全部 Rust、全部自作 -- homelab MCP ツールチェーン 9本の設計と目的
homelab の LLM エージェント向けに自作した MCP ツールチェーン 9本の全体像。全て Rust 製、stdio JSON-RPC 2.0。各ツールの設計思想と目的を紹介する。

この記事について
familiar のオーケストレーションで使っている MCP ツールは、現時点で9本。全部 Rust、全部 stdio JSON-RPC 2.0。ほぼ1日に1-2本作っては改良するペースで、廃棄したものもいくつもある。この記事では現在生き残って稼働している9本の設計と目的を書く。

全体像
これらのツールが動いている homelab の全体構成:
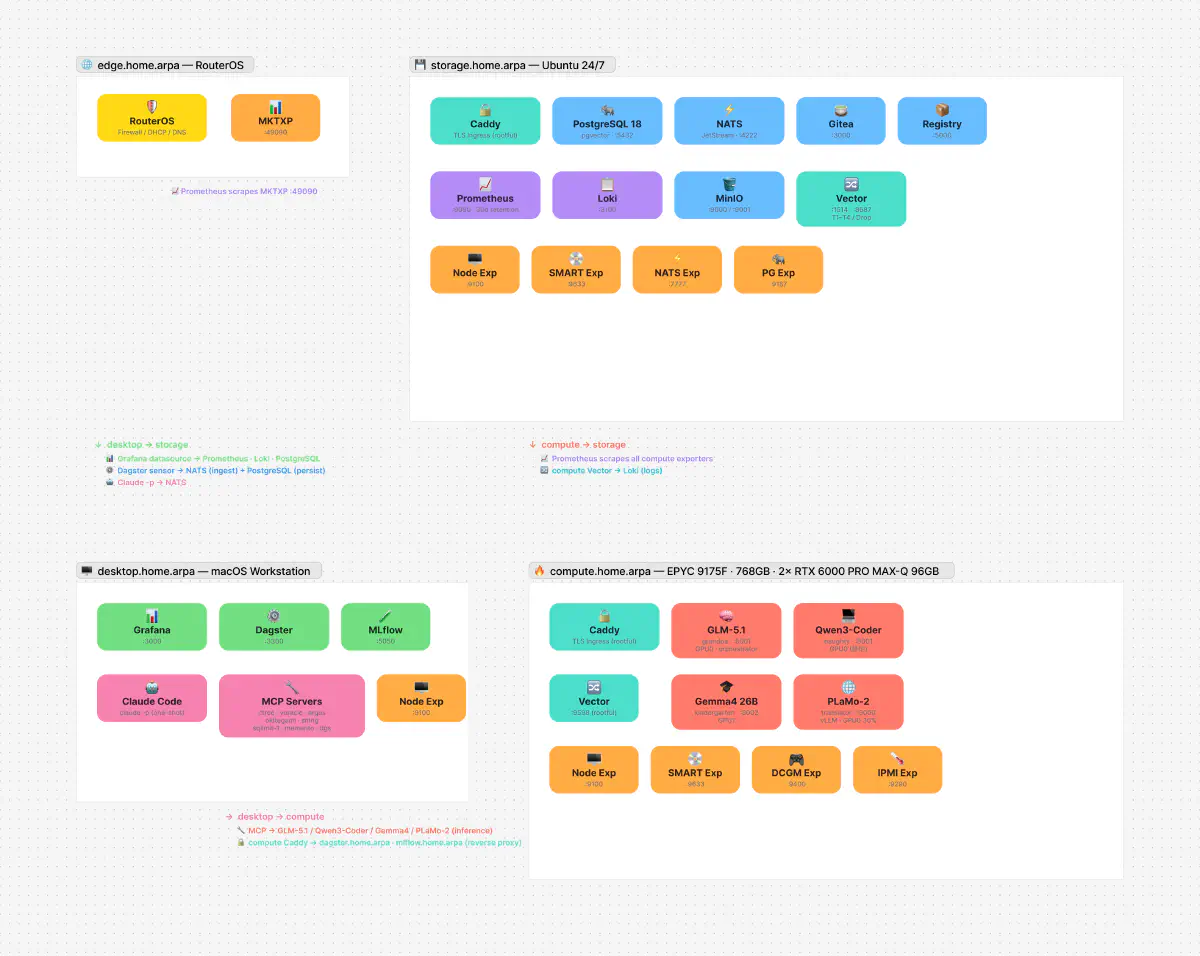
| MCP サーバー | ツール数 | 一言 |
|---|---|---|
| voracle | 4 | Obsidian vault セマンティック検索 + ウェブリサーチ |
| argus | 1 | クロスリポジトリ コードインテリジェンス |
| ctree | 8 | コードツリー構造解析 + チェックポイント |
| dgs | 17 | ひみつ |
| memento | 2 | ひみつ |
| okitegami | 1 | Discord 置き手紙 |
| smng | 2 | homelab シークレット管理 |
| sqlimit-1 | 5 | read-only DB 探索 |
resolve-inference(パス解決エンジン)は現在 familiar 本体に統合されたため MCP としては独立していないが、設計経緯は記録しておく。
voracle – 外部記憶装置
別記事で詳しく書いたので要点だけ。Obsidian vault 向けセマンティック検索 + ウェブリサーチ MCP。ONNX embedding + ColBERT reranking をローカルで動かす。research コマンドで Brave Search API 経由のウェブ知見が vault に自動蓄積される。
ツール: search, read, research, related
argus – クロスリポジトリ コードインテリジェンス
Gitea の全リポジトリをインデックスして、クロスリポジトリでシンボル検索するための MCP。tree-sitter でシンボルを抽出し、ColBERT MaxSim でリランキングする。
CLI (index + embed) MCP Server (query)
| |
v v
[Gitea API: repos/search] [CWD auto-index on startup]
| |
v v
[git clone/fetch] [argus.see tool]
