よく使う言語だけ AST ベースでコードベース解析器を自作した: ctree の設計と pathfinder/Serena 連携
ローカル LLM のコンテキスト消費を抑えるために、自分がよく使う言語だけ AST ベースでオンデマンドのコードベース解析器 ctree を Rust で自作した。pathfinder でファイル操作の精度を上げ、ctree で浅い俯瞰を得て、Serena の find_symbol で解像度を上げる三層構成の設計意図をまとめた。

結論
ローカル LLM でコーディングエージェントを動かすとき、コンテキストの消費効率が実用性を左右する。Serena のようなシンボル解析ツールは精度が高いが、最初からすべてのシンボルを読み込むとコンテキストが膨張する。
そこで、自分がよく使う言語だけを対象に、AST ベースでコードベース全体を浅く俯瞰するオンデマンド解析器 ctree を Rust で自作した。コードベース全体のスナップショットをハッシュベースで管理し、実装の変化と依存の変化をコンパクトに追跡する。フォーカスする関心に応じて実装者が任意でスコープを調整できる仕組みにした。
ctree で浅いヒントを得て、そこから Serena の find_symbol で解像度を上げる — これが設計の核心だ。pathfinder と組み合わせることで、ファイル操作ツールの精度向上とコンテキスト節約を同時に実現する。
GPU のコンテキスト単価を考えれば、ソフトウェア側でのパフォーマンス改善は費用対効果が高い。
動機: Serena のコンテキストコストを補完する
Serena はシンボルレベルの精密な解析ができるが、「まずコードベース全体を浅く把握する」用途には向いていない。全シンボルを読み込めばコンテキストが膨張し、ローカル LLM の限られたコンテキストウィンドウを圧迫する。
必要だったのは、Serena の前段に置く「浅い俯瞰」レイヤーだ。
| 層 | ツール | 役割 |
|---|---|---|
| ファイル操作の精度向上 | pathfinder | パス解決の失敗をリカバリし、コンテキスト膨張を防ぐ |
| コードベースの浅い俯瞰 | ctree | 実装と依存の変化をハッシュベースでコンパクトに提供 |
| シンボルの精密な解析 | Serena | find_symbol で特定シンボルの定義・参照を取得 |
ctree は pathfinder と合わせて設計した。pathfinder がファイルパスの精度を担保し、ctree がコードベースの構造的なヒントを提供し、Serena が最終的な解像度を上げる。三層それぞれが独立した MCP ツールとして動作する。
CLI
$ ctree --help
Generate annotated tree + symbols + compact ctx
Usage: ctree [OPTIONS] [COMMAND]
Commands:
init
reset
check
clean
help Print this message or the help of the given subcommand(s)
Options:
--mcp Run as MCP stdio server
--config <CONFIG> Config file path (default: .ctree.toml if exists)
--root <ROOT> Scan root path [default: .]
--syntax <SYNTAX> [possible values: go, rust, python, typescript,
csharp, dart, lua, awk, shell, kotlin, swift,
markdown, html]
--include <INCLUDE> Include globs
--exclude <EXCLUDE> Exclude globs [default: **/tmp/**,**/testdata/**,
**/.git/**,**/vendor/**]
--strong <STRONG> Strong scope globs
--weak <WEAK> Weak scope globs
--sw <SW> Max annotation words per strong file line [default: 12]
--ww <WW> Max annotation words per weak/symbol-only file line [default: 3]
--reasoning <REASONING> Reasoning level [possible values: high, medium, low]
--template <TEMPLATE> Output template [possible values: plain, hugo, jinja]
-h, --help Print help
設計: AST ベースのオンデマンド解析
対応言語
自分がよく使う言語に絞って tree-sitter ベースの AST パーサーを実装した。
Go, Rust, Python, TypeScript/JavaScript, Dart, Kotlin, Lua, Shell, Awk, C#, Swift, Markdown, HTML
アプリケーション本体だけでなく、シェルスクリプトやドキュメントまで同じフレームワークで扱う。実際のリポジトリでは主要言語だけ見ても全体像が分からないことが多い。
strong / weak スコープ
コードベース全体を均一に解析するのではなく、ファイルごとに strong(詳細)と weak(概要)のスコープを分ける。
[ctree]
watch = "rust"
root = "."
