Qwen3.6-27B NVFP4+MTPをvLLMで実測:RTX PRO 6000 Blackwell Max-Q x 2でTG ~190tok/s
Qwen3.6-27B-Text-NVFP4-MTP を vLLM v0.19.2rc1 + MTP 投機デコードで RTX PRO 6000 Blackwell 96GB x 2 に載せて TG/PP/MTP 受理率/Prefix Cache を実測。SGLang FP8 + LoRA 動的切替で EAGLE が使えない構成と、自作エージェントでの実タスク比較、LoRA アダプタ込みでも余裕がある VRAM 予算の所感を記録。

SGLang FP8 + LoRA 動的切替の構成でTGが20-30 tok/s 程度で厳しかったので、EAGLE を使うために動的なLoRAを諦めてマージドモデルかフルチューンモデルにするしかなさそうだった。マルチインスタンスに必要なモデル重み x N で VRAM 予算がちょっと重いので、試しに良いモデルがあったので sakamakismile/Qwen3.6-27B-Text-NVFP4-MTP を vLLM で動かし、MTP 投機デコードとLoRA動的切替をエージェント実装側で制御して、マルチインスタンスで両立できないか考え、動作の検証を行った。
動画リンク: https://www.youtube.com/watch?v=HP1Bl-h45bE
構成
sakamakismile/Qwen3.6-27B-Text-NVFP4-MTP を vLLM v0.19.2rc1 (V1 エンジン) で動かした。GPUはRTX PRO 6000 Max-Q Blackwell 96GB x 2, TP=2構成(tp=1も試したが割愛)。MTPを num_speculative_tokens=3 で有効化し、KV cacheはFP8、Prefix Caching と Chunked Prefill を両方 ON にしている。
podman run --rm -it \
--name naughty \
--pull=always \
--publish 8001:8001 \
--device nvidia.com/gpu=all \
--shm-size=8g \
-v /mnt/data/models/lora-adapters:/loras:ro \
-v /mnt/data/models:/hf/hub:ro \
-e HF_HOME=/hf \
-e HF_HUB_CACHE=/hf/hub \
-e HF_HUB_OFFLINE=1 \
-e TRANSFORMERS_OFFLINE=1 \
-e TORCH_CUDA_ARCH_LIST=12.0 \
-e VLLM_TARGET_DEVICE=cuda \
-e VLLM_USE_V1=1 \
-e VLLM_FLASHINFER_MOE_BACKEND=throughput \
-e VLLM_USE_FLASHINFER_MOE_FP4=1 \
registry.home.arpa/vllm-openai:cu130-nightly-fe9c3d6 \
sakamakismile/Qwen3.6-27B-Text-NVFP4-MTP \
--host 0.0.0.0 \
--port 8001 \