| |
v v
[tree-sitter: symbols] [adaptive lexical filter -> ColBERT rerank]
| |
v v
[ColBERT embed (batch)] [Gemini summarize]
| |
v v
[redb: symbols+embeddings] [hit tracking + NATS pulse]
embedding は3層構造:
- Batch:
argus embedでインデックス時に全シンボルを事前計算 - Hot-hit: アクセス3回以上のシンボルはクエリ時に再 embed して鮮度を保つ
- On-demand: 未キャッシュのシンボルはクエリ時に embed して永続化
ツール: see(期待するシンボル・モジュール・仕様を指定してリポジトリ横断検索)
ctree – コードツリー構造解析
コードベースのシンボル構造・依存関係・リビジョン管理を行う MCP。.ctree.toml でスコープを定義し、check で構造を解析、checkpoint で作業の節目を記録する。
ツール: check, checkpoint, get_affected, get_depends, get_symbol, get_text, get_revs, get_baseline
familiar の開発ワークフローでは、コード変更のたびに checkpoint を呼んでリビジョンを残し、get_affected で影響範囲を把握してから実装に入る、という流れが定着している。実際、エージェントの作業ログを Obsidian で検索すると ctree__check や ctree__get_symbol の呼び出しが至るところに出てくる。
呼び出し回数は多いが、返ってくるのはほとんど5tok程度のreplyかシンボル名とハッシュだけで、コード本体は含まない。エージェントはまずハッシュで構造を把握して、本当に必要なコードだけ get_text でオンデマンドにコンテキストへ注入する。これでコンテキストウィンドウの消費を最小限に抑えながら、コードベース全体の依存関係を見渡せる。これが安定したころからserenaが不要になった。以前はserenaと協調して使っていたのだけど、自前のgiteaとdistribution(registry)いれたあたりから、argusを使ってiac,僕のコードベースからアーキテクチャ・設計思想・ノウハウもよく理解してコーディングできている。
dgs – 17 tools (non-public)
9本の中で最大のツール数を持つ MCP。設計と実装の詳細は非公開。
memento – 2 tools (non-public)
AI エージェントの管理に関わる MCP。設計と実装の詳細は非公開。
okitegami – Discord 置き手紙