include = ["src/**/*.rs", "tests/**/*.rs"]
exclude = ["**/tmp/**", "**/testdata/**", "**/.git/**", "**/vendor/**", "**/target/**"]
strong = ["src/**"]
weak = ["tests/**"]
sw = 24
ww = 5
reasoning = "medium"
strong に指定したファイルは詳細なシンボル要約を持ち、weak は軽い概要だけを持つ。フォーカスする関心が変われば、この設定を変えるだけでスコープが切り替わる。
この分離が ctree の核心的な設計判断だ。コードベース全体を重く持つのではなく、「どこを厚く見るか」を実装者が能動的に決める。
reasoning プリセット
要約の詳細度は reasoning = "high" | "medium" | "low" の 1 フィールドで制御する。
| reasoning | 用途 |
|---|---|
| high | 小規模プロジェクト、詳細な解析が必要な場面 |
| medium | 通常の開発作業(デフォルト) |
| low | 大規模モノレポ、トークンを最小限に抑えたい場面 |
ハッシュベースのスナップショット
スコープ設定(strong/weak パターン + reasoning レベル)から決定論的にハッシュを生成し、スナップショットディレクトリを分離する。
.ctree/
rust/
e83adb52/ ← スコープ設定のハッシュ
snapshots/
.baseline.txt
rev/
0001.txt
0002.txt
スコープを切り替えても過去のスナップショットは保持される。戻せば再生成なしに復元できる。ブランチ切り替えやフォーカス変更を低コストにする設計だ。
MCP ツール
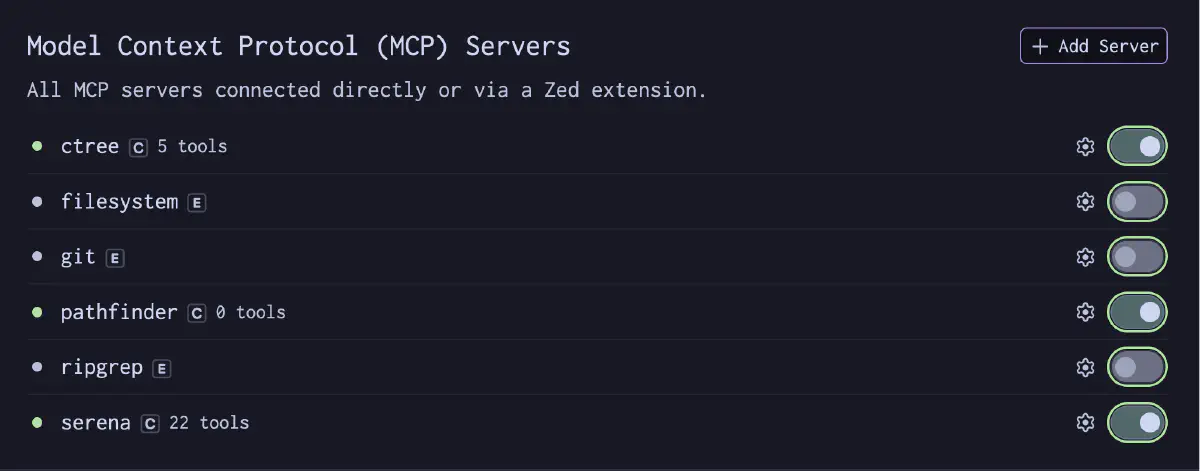
ctree は 5 つの MCP ツールを公開する。
| ツール | 役割 |
|---|---|
check | スナップショットの生成・更新。最新の差分を返す |
get_baseline | コードベース全体のアノテーション付きツリー + シンボル要約を返す |
get_revs | リビジョン履歴(何が変わったか)を返す |
get_text | ハッシュからシンボルや依存のテキストを取得する |
get_depends | シンボル間の依存関係を探索する |
実際の出力
ctree check — スナップショット生成と差分検出
$ ctree check --syntax rust
frequency=always
action=generate
latest_before=0001
latest_after=0001
(no new rev)
変更がなければ (no new rev) で即座に返る。変更が検出されると新しいリビジョンが生成され、変化したシンボルのハッシュが返る。
初回生成時の出力:
$ ctree check --syntax rust
frequency=always
action=generate
latest_before=
latest_after=0001
rev_file=.ctree/rust/{scope_hash}/snapshots/rev/0001.txt
hashes={hash1},{hash2},{hash3},...