--served-model-name Qwen3.6-27b-NVFP4 \
--trust-remote-code \
--language-model-only \
--quantization modelopt \
--enable-prefix-caching \
--dtype auto \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.88 \
--max-model-len 262144 \
--max-num-seqs 8 \
--kv-cache-dtype fp8 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--default-chat-template-kwargs '{"enable_thinking": true}' \
--speculative-config '{"method":"qwen3_5_mtp","num_speculative_tokens":3}' \
--override-generation-config '{"temperature":1.0,"top_p":0.95,"top_k":20,"presence_penalty":0.0,"repetition_penalty":1.0}'
初期化は合計約 102 秒。内訳はモデルロード 1.45s (target) + 0.21s (drafter)、torch.compile 45.95s + 6.97s、CUDA Graph Capture 2s。FB Used は 87.6 GB/GPU、Free は 9.69 GB/GPU。KV cache は 1,115,200 tokens 確保。
LoRA アダプタ (axolotl, bf16)
LoRAはaxolotlでbf16 学習したアダプタを使った。NVFP4量子化済みベースに対しては実行時にLoRAを当てて動作確認
base_model: /mnt/data/models/models--Qwen--Qwen3.6-27B/snapshots/5d316fa25c3a0b6251198e9e7a94e863a435536a
tokenizer_type: AutoTokenizer
trust_remote_code: true
datasets:
- path: datasets/familiar-sft-v2/train.jsonl
type: chat_template
ds_type: json
field_messages: messages
roles_to_train:
- assistant
test_datasets:
- path: datasets/familiar-sft-v2/val.jsonl
type: chat_template
ds_type: json
field_messages: messages
roles_to_train:
- assistant
chat_template: tokenizer_default
sequence_len: 16384
sample_packing: false
pad_to_sequence_len: false
adapter: lora
lora_r: 16
lora_alpha: 32
lora_dropout: 0.05
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
output_dir: /mnt/data/models/lora-adapters/qwen3.6-27b-familiar-bf16-lora
save_safetensors: true
save_total_limit: 2
save_steps: 50
eval_steps: 50
logging_steps: 5
micro_batch_size: 1
gradient_accumulation_steps: 8
num_epochs: 2
learning_rate: 5.0e-5
lr_scheduler: cosine
warmup_ratio: 0.05
optimizer: adamw_torch
bf16: true
fp16: false
tf32: true
load_in_8bit: false
load_in_4bit: false
gradient_checkpointing: true
/mnt/data/models/lora-adapters を vLLM コンテナに :ro マウントして、起動後にLoRAを当てて動作するところまで確認。seq=4でありなしで試したところ概ね以下だった。(動画、本記事はloraなしx2の検証)
あり: 8595 tok/s
なし: 85105 tok/s
スループット実測
Django ライクなタスクを流して、vLLM のログから 10 秒間隔のメトリクス
Generation Throughput (TG)
- 平均 (全体): 155.7 tok/s
- 平均 (アクティブ, >50 tok/s): 161.4 tok/s
- 最大: 190.4 tok/s
- 最小: 32.6 tok/s
- アクティブサンプル: 43 / 45
Prompt Processing (PP)
- 平均 (アクティブ, >0): 831.2 tok/s
- 最大: 2,773.3 tok/s
- 最小 (アクティブ): 226.6 tok/s
- アクティブサンプル: 28 / 45
MTP 投機デコード
- Mean Acceptance Length (MAL) 平均: 3.64
- MAL 最大: 4.00
- Draft Acceptance Rate 平均: 87.9%
- Draft Acceptance Rate 最大: 100.0%
- Draft Acceptance Rate 最小: 70.3%
Caching
- Prefix Cache Hit Rate: 68.7% → 91.2% (最終)
- GPU KV Cache Usage 最大: 2.1%
エージェントのツール呼び出しが繰り返されるパターンでは Prefix Cache が効きやすく、セッション後半では 91% まで上がった。KV cache 使用率が最大でも 2.1% に留まっているのは、max_num_seqs=8 かつ単一ストリームに近い利用パターンだったため。
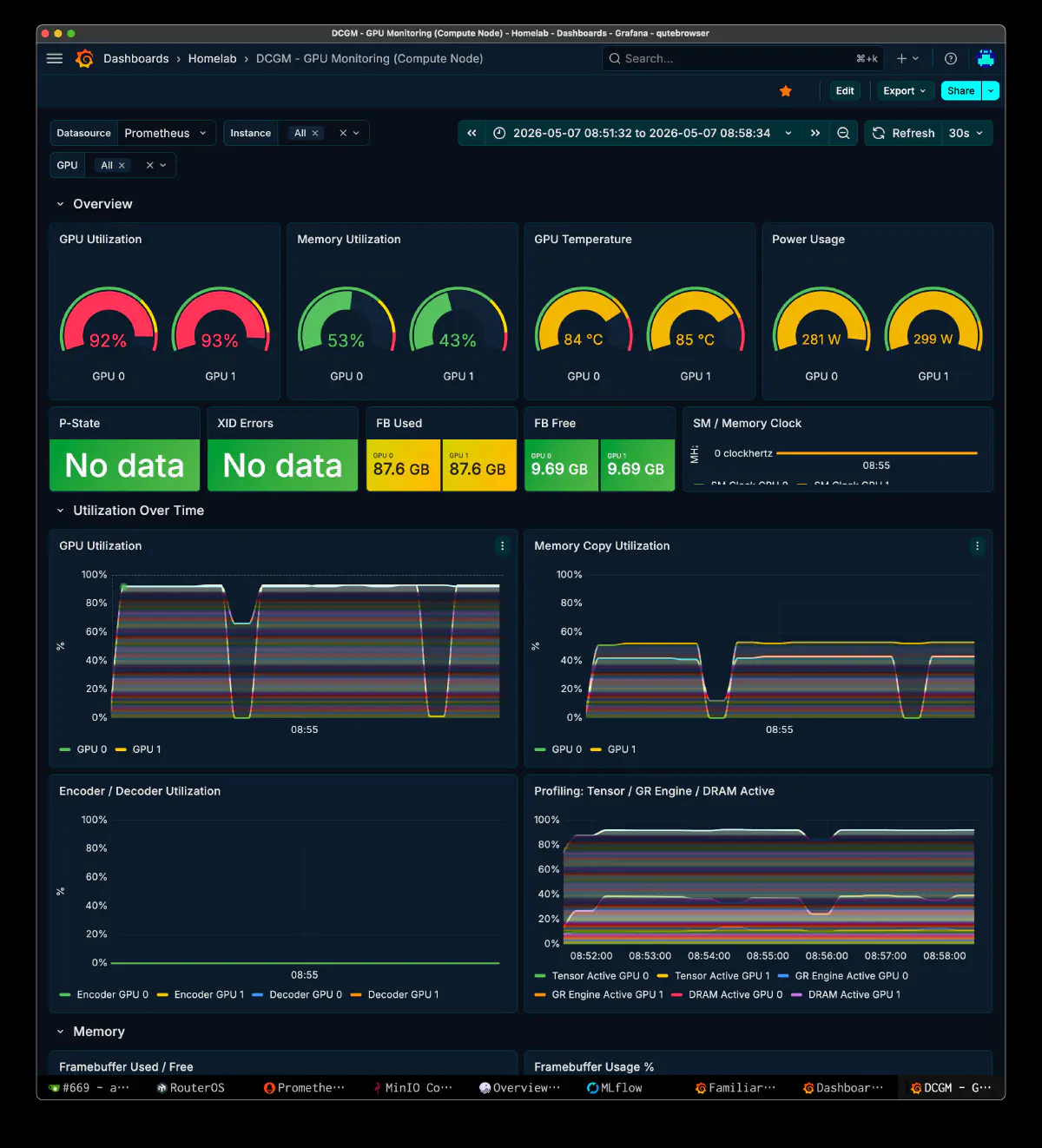
GPU 状態 (DCGM)
実行中の Grafana DCGM ダッシュボードから読み取った値。
- GPU Utilization: 92% / 93%
- Memory Utilization: 53% / 43%
- Temperature: 84°C / 85°C
- Power: 281 W / 299 W
エージェント実タスクでの比較: vLLM NVFP4 vs SGLang FP8
自作エージェントシステムで同ジャンルのタスクを vLLM NVFP4+MTP (alias: naughty) と SGLang FP8 (alias: frisky) の両方で実行した。Grafana の Familiar Tool Calls ダッシュボードでの1セッション同士の集計。
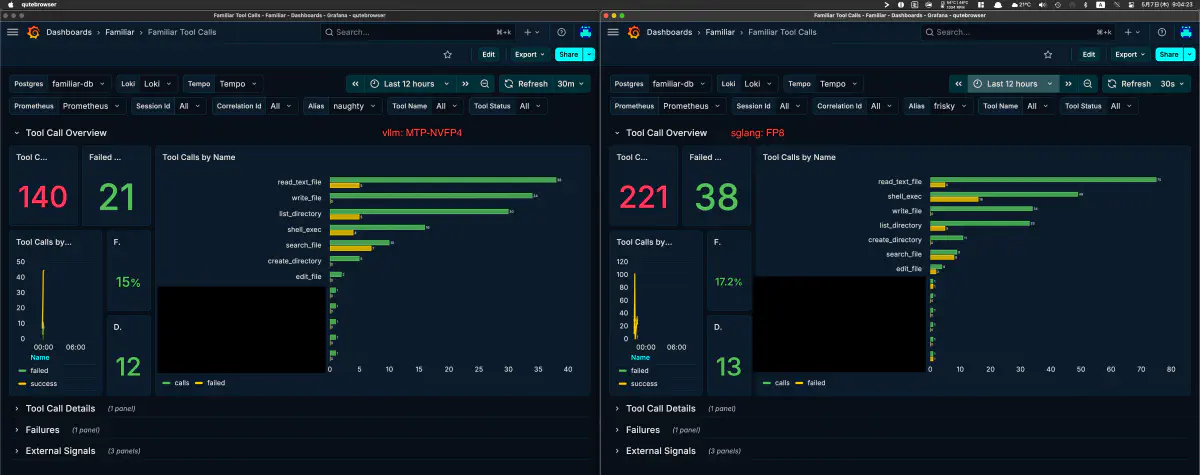
- vLLM NVFP4: 140 calls / 21 failed (15.0%)
- SGLang FP8: 221 calls / 38 failed (17.2%)
サンプルは 1 セッション分のみで統計的に有意とは言えないが、ツール呼び出しの失敗率に大きな乖離はなかった。動画では NVFP4 側でツールエラーがそれなりに目立つ場面があるものの、エージェントが完走したセッション単位で見ると失敗率の差は ~2 ポイント程度。後半 NVFP4 はダレが出て未完走、FP8 は完走している。
Prefix Cache の挙動が独自 CTXManager で割れた件
エージェント側で独自に組んでいる CTXManager クラスでコンテキストを合成して投げているが、その合成パターンに対して、vLLM だけ Prefix Cache Hit Rate が継続的に 0 に張り付く時間帯があった。同じワークロードを SGLang と ik_llama に投げると 0.8-1.0 で安定していたので、cache hit が出る/出ないは合成側のキー一致の問題ではなく、vLLM 側のキャッシュ挙動か、自分の起動オプションのどこかで cache が切れていた可能性が高い。メモとして残しておく。
所感
- SGLang FP8 (~30GB) で EAGLE なし (LoRA 動的切替を優先する構成) だと TG 20-30 tok/s 付近に張り付く。SGLang でEAGLEを使うにはインスタンスを分けて、マージドモデルかフルチューンモデルにし、LoRAアダプタをマルチインスタンスごとに割り当てれば可能そうだが、モデル重み x N で VRAM 予算が苦しい。
- vLLM の MTP-NVFP4 ならモデル重みが ~15GB+loraで済むので、 マルチインスタンス運用でもモデル重み側を妥協できる。コンテキスト空間をインスタンスごとにクリーンに保てるメリットもあるし、LMCacheeとの相性も良い。マッチするユースケースはあると思う。
- 同じ NVFP4 ベースでLoRAアダプタを有効にした場合のTGは~90 tok/s (avg)で、LoRA なしの161 tok/sからは落ちるが、SGLang FP8 + LoRA の 20-30 tok/s 帯と比べれば 3-4倍。品質評価は未実施だが、ツールエラーのレートに大きな乖離はなかった。
- LMCache と併用したかったが NVFP4 はまだ未対応。tracking issue: https://github.com/LMCache/LMCache/issues/3163