挙、MCP tool の往復を含む長めの作業単位でも崩れにくかった。
ik_llama.cpp と mainline llama.cpp の比較
同じハードウェア上で測ると差はかなりはっきり出る。
| Engine | Quant | TG (t/s) | PP cold (t/s) | Tool call |
|---|---|---|---|---|
| ik_llama.cpp | IQ3_K | 20.9 | 223 | OK |
| ik_llama.cpp | Q4_X | 18.6 | 567 | OK |
| llama.cpp (mainline) | Q4_X | 15.4 | 188 | Crash |
単に数値が低いだけではなく、私の環境ではtool-call で落ちたので、Visionも確認したいし、もう少し経ってから再度ビルドして試してみる。逆に ik_llama.cpp は -mla 3、複数 -ot、--jinja、tool_call と揃っているので画像不要でコーディング用途なので、私はこちらを使うつもりだ。
参考: HFのcommunityで見た single-GPU ベンチ
Hugging Face の ubergarm/Kimi-K2.6-GGUF discussion #3 ではQ4_X を単一 RTX PRO 6000 + EPYC 9355 + DDR5-6400 で aiperf ベンチした結果が公開されていた。16-turn conversation simulation での平均は次のとおり。
| Engine | TG avg (t/s) | TTFT avg (ms) | Request latency avg (ms) |
|---|---|---|---|
| ik_llama.cpp | 18.85 | 8,563 | 22,480 |
| llama.cpp (mainline) | 16.03 | 12,526 | 28,872 |
こちらでも ik_llama.cpp が全指標で優位だった。-muge が Kimi-K2.6 で逆効果になるケースがあるという話も出ていて、mainline に追従するより fork 側の知見をそのまま使ったほうが早いと感じる。
実際に残した起動コマンド
podman run --rm \
--device nvidia.com/gpu=all \
-p 8000:8000 \
--cap-add=SYS_NICE \
-v /mnt/data/models/models--ubergarm--Kimi-K2.6-GGUF:/models:ro,Z \
registry.home.arpa/ik_llama.cpp:latest \
-m /models/snapshots/${REF}/IQ3_K/Kimi-K2.6-IQ3_K-00001-of-00012.gguf \
--ctx-size 131768 \
--parallel 1 \
--threads 15 \
--threads-batch 32 \
-b 8192 \
-ub 4096 \
-ngl 999 \
-mla 3 \
-ger \
--special \
-amb 512 \
--jinja \
--host 0.0.0.0 \
--port 8000 \
--warmup-batch \
--alias kimi-k2.6-IQ3_K \
-ot "blk\.(1|2)\.ffn.*=CUDA0" \
-ot "blk\.(59|60)\.ffn.*=CUDA1" \
-ot "exps=CPU" \
--temp 0.6 \
--chat-template-kwargs '{"thinking":false}'
この形で、Kimi-K2.6 を OpenAI 互換 API として exposed しつつ、Zed や自作エージェントからそのまま叩ける。
まとめ
| 項目 | 値 |
|---|---|
| Model | Kimi-K2.6 (1T MoE, 384×8 active) |
| Quant | IQ3_K が実運用の本命 |
| Engine | ik_llama.cpp |
| TG | 20.9 t/s (6-layer head/tail split) |
| PP cold | 223-377 t/s (-ub と配置依存) |
| 実タスク | Django tenant module を長尺生成可能 |
| 用途 | orchestrator model |
| License | Modified MIT ($20M / 100M MAU 制限) |
結論として、Kimi-K2.6 は「1T 級だから現実離れしている」ではなく、「CPU pinned memory と vram 72GB、RAM 512GBでぎりぎりいける。ik_llama.cpp の MLA 最適化と -ot 配置でうまく噛み合わせると、ローカルLLMとして許容できるTGでなおかつ、Claudeと併用しながら、データパイプラインを整備できる。