{hash1}
source=symbol kind=module name=... scope=strong path=src/.../main.rs line=2
mod ...;
--{hash1}
{hash2}
source=symbol kind=function name=... scope=strong path=src/.../mcp.rs line=164
fn ...(args: ...) -> Result<...> {
--{hash2}
各ハッシュはシンボルの識別子で、get_text に渡すと本文を取得できる。
get_baseline — コードベースの浅い俯瞰
get_baseline が返すのは、アノテーション付きファイルツリーとシンボル要約だ。ソースコード全文ではない。baseline にはトークン推定値が含まれ、ここから関心のあるシンボルを特定して Serena の find_symbol で定義を取得する。
出力フォーマットの詳細は非公開。自社の LLM パイプライン基盤に組み込んで運用しているため。
get_revs — リビジョン差分
シンボルの追加・削除と依存の追加・削除をコンパクトに表現するリビジョン差分を返す。ハッシュを get_text に渡すとシンボルの本文や依存の詳細を取得できる。
出力フォーマットの詳細は非公開。
pathfinder + ctree + Serena の三層連携
pathfinder — パス解決の失敗をリカバリする
LLM がディレクトリ名を typo した場合でも、pathfinder が正しいパスを解決する。
path_resolve:
check_path: "content/ja/docs/tech/infrastrcture/podman-quadlet-systemd-ubuntu.md"
^^^^^^^^^^^ typo
→ resolved: "content/ja/docs/tech/infrastructure/podman-quadlet-systemd-ubuntu.md"
$ pathfinder --help
pathfinder — semantic path finder & MCP resolution server
USAGE
pathfinder [OPTIONS] Interactive semantic directory finder (default).
pathfinder --mcp [OPTIONS] Start as an MCP server.
FINDER OPTIONS
--include-builds Include build/artifact dirs (target, dist, …).
MCP OPTIONS
--root <PATH> Add a project root directory to watch and index.
GENERAL OPTIONS
-h, --help Print this help message and exit.
-V, --version Print version, model, and PCA config.
MCP TOOLS
1. path_resolve Resolve a failed file path to the best match.
2. tool_retry_with_resolve Resolve + retry the operation in one call.
3. roots_list Return configured root directories.
4. reindex_paths Force a full index rebuild.
ENVIRONMENT VARIABLES
PF_MCP_INFERENCE Inference mode: "general" (default) or "code".
Models (both INT8 quantized):
general → mxbai-edge-colbert (17M, 48-dim)
code → lateon-code-edge (17M, 48-dim)
想定ワークフロー
1. pathfinder → LLM のパス typo を解決(ENOENT → tool_retry_with_resolve)
2. ctree check → スナップショット更新、変更されたシンボルのハッシュを取得
3. get_baseline → コードベースの浅い俯瞰を得る
4. 関心のあるシンボルを特定 → Serena の find_symbol で定義・参照を深掘り
5. get_revs + get_text → 変更されたシンボルの詳細を取得
この構成の要点は、各層が独立した MCP ツールとして動作し、必要な情報を段階的に取得する点にある。最初から全部を読み込むのではなく、浅い俯瞰から始めて必要に応じて深掘りする。
GPU でのコンテキスト処理は高コストだ。8K〜32K のコンテキストウィンドウで動作するローカル LLM では、ソフトウェア側でコンテキスト効率を改善することが直接的なコスト削減になる。
注意事項
- ctree は自分がよく使う言語に限定した AST パーサーであり、汎用の静的解析ツールではない
get_baselineとget_revsの出力フォーマット詳細は非公開。自社の LLM パイプライン基盤に組み込んで運用しているため- ML 推論(ONNX、ColBERT 等)の組み込みは検討して見送った。strong/weak スコープ制御で十分にモノレポのコンテキスト膨張問題を解決できるため、決定論的な設計を維持した
- MCP プロトコル(2024-11-05)に準拠。Claude Code、Zed Editor 等の MCP クライアントで利用可能