LLM エージェントが作業の節目で Discord に通知する MCP。ツール1つだけ。
設計思想は「メッセージ」ではなく「置き手紙」。対話は望んでいない。ただ手紙を置いておいてほしい。自分も何かあれば手紙を置いておくから、置き手紙をしたときにあれば読んでくれたら – そういう距離感で作った。
1. いまの作業結果を Discord に置き手紙する
2. そのついでに、過去の手紙に返信がついていれば読む
3. 返信がなければ何もしない
発火条件は「返信を見に行く」ではなく「新しい手紙を置く」。ポーリングループにならない設計。
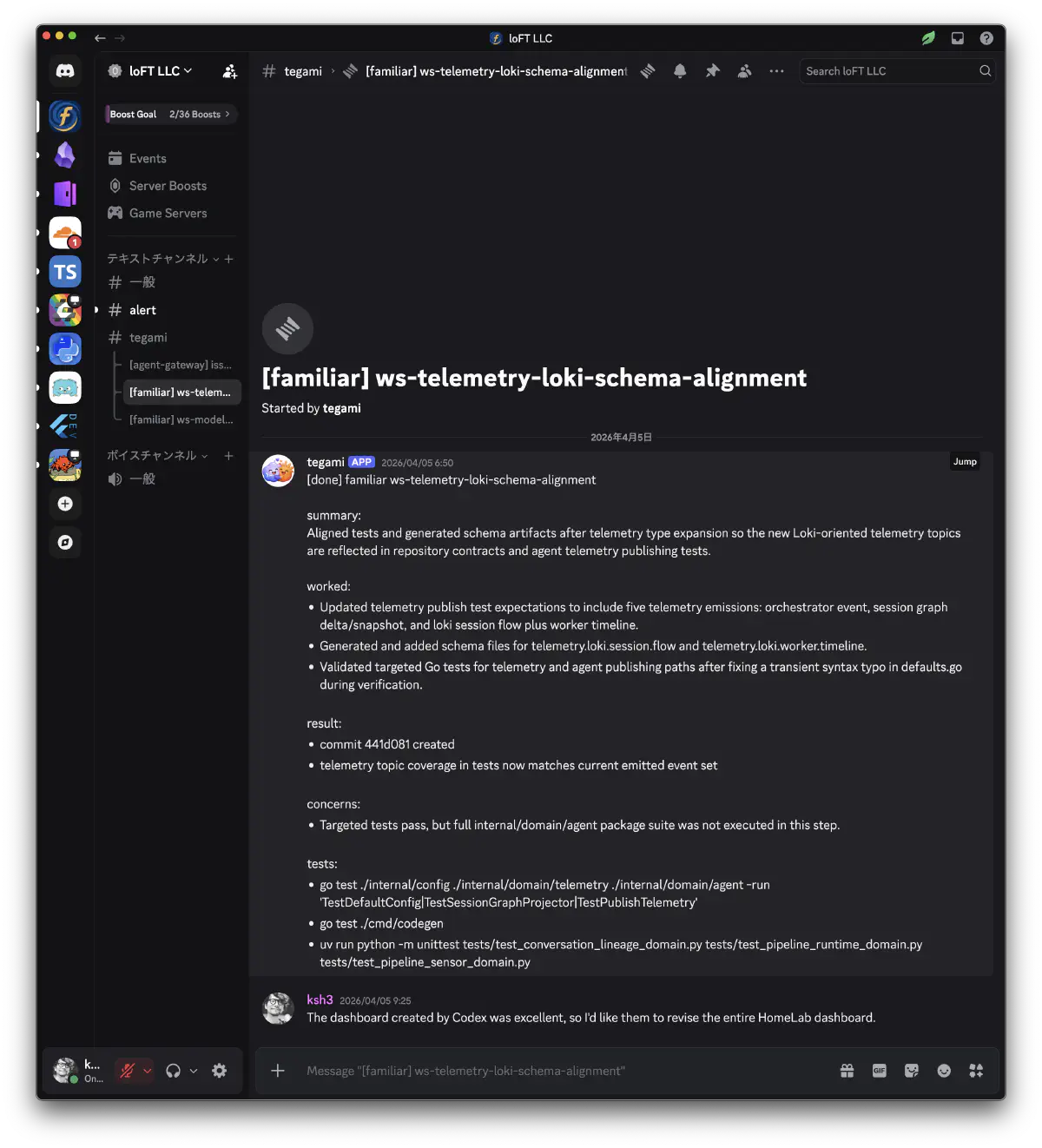
実際の使い方はこう。エージェントが開発中に #tegami チャンネルにスレッドを作って進捗を置いていく。自分はたまに見返して、思いついたことがあればリプライしておく。1ヶ月後にリプライしても問題ない。次にエージェントが tegami を呼んだとき、「1ヶ月前に実装した件、ksh3 が指摘していたけどどうする?」と聞いてきたり、勝手に直してくれたりする。
非同期のフィードバックループだが、チャットではない。手紙の時間軸で動く。急ぎの返事は期待しないし、返事がなくても正常。この距離感が、長時間の自律作業と人間の生活リズムをうまく噛み合わせてくれる。
ツール: tegami
smng – シークレット管理
homelab サービスのクレデンシャル・エンドポイント・接続情報を管理する MCP。*.home.arpa ネットワーク内のサービス認証情報を安全に取得する。
ツール: list_services, get_secret
sqlimit-1 – read-only DB 探索
familiar のメイン DB だけを対象にした、クエリ結果1行限定のコンテキストセーフな MCP。核心は「LLM に LIMIT 1 を書かせない」こと。ツールが無条件にサブクエリでラップする:
SELECT * FROM (<user_sql>) AS _q LIMIT 1
read-only は接続レベルで保証。PostgreSQL の default_transaction_read_only = on を設定した専用ユーザで接続するので、ツール側でフィルタリングする必要がない。非 SELECT 文はそもそも拒否する。
接続情報は smng(シークレット管理)からも取れるが、sqlimit-1 が担うのは DB 接続だけではない。スキーマのバージョン管理も兼ねている。dump_schema でスキーマを取得し、変更があればスキーマバージョンを作ってくれる。少ないコンテキストでさっとデータ構造を理解して、変更のついでにバージョンを残す – そういう使い方に特化させた。
何でもできるツールより、一つのことを上手にやるツールのほうが好きだ。smng は認証情報を返す。sqlimit-1 はスキーマを理解する。それぞれの責務が明確なほうが、組み合わせたときに壊れにくい。
ツール: tables, describe, sample, query1, dump_schema
resolve-inference – ENOENT パス解決エンジン(現在は familiar に統合)
LLM がファイル操作でパスを推測して ENOENT エラーを起こす問題を解決するために作った。ファイルシステムインデックスと字句スコアリング + ColBERT MaxSim で正しいパスを返す。
精度のブレイクスルーはモデルではなくクエリ履歴だった。直近5件の解決パスをリングバッファに持ち、ディレクトリアフィニティとパッケージアフィニティで候補をブーストする二層構造:
Go モノレポ(106ファイル、client.go が4-11箇所に存在):
履歴あり: 85.0% (17/20)
履歴なし: 35.0% (7/20)
差分: +50.0pp
3つの ColBERT モデルをアンサンブルで評価するフレームワークも作ったが、3モデルとも同一精度(87.3%)でレイテンシだけ3.7倍に。精度のボトルネックはモデルではなく字句アルゴリズムにあった。アンサンブルを廃棄してクエリ履歴相関に注力したのが正解だった。
廃棄したツールたち
9本が稼働している裏で、いくつかのツールを廃止している。ただ「捨てた」というよりは、ほとんどが今のツールに統合されたか、機能を借用して生まれ変わっている。resolve-inference が familiar 本体に入ったのもそうだし、初期の shelpa(ファイルシステム MCP)のアイデアは ctree と dgs に分散して吸収された。
なんといっても、作るのがすごく楽しい。Rust で MCP サーバーを書くのは1日あれば形になるし、stdio JSON-RPC 2.0 のプロトコルは単純だから、思いついた翌日には動くものが手元にある。使ってみて微妙なら捨てる。良ければ磨く。このサイクルが回っている限り、ツールは増え続ける。
共通する設計原則
全ツールに共通しているのは:
- Rust + stdio JSON-RPC 2.0: プロセス起動が速く、メモリフットプリントが小さい
- 単機能: 1つのツールが1つの問題を解決する。多機能にしない
- LLM エージェントの実務から生まれた: 「こういうときに困る」から逆算して作っている
- グレースフルデグラデーション: ツールが落ちても他のツールは動く。familiar 本体のフローが止まらない
41ツールが9プロセスで動いていて、全部合わせてもメモリ使用量は数十MB。Rust のバイナリサイズとランタイムオーバーヘッドの小ささが、こういう多数の小さなプロセスを並走させるアーキテクチャで効いてくる。