familiar - Building a Multi-Agent Development Platform That Runs Only on Local LLMs
A record of the origin and early design of familiar, a local-LLM multi-agent development platform that autonomously plans, implements, tests, and reviews on a home server without relying on cloud APIs.

Introduction
For three months starting in February, I was building a multi-agent development platform that runs only on local LLMs on my home server and is tightly connected to a data stack. Its name is familiar. The name came from the idea of both family and a familiar spirit. I wanted the processes inside it to feel like they were all working together pleasantly, so I gave the internal aliases the names grandpa, frisky, and naughty.
I recorded a 55-minute demo run and uploaded it to YouTube.
Video link: https://www.youtube.com/watch?v=tSAguJzTINs
In the demo, familiar autonomously plans, implements, tests, and reviews a Django restaurant reservation system with zero human intervention. It reached 33 commits, about 11 million tokens consumed, all 13 tests passing, and all reviewers approved.
It is not limited to Django. React is so well represented in training data that it worked without much trouble in the quick tests I ran. I also prepared Tauri, Flutter, Hugo, and the other things I like or use for work. Beyond development, I added internal variables for X-Role Header such as planning (Strategist), investing (Analyst), and PR (Spokesman), so the orchestration model itself can be plugged in and swapped out. On the worker side too, the design lets me add and plug in as many talents as needed.
This article is a retrospective on the development path of the local LLM and data platform, and on the design decisions that became visible while implementing it.
What familiar is
familiar is an execution platform that coordinates multiple arbitrary local LLMs, decomposes work into small units, executes them, retries them, integrates them, and carries them through to completion. Alongside execution, it tightly couples an observability platform and a training pipeline. It is an on-prem multi-agent system.
The human work today is the first request and the final confirmation. Eventually, I want it to be only systemctl start familiar.service. The orchestrator makes decisions and plans, assigns work to workers, and judges results. Workers handle planning, implementation, testing, review, visual design, and sometimes integration. The execution platform designs the communication protocol for each interaction, treats it as a request, and stores completion reports, evidence, artifacts, and review verdicts.
Looking back through the development records, the center of familiar was not “model optimization” or “complete runtime control.” It was about compensating for the weak points of local LLMs with an execution platform and tools. The theme was not perfection. It was survivability: how to keep going.
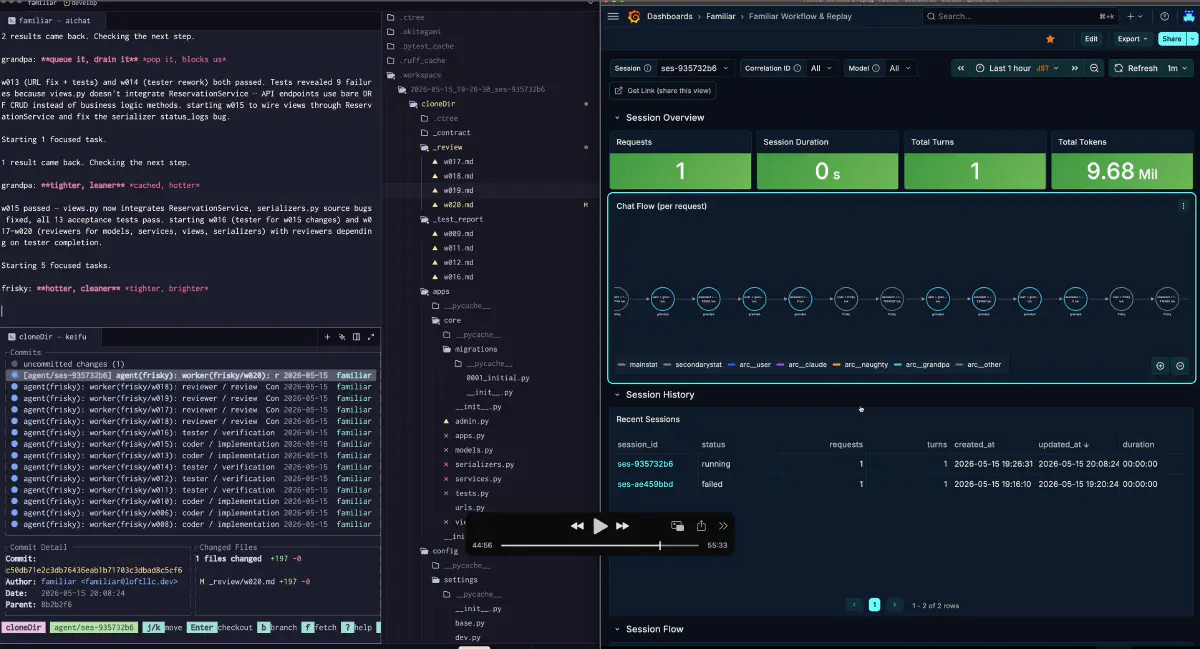
The core of the execution platform is being able to see the orchestrator’s decisions and each worker’s results on the same timeline. Which worker passed, where it failed, which prerequisite relationship was blocked, which retry worked, what caused the result, and whether it reproduces. Without that view, I cannot tell whether I should fix the instruction text, the work order, or the tool.
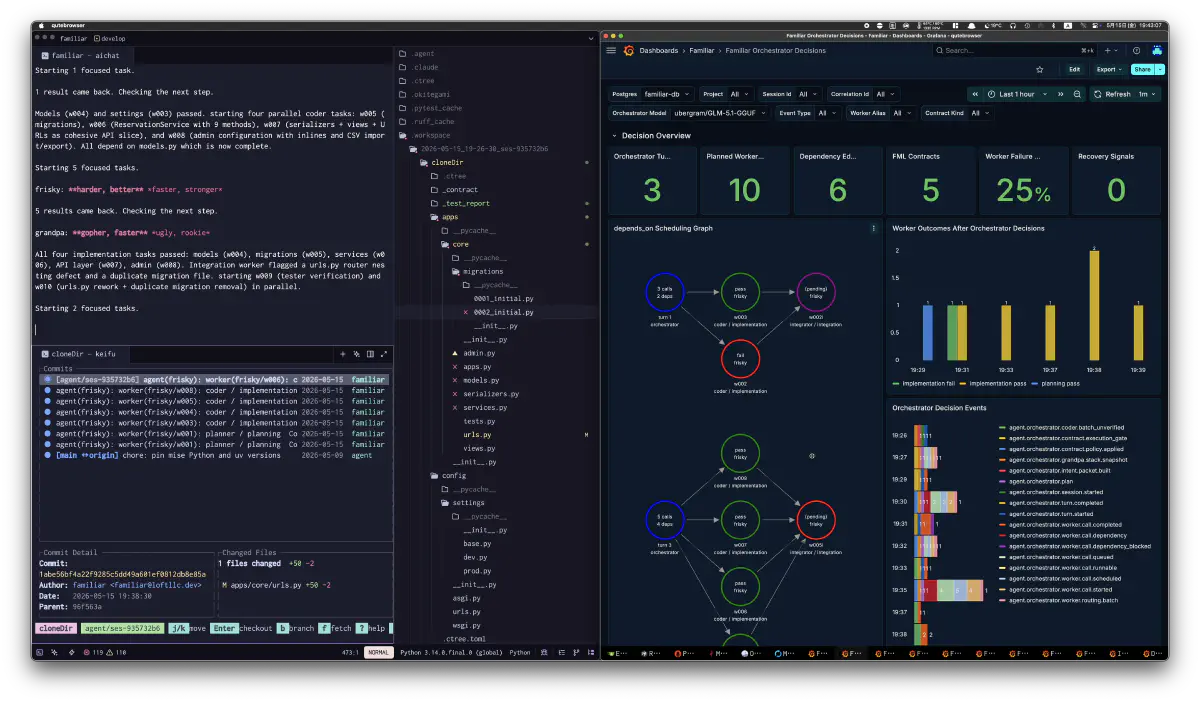
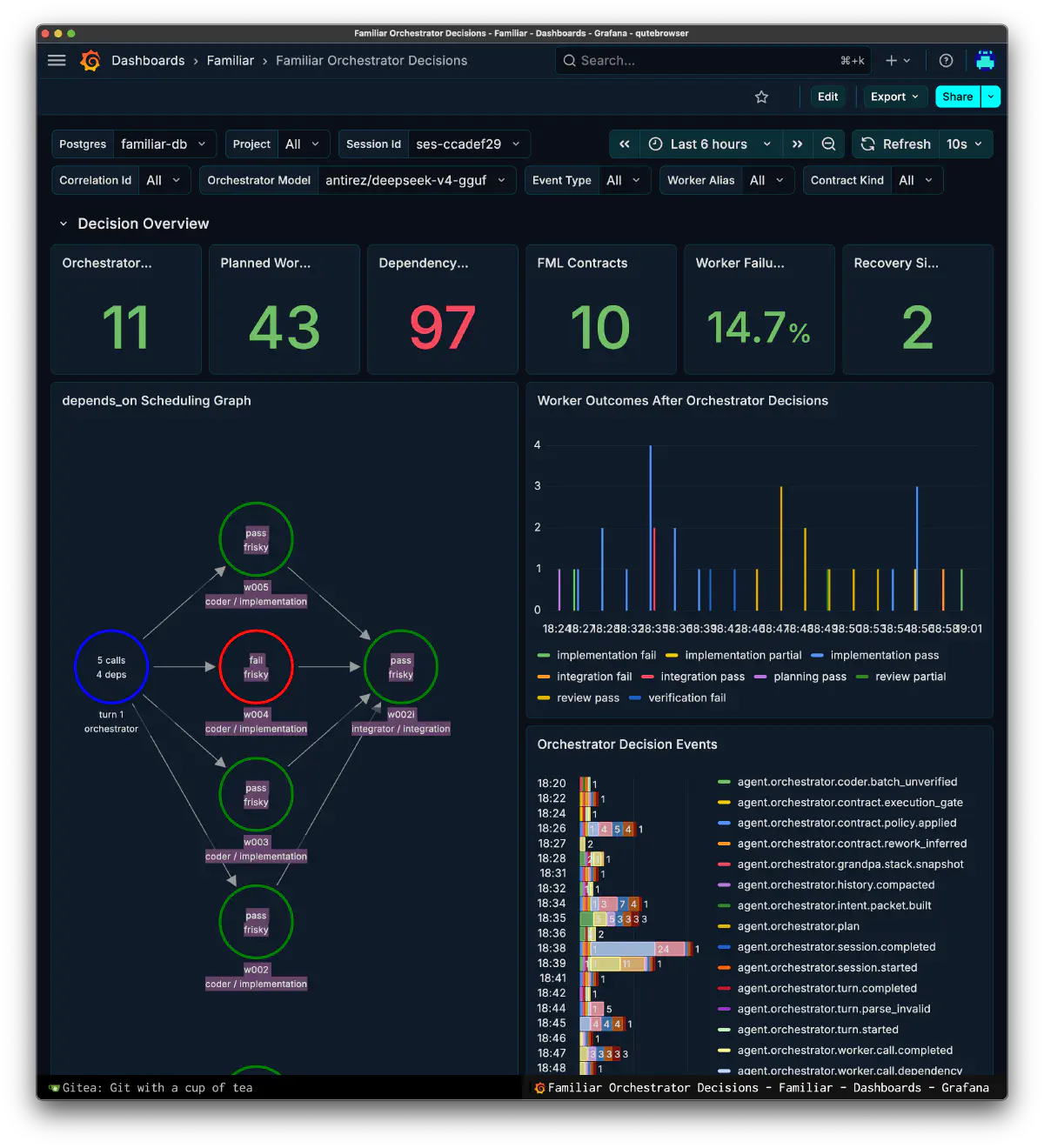
At this point, developing a model directly is not realistic for me because of development cost and data rights. I also do not know whether better ones will continue to arrive from OSS. So I archived every model with a clear enough license. grandpa can be replaced by model candidates with enough parameters, such as GLM-5.1, Kimi-K2.5, or DeepSeek V4 Flash. If a better OSS model appears, I can replace the model with one that has newer training information and compensate for experience from the datasets I have accumulated. Right now, considering license, behavior, and the rest, the most stable setup is GLM-5.1 for the orchestrator, and fast implementation-strong models with progressing MTP support, such as Qwen3.6 and gemma4, on the worker side. I was lucky that February through April had such a rich run of OSS models.
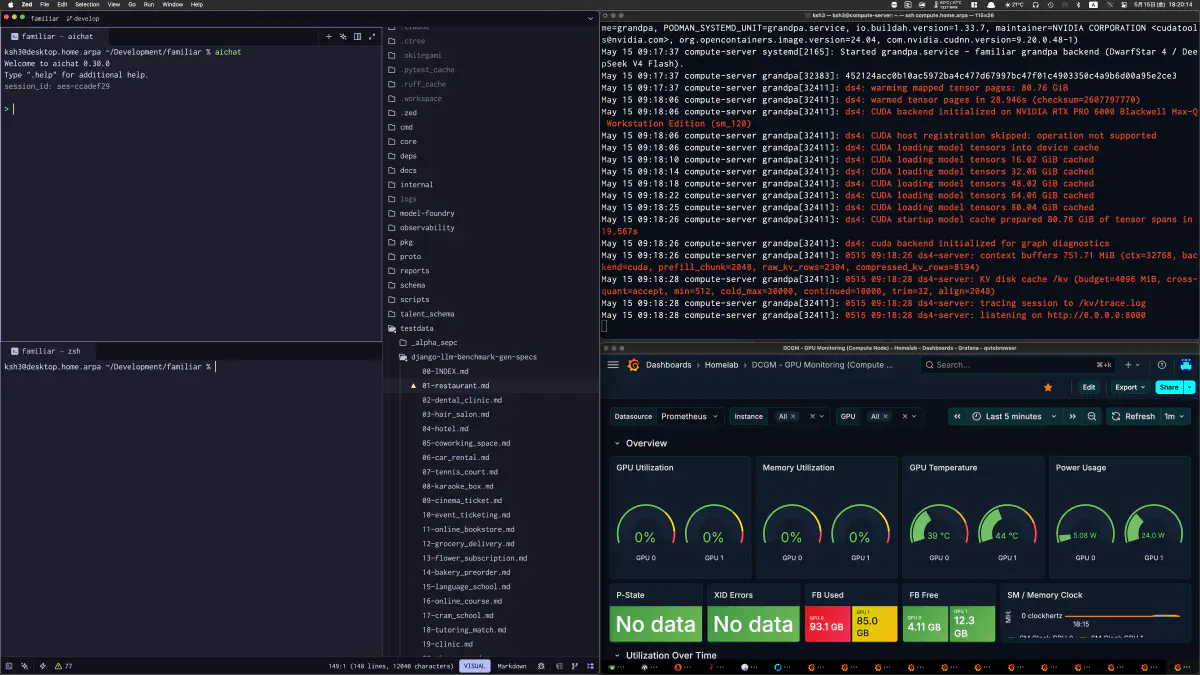
The observability side became much larger than I first expected. The development records include a Grafana Familiar folder backup and 54 synchronized generations of dashboards. As runtime implementation progressed, the viewpoints themselves multiplied: Orchestrator Decisions, Workflow & Replay, MOLsEV, C&F Latency, Arch Stats, Tool Calls, Guard Calls, LoRA/Prompt ROI, Model/Quant Failure Heatmap, and more.
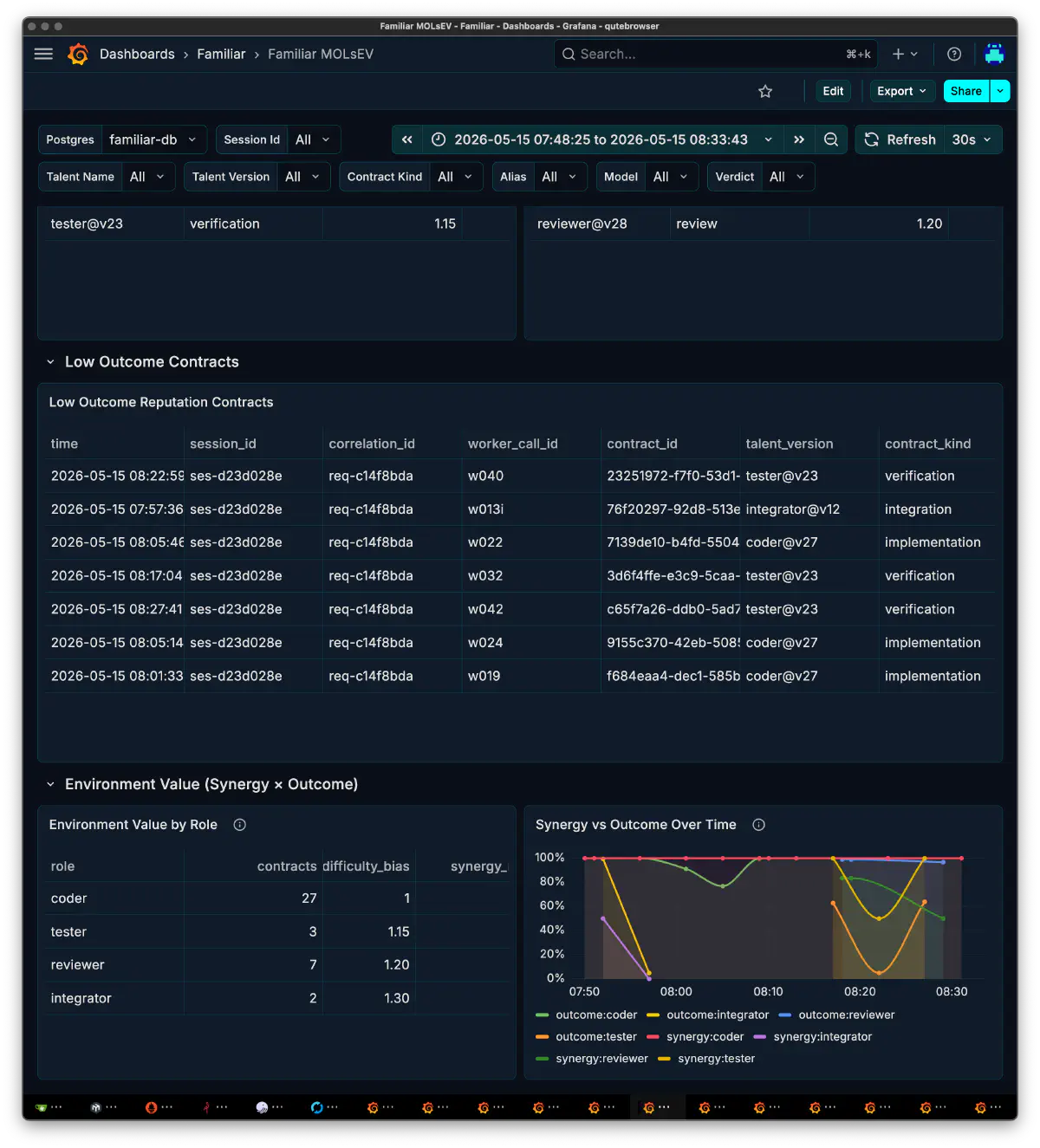
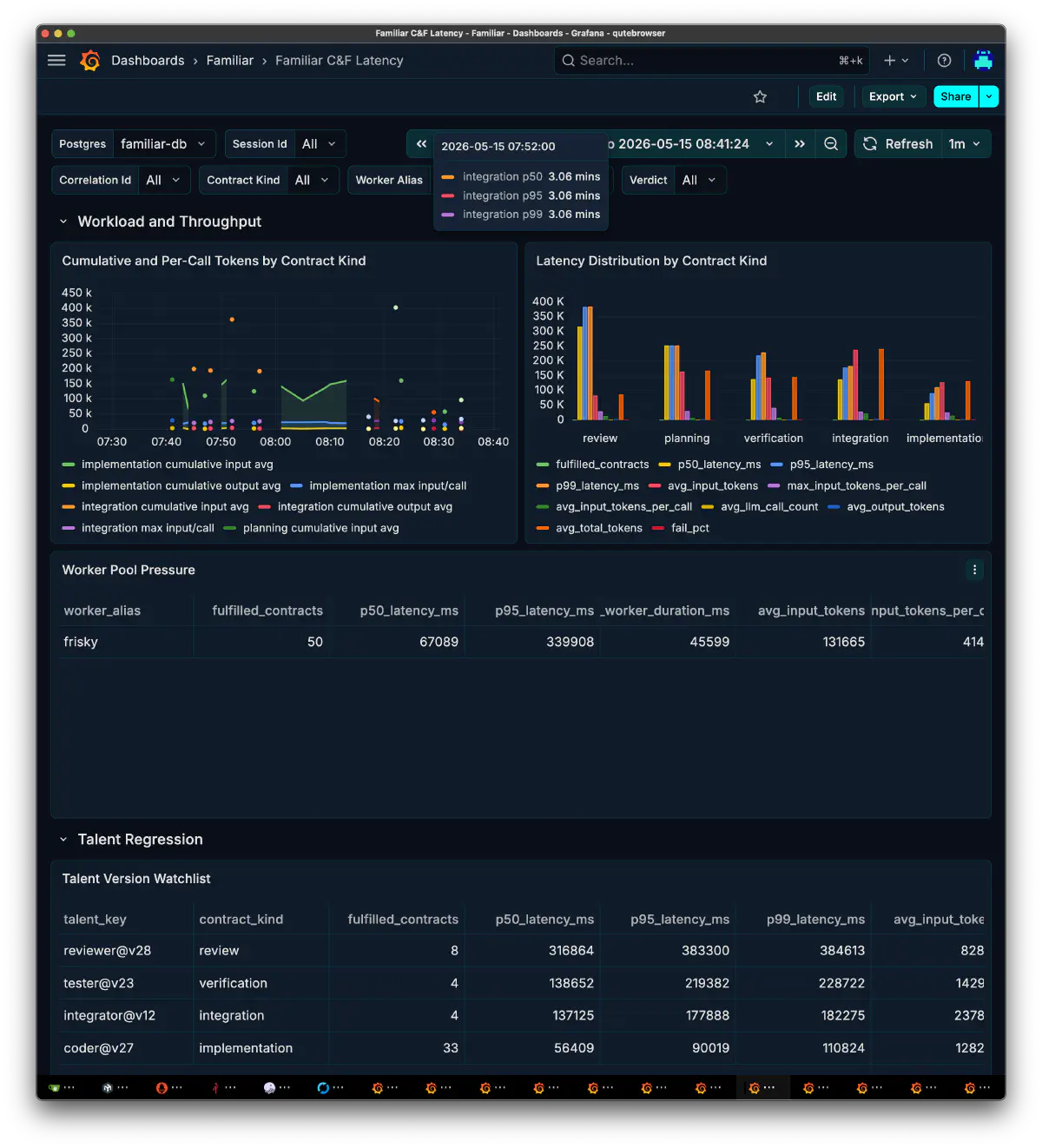
After trying many things, I understood that multi-agent systems do not stand up on prompt quality and model ranking alone. It feels more like an all-out effort, borrowing the strength of OSS wherever possible.
It started with Qwen Next
The starting point was trying Qwen Next around last July.
At that time, I felt strongly that inference would soon start shifting toward CPU inference. I do not mean that GPUs would become unnecessary. Given MoE-based optimization of inference cost, long contexts, and running multiple models at the same time, I thought the direction would move toward designing one local inference environment that includes CPU, memory bandwidth, L3 cache, storage, and networking, instead of trying to hold everything only on GPUs.
There were also growing concerns about semiconductor shortages, so around August I hurried to study what kind of machine configuration I should build.
Building PCs is a hobby of mine, but this time the price and risk were honestly large. I was able to put together the HPC configuration I wanted, so I ordered it right away. The wait was three months. The center of the build was the AMD EPYC 9175F. If you look only at the 16C/16T core count, it is an odd chip, but it has 512MB of L3 cache. If CPU is going to be central to local LLM inference, that amount of L3 cache is very attractive.
In the end, I separated the system into compute, storage, desktop, and edge.
- compute.home.arpa is the inference node. It has the EPYC 9175F, a large amount of DDR5 memory, and two NVIDIA GPUs.
- storage.home.arpa is the service node for PostgreSQL, NATS JetStream, MinIO, Gitea, OCI Registry, Prometheus, Loki, Vector, Caddy, and so on. I replaced the OS on a Mac mini Late 2018 (x86) with Linux. This model can be found used for around 30,000 yen, avoids the awkwardness around Arm, and I have come to like it a lot. When I find a good unit on Mercari, I collect it as a spare. It runs 24/7.
- desktop.home.arpa is my daily working environment. I concentrated the UI and external-network touchpoints there.
- edge.home.arpa is the network boundary: RouterOS, Step-CA, and Caddy for internal TLS.
For an individual, it was honestly an expensive configuration. I do have a company, but in reality I am just a freelance engineer. Even so, this was the one thing I had to push through.
When designing a system, the hardware configuration is the size of the canvas. The design and implementation had to fit the vessel exactly. More importantly, this was development with very little prior know-how, so I needed to try things over and over. It was not something I could just test casually on cloud resources. Now that I have built a prototype, I think it could be done with a used x86 Mac mini around 30,000 yen plus cloud GPUs, but there was no way to know that beforehand without the know-how.
If I was going to buy it, I also had to secure the time to use it heavily. So I made a plan to reduce the amount of work on a long-running client project and commit full-time from December. I prepared to step away from that work and reached the point where all that was left was to focus and build.
But in December, an engineer at a long-time client was diagnosed with a serious illness. Instead of freeing up my time, it became difficult to take time from December onward. That could not be helped. Things finally settled down in February, and I started taking care of the smaller tasks little by little.
The first thing I did was not LLMs themselves, but preparing the soil. I separated the network, separated where services would live, and separated the responsibilities of inference, persistence, observability, and the development environment. Instead of writing agents right away, I first built a place where things could run for a long time and failures could be traced.
At first it was a proxy for observing LLM usage
What I started building at first was not really familiar yet. It was a lightweight backend for observing LLM usage.
I built an API with Rust + axum and proxied requests to a backend LLM. I inserted Knowledge.Gate there to collect what prompts were sent, what responses came back, which tool calls happened, and where things got stuck. Around it I put Dagster, MLflow, NATS, Prometheus, and Grafana.
At that point, my interest was closer to “making it possible to observe what happens when LLMs are used for development work” than to “building an autonomous development agent.” Whether using a cloud API or a local model, staring only at LLM output is not enough to improve anything. If I wanted to improve it, I needed to keep the usage history, the shape of failures, token consumption, and the behavior of each model.
But as development progressed, I started to see what I really wanted to design.
It was not just an LLM proxy. What should be observed, what should be judged, how far should autonomy go, where should those decisions live, how should the system return after failure, and which logs should be used for training and improvement. A mechanism that could be refined over time. That was the overall picture that started to appear.
At that point, I threw away the design and implementation that had started as a Rust + axum API and replaced it with Go. I chose Go because goroutines and channels made parallel execution, state management, scheduling, and subscriptions easier to handle. Eventually I wanted a platform that could run autonomously in something close to a single binary, rather than a structure that carried external MCP tools and Python tools.
In the video I stop the session at the end, but the implementation can already receive requests through external pub/sub. I have also already designed the mechanism that takes tasks from a configured directory, runs by itself while evicting KV, and settles into success | fail | loop. One major reason for choosing Go was that waiting and resuming in that loop has low cost and fits well with a resident orchestration runtime.
Model selection started by touching models and building intuition
Once the basic shape was in place, I gradually started selecting models around January.
At this time, I still did not have enough focused time to build large features. So I treated model work as lighter work: download a model, start it, send small tasks, and observe behavior. There are things benchmark tables do not tell you: how prompts collapse, tool-call habits, persistence on long text, empty outputs, XML corruption, forgotten tool closures, how it waits during CPU offload, and how far quantization can be pushed. Those things only become visible by actually touching the model.
The Hugging Face archive on the storage side from that period was almost a work log in itself.
ksh3@storage-server:~$ ls -ltr /srv/archive/cold/hf/hub/
total 0
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 19:44 models--Qwen--Qwen3-VL-32B-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 20:21 models--AaryanK--IQuest-Coder-V1-40B-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 4 23:30 models--NousResearch--Hermes-4.3-36B
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 00:11 models--unsloth--gpt-oss-120b-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 01:56 models--NousResearch--Hermes-4-70B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Jan 5 08:23 models--lmstudio-community--Llama-4-Scout-17B-16E-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 10:23 models--nvidia--Llama-3.3-70B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 11:33 models--nvidia--Llama-4-Scout-17B-16E-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 11:46 models--Firworks--command-a-reasoning-08-2025-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 19:59 models--Elias-Schwegler--IQuest-Coder-V1-40B-Loop-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 21:51 models--miromind-ai--MiroThinker-v1.5-30B
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 22:37 models--IQuestLab--IQuest-Coder-V1-40B-Loop-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Jan 9 22:37 models--IQuestLab--IQuest-Coder-V1-40B-Instruct
drwxr-xr-x 6 ksh3 ksh3 85 Jan 11 01:03 models--unsloth--Llama-4-Maverick-17B-128E-Instruct-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 01:47 models--pfnet--plamo-2-translate
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 02:15 models--google--functiongemma-270m-it
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 02:17 models--Firworks--gemma-3-270m-it-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 05:44 models--BCCard--gemma-3-27b-it-NVFP4A16
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 07:01 models--openai--gpt-oss-20b
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 07:27 models--google--gemma-3-27b-it
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 10:46 models--GAlex535--Qwen3-Coder-30B-A3B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 13:17 models--openai--gpt-oss-120b
drwxr-xr-x 5 ksh3 ksh3 64 Jan 11 15:20 models--mratsim--Monstral-123B-v2-NVFP4
drwxr-xr-x 6 ksh3 ksh3 85 Jan 11 15:37 models--Lightricks--LTX-2
drwxr-xr-x 5 ksh3 ksh3 64 Jan 12 01:04 models--ChristianAzinn--mixtral-8x22b-v0.1-imatrix
drwxr-xr-x 5 ksh3 ksh3 64 Jan 20 08:57 models--Firworks--NVIDIA-Nemotron-3-Nano-30B-A3B-nvfp4
drwxr-xr-x 5 ksh3 ksh3 64 Jan 20 10:13 models--Qwen--Qwen3-Coder-30B-A3B-Instruct-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Jan 22 04:07 models--zai-org--GLM-4.7-Flash
drwxr-xr-x 5 ksh3 ksh3 64 Feb 5 15:11 models--nvidia--NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 13 22:57 models--unsloth--Qwen3-Next-80B-A3B-Thinking-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 14 00:46 models--AesSedai--Step-3.5-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 06:15 models--unsloth--GLM-5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 11:44 models--ubergarm--GLM-4.7-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 18:10 models--DavidAU--GLM-4.7-Flash-Uncensored-Heretic-NEO-CODE-Imatrix-MAX-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 15 19:11 models--bartowski--Qwen_Qwen3-Coder-Next-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 16 00:52 models--ubergarm--DeepSeek-V3.2-Speciale-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 16 03:44 models--DavidAU--Openai_gpt-oss-120b-NEO-Imatrix-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 17 08:49 models--ubergarm--MiniMax-M2.5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 17 19:40 models--GadflyII--Qwen3-Coder-Next-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 15:12 models--ACE-Step--Ace-Step1.5
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 15:41 models--mistralai--Voxtral-Mini-4B-Realtime-2602
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 17:18 models--black-forest-labs--FLUX.2-klein-9B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 18 23:14 models--LiquidAI--LFM2-8B-A1B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 00:09 models--LiquidAI--LFM2-8B-A1B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 05:58 models--LiquidAI--LFM2.5-1.2B-Thinking
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 06:03 models--LiquidAI--LFM2.5-VL-1.6B
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 06:07 models--LiquidAI--LFM2.5-1.2B-Instruct
drwxr-xr-x 5 ksh3 ksh3 64 Feb 19 19:49 models--ubergarm--Devstral-2-123B-Instruct-2512-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 23 20:30 models--AesSedai--MiniMax-M2.5-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 24 06:41 models--nvidia--Qwen3-Next-80B-A3B-Instruct-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 24 06:47 models--nvidia--Qwen3-Next-80B-A3B-Thinking-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 01:54 models--AesSedai--Qwen3.5-35B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 03:16 models--AesSedai--Qwen3.5-122B-A10B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 16:57 models--Sehyo--Qwen3.5-122B-A10B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Feb 25 19:39 models--Qwen--Qwen3.5-27B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 2 04:18 models--mmnga-o--NVIDIA-Nemotron-Nano-9B-v2-Japanese-gguf
drwxr-xr-x 5 ksh3 ksh3 64 Mar 2 06:23 models--nvidia--NVIDIA-Nemotron-Nano-9B-v2-Japanese
drwxr-xr-x 5 ksh3 ksh3 64 Mar 3 02:56 models--bartowski--Qwen_Qwen3.5-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 3 03:53 models--ubergarm--Qwen3.5-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 05:21 models--perplexity-ai--pplx-embed-context-v1-0.6b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 05:24 models--perplexity-ai--pplx-embed-v1-0.6b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 08:22 models--perplexity-ai--pplx-embed-context-v1-4b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 6 08:23 models--perplexity-ai--pplx-embed-v1-4b
drwxr-xr-x 5 ksh3 ksh3 64 Mar 14 00:30 models--AesSedai--NVIDIA-Nemotron-3-Super-120B-A12B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 14 11:03 models--nvidia--NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 17 23:30 models--fishaudio--s2-pro
drwxr-xr-x 5 ksh3 ksh3 64 Mar 17 23:36 models--mradermacher--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-i1-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 18 00:00 models--bartowski--Qwen_Qwen3.5-4B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 18 16:24 models--AesSedai--Mistral-Small-4-119B-2603-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 23 04:31 models--AesSedai--Nemotron-Cascade-2-30B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 03:02 models--mconcat--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 03:37 models--Qwen--Qwen3.5-9B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 04:54 models--chankhavu--Nemotron-Cascade-2-30B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:50 models--Jackrong--Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:57 datasets--OpenMOSS-Team--OmniAction
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 21:59 datasets--Roman1111111--claude-opus-4.6-10000x
drwxr-xr-x 5 ksh3 ksh3 64 Mar 27 22:11 datasets--nvidia--Nemotron-Terminal-Corpus
drwxr-xr-x 5 ksh3 ksh3 64 Mar 28 05:43 models--nvidia--Nemotron-Cascade-2-30B-A3B
drwxr-xr-x 5 ksh3 ksh3 64 Mar 28 09:17 datasets--nvidia--Nemotron-Terminal-Synthetic-Tasks
drwxr-xr-x 6 ksh3 ksh3 85 Mar 29 14:33 models--HauhauCS--Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 17:33 models--Qwen--Qwen3.5-4B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 18:47 models--Qwen--Qwen3.5-35B-A3B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 29 18:55 models--mistralai--Mistral-Small-4-119B-2603-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 08:24 models--Qwen--Qwen3.5-9B-Base
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 08:24 models--zed-industries--zeta-2
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 11:24 models--nvidia--MiniMax-M2.5-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 12:59 models--sentence-transformers--all-MiniLM-L6-v2
drwxr-xr-x 5 ksh3 ksh3 64 Mar 30 13:02 models--datalab-to--chandra-ocr-2
drwxr-xr-x 5 ksh3 ksh3 64 Apr 2 14:29 datasets--ianncity--KIMI-K2.5-450000x
drwxr-xr-x 5 ksh3 ksh3 64 Apr 2 14:42 datasets--open-index--hacker-news
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 00:49 models--bartowski--google_gemma-4-26B-A4B-it-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 02:31 models--lightonai--LateOn-Code-edge
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 02:32 models--mixedbread-ai--mxbai-edge-colbert-v0-17m
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 11:33 models--google--gemma-4-26B-A4B-it
drwxr-xr-x 5 ksh3 ksh3 64 Apr 3 17:15 models--ubergarm--Step-3.5-Flash-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 6 07:00 models--bartowski--Qwen_Qwen3.5-9B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 8 15:31 datasets--nohurry--Opus-4.6-Reasoning-3000x-filtered
drwxr-xr-x 5 ksh3 ksh3 64 Apr 8 16:17 datasets--ianncity--KIