Step-3.7-Flash-NVFP4をローカルのオーケストレータに: マルチエージェントでシステム開発
Step-3.7-Flash-NVFP4をオーケストレータに、自作マルチエージェント基盤familiarでDjangoベースの業務システムをローカル生成させた検証。約1時間で完動し、迅速に7割完成のプロトタイプを作る

ローカル完結のマルチエージェントで、業務システムをどこまで自律的に作れるか。その実用ラインを探る検証です。今回はオーケストレータにStep-3.7-Flash-NVFP4を据え、自作基盤familiarで6ロールのエージェントを並列に走らせ、レストラン予約ドメインのAPI、RBAC対応管理システムを構築させました。外部APIは一切使わず、推論も計測も全部ローカルです。
結論を先に書くと、Step-3.7-Flashはオーケストレータとしてかなり良い。タスク分解と依存解決は安定しています。一方で、セッション後半に進むほど修正ループが増えやすい傾向があり(ガードレールの影響もあり)、「ほぼ動く」までは速く、最後の詰めに時間がかかる、という感じでした。
動画リンク: https://www.youtube.com/watch?v=L6ryJhd2EmA
直近でやったこと: 生成トークン見積りとstream continuation
このベンチの前にdwarfstarのコミットを見ていると、生成トークンの見積りとバジェット制御を目にして、これは良いなと思って自分のシステムにも取り込んだ。BackendGenerationTokenControllerをinternal/domain/agentに切り出し、stream continuation、つまりlength capで切れた生成を継続プロンプトで拾い直す仕組みと合わせて導入しました。
これを入れた動機は、長い推論を伴うセッションは終盤で壊れやすく、リカバリーに回るとそこからなし崩し的に品質劣化するからです。実際に直前のセッションでは、ワーカーのXML/TOMLパースエラーを修復するループに入りやすかった。もともと事後処理はあったけど、思い切って「もう悪くなりそうだな」で合成したほうが結局はよかった。dwarfstarはここ最近のコミット履歴を見ていても、deepseek4に特化した単一モデルエージェントとして舵を切っていて、僕は置き換え可能なマルチモデルでOSSで提供される良いモデルがあれば積極的に乗り換えていく考えなので正反対なんだけど、取り組んでいる課題はすごく似ているなーと思った。
参考にして追加したBackendGenerationTokenControllerは送信を持たない、send-freeな観測・制御コンポーネントです。役割は次の四つです。
- OpenAI互換のストリームチャンクを観測し、既存のトークン推定器で生成済み補完トークンを見積もる
max_tokens/コンテキストウィンドウ上限に対する超過を検知する- continue / cutoff / repair-needed / terminalといった制御判断を返す
- tool-call finish時に壊れた引数、malformed tool argument(これはthinkingに入ってたものをサルベージする考えを見て良いなと思った)を検出する
プロンプト合成、継続プロンプト生成、修復プロンプト、最終応答合成、テレメトリ集約は、外側のエージェント側に残してあります。コントローラ自体はあくまで「ストリームを見て判断を返す状態機械」に徹する設計です。
合わせてロール毎のダイナミックなサンプリングも調整しました。stream continuationがlength capから復帰できるようになったので、max_output_tokensを下げ、サンプリングを狭めて、長いreasoning/出力のストールを減らしています。testerにはrepetition_penalty 1.08と低めのtemperature/top_pを当てて、検証ループの空回りを抑えました。
セットアップ
| 項目 | 内容 |
|---|---|
| Orchestrator | Step-3.7-Flash-NVFP4 on vLLM |
| Framework | 自作Go (Gin) + Rust製MCP群 |
| roles | orchestrator / planner / coder / tester / reviewer / integrator |
| Task | Restaurant Domain Spec(レストラン予約ドメイン) |
| CPU | AMD EPYC 9175F 16C |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x 2 |
モデルは置き換え可能で、最大3モデルまで連携できます。今回は単一モデル、Step-3.7-Flashにオーケストレータとワーカーの両方をロールセッションで兼ねさせる構成で走らせました。経験上、連携モデル数が少ないほど成功率もトークンコストも改善する傾向があります。これは学習データの分布が違うから、脈絡を繋げないのだと思います。なので、疎結合なロール毎にモデルをチョイスすると、それなりにシンクロしますが、単一モデルでやるほうが苦労しないと思います。複数モデルを使う場合は10B以下のなにかに特化したモデルをRust Ort/onnxで使うとか、そのほうがeffectiveが小さくてコントロールしやすいです。
vLLM側の主な実行コンフィグは次のとおりです。
Exec=/models/snapshots/36afbf6e15100cdc2d7a5b79d7e95d276ed33679 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name grandpa \
--gpu-memory-utilization 0.92 \
--tensor-parallel-size 2 \
--max-num-seqs 8 \
--kv-cache-dtype fp8 \
--max-model-len 147456 \
--disable-cascade-attn \
--enable-expert-parallel \
--trust-remote-code \
--quantization modelopt \
--reasoning-parser step3p5 \
--tool-call-parser step3p5 \
--enable-auto-tool-choice \
--enable-expert-parallel \
--async-scheduling
観測スタックはGrafana + Prometheus / Loki / PostgreSQL / Vector / Tempo / Alloy。挙動を専用ダッシュボード群で可視化しながら、リアルタイムでclaude/codexにデバッグさせて仮説検証のPDCAを回しています。
vLLM intervalベンチ
| window end | completed reqs in window | running | PP tok/s | TG tok/s | KV usage | prefix hit |
|---|---|---|---|---|---|---|
| 11:39:14 | 3 | 3 | 3242.7 | 153.9 | 1.8% | 81.5% |
| 11:39:24 | 4 | 3 | 140.7 | 196.7 | 1.8% | 81.7% |
| 11:39:34 | 2 | 2 | 34.7 | 201.1 | 1.5% | 81.7% |
| 11:39:44 | 2 | 2 | 217.3 | 154.6 | 1.5% | 81.8% |
集計するとこうなります。
| metric | avg | median | min | max |
|---|---|---|---|---|
| PP tok/s | 908.9 | 179.0 | 34.7 | 3242.7 |
| TG tok/s | 176.6 | 175.7 | 153.9 | 201.1 |
| Running | 2.5 | 2.5 | 2 | 3 |
| Prefix hit | 81.7% | 81.7% | 81.5% | 81.8% |
これはseq=8ですが、ソフトキャップで7で走らせたバッチに近いです。
シングルリクエストは別で計測して動画の説明にベンチのせています。
動画リンク: https://www.youtube.com/watch?v=NDhzjHW-2SM
走らせている様子
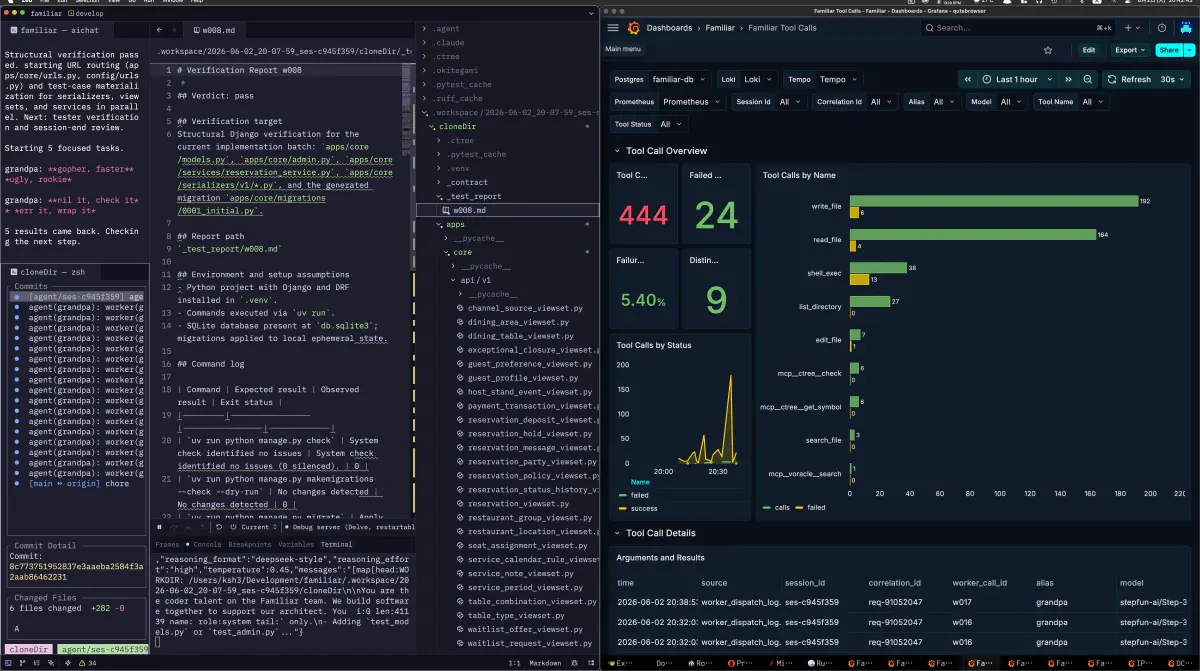
Chat DAG: 会話の形
1セッションの会話そのものを、datastore確定前にvector/lokiでDAGとして可視化したものです。user request -> orchestrator -> Scheduler Decisions -> Dependencies -> worker -> orchestratorという流れで、どのturnからどのworkerが生えたかを追えるようにしています。
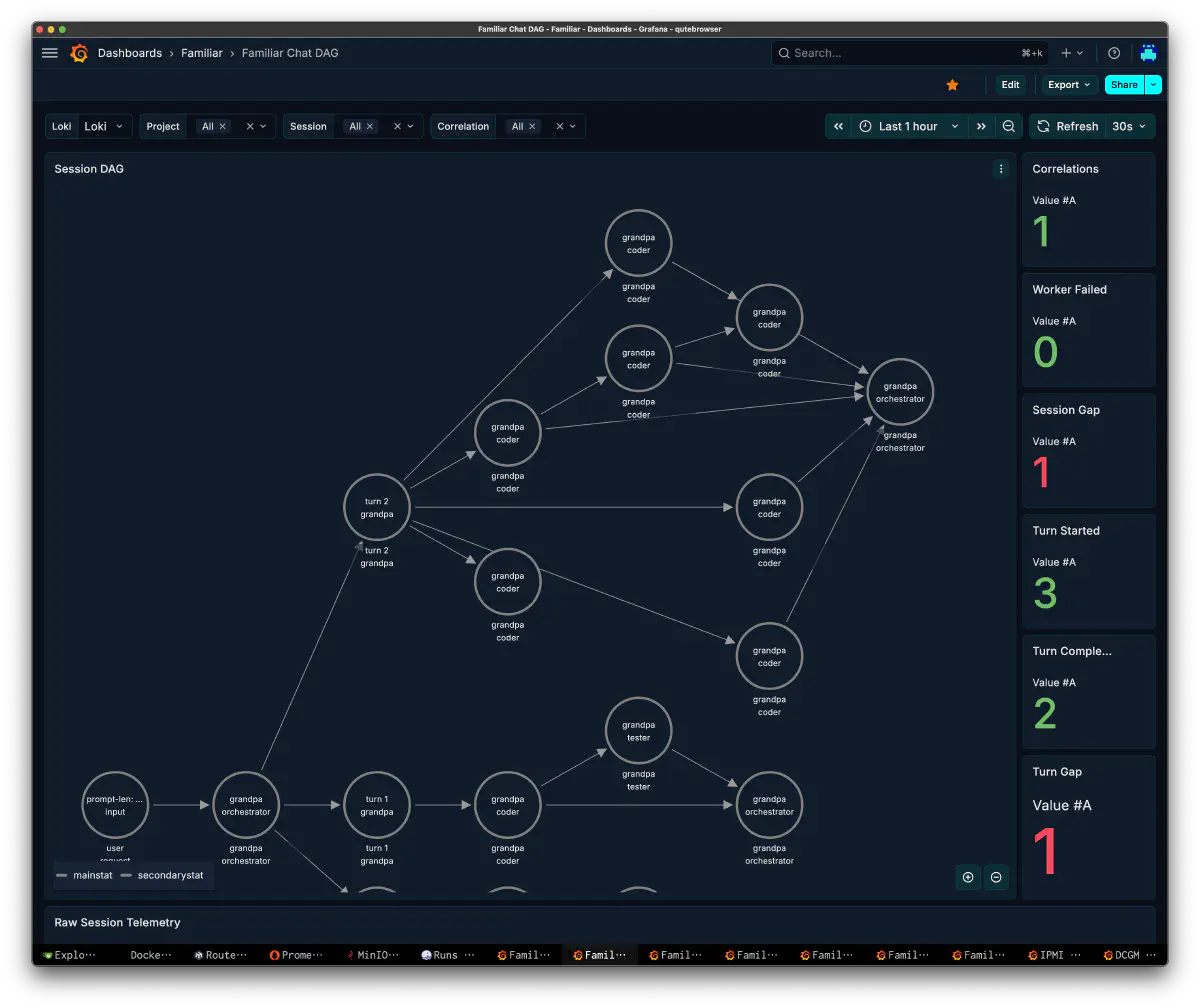
Orchestrator Decisions: 判断の中身
オーケストレータの判断を分解したダッシュボードです。
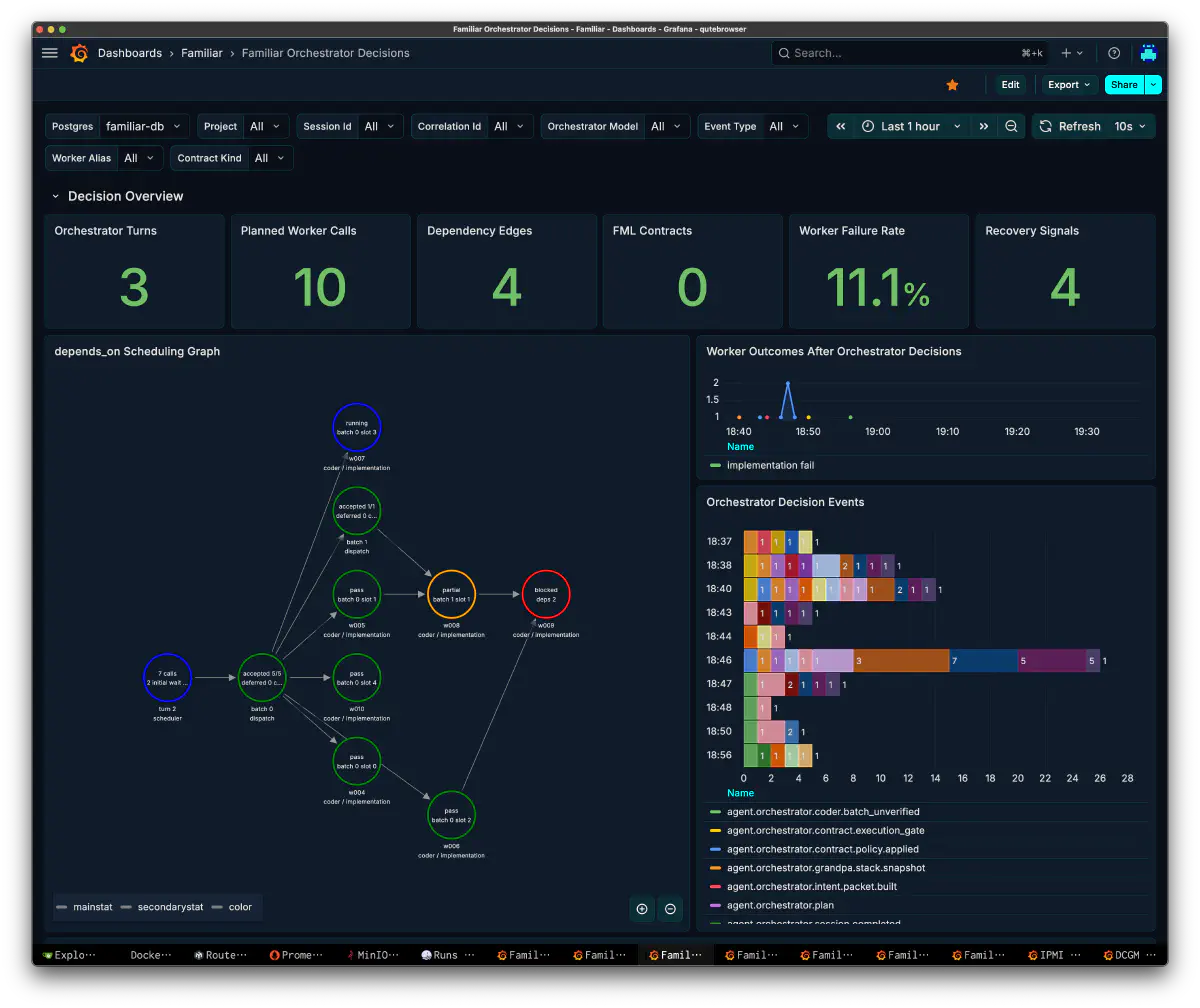
Guard Calls: やってはいけないことをガード、リカバーする
エージェントの逸脱した振る舞いを実行時に止めるGuardレイヤーを持っています。このセッションではGuard Calls 40、うちblocking 11、non-blocking 29、Block Rate 27.5%でした。
| Action | calls | blocking |
|---|---|---|
| downgrade_fulfillment | 25 | 0 |
| reject_tool_call | 7 | 7 |
| record_proposed_path | 4 | 0 |
| reject_unowned_write | 4 | 4 |
MOLsEV: プロンプト品質と役割間Synergy
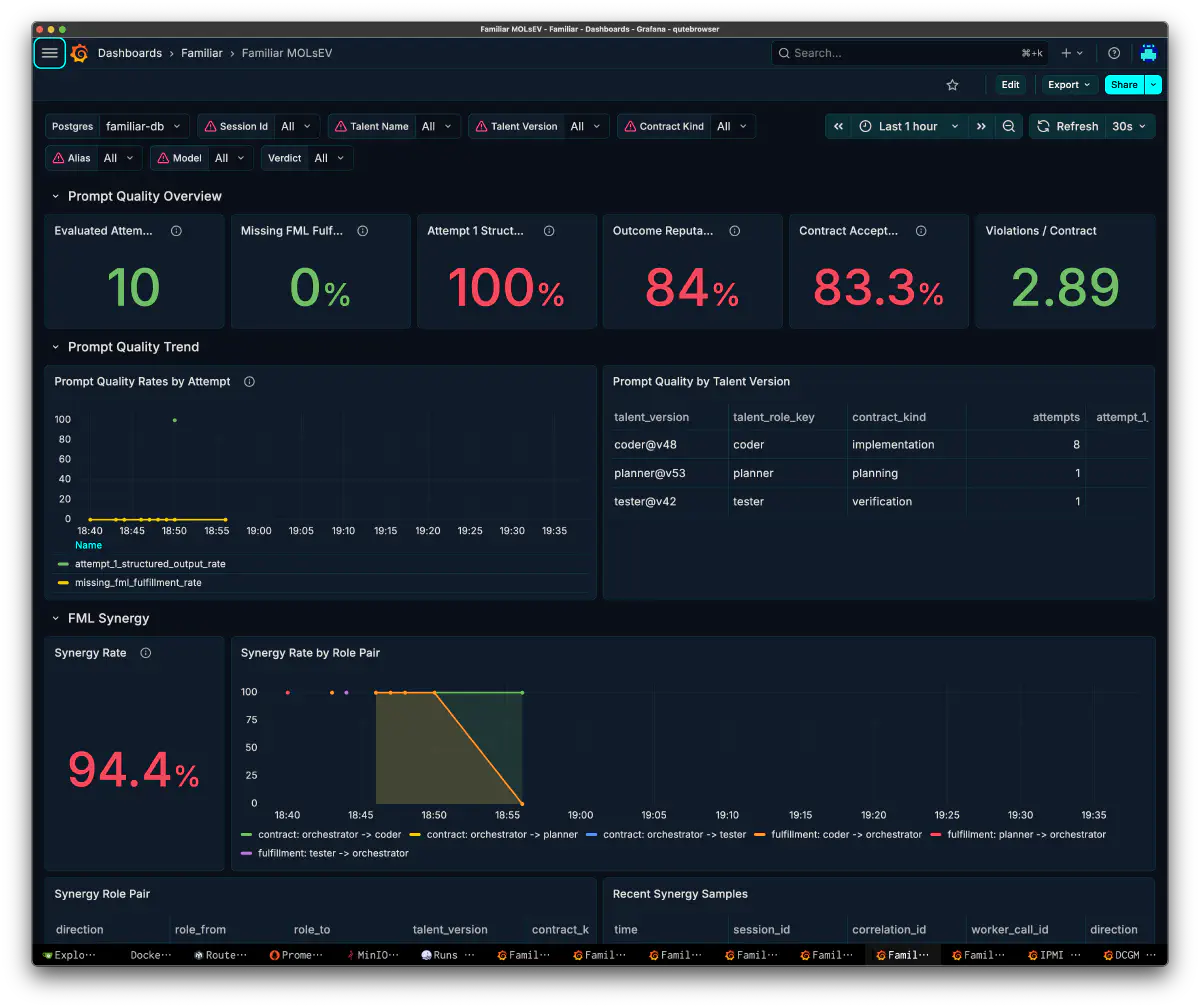
結果
完全に動く状態まで、おおよそ1時間。「ほぼ動く」状態、だいたい70%には約24分くらい。前半は速く、後半の詰めに時間が寄る、という時間配分です。
7件の成果物のうち、手直し不要でコマンドで起動が通ったのは2件ほどでした。
- 管理画面、Django adminがそのまま使える
- APIが動作する
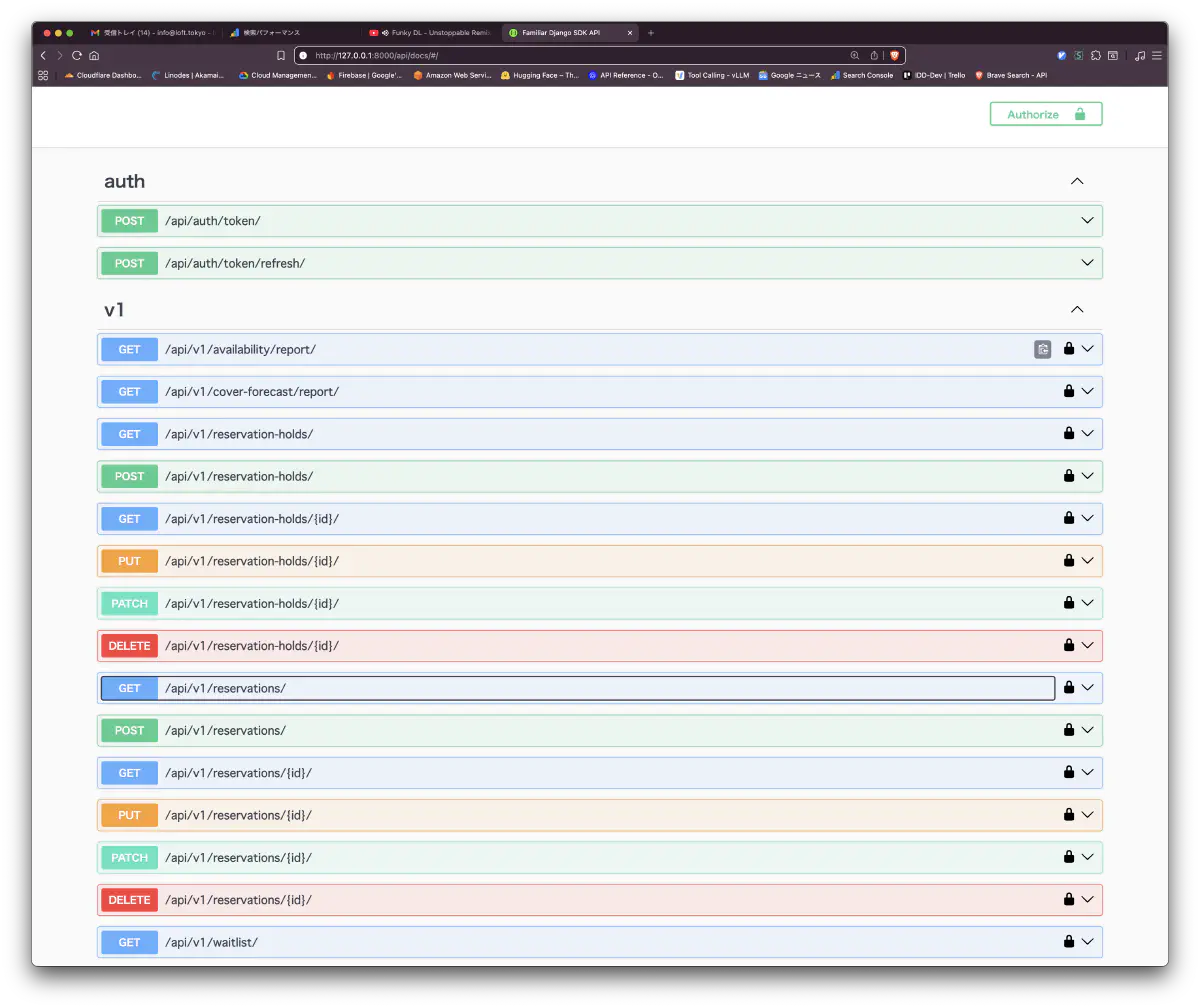
api/docs、Swagger UIが生成され、authとv1リソースが一通り並ぶ- seedで初期データが入っている
残り5件は軽微な修正が必要な状態でした。api/docsを開くと、auth/token・reservations・reservation-holds・waitlist・availability/report・cover-forecast/reportといった、ドメインに沿った現実的なリソース設計がCRUDとレポート系まで揃っているのが見えます。
所感
Step-3.7-Flashはローカルのオーケストレータとしてかなり良い。 3.5もかなりオーケストラ向きでよかったのですが、さらに良くなっていて、タスク分解と依存解決は安定していて、Attempt-1の構造化出力率100%が示すとおりワイヤ形式の遵守も堅い。今回のvLLM interval集計ではTG平均176.6 tok/s、中央値175.7 tok/s、範囲153.9-201.1 tok/sでした。prefix cache hit rateも81.5-81.8%で安定していて、コンテキストウィンドウマネージャが概ね70-90%を保持し、自作のctxMgrでロールセッションを跨いでもキャッシュを育てて80%前後をキープできています。
ちなみに僕の環境ではNVFP4だとMTPは使えず、SGLangではcu13だと、SM100までしか対応していないエラーがでて動かなかったです。ik_llamaでGGUFも試したけど、クラッシュと出力品質が安定しなかったです。
開発は、ざっくり7割くらいをClaude/Codexに任せています。設計とアウトライン実装がほとんどです。散歩しながら閃いたことを実験に落とす、観測ダッシュボードを眺めて見つけた仮説を実装に反映する、その繰り返し。可観測性を先に厚くしておくと、この「仮説->実装」のループが速く回せるので、まずはそこを揃えたほうが苦労しないと思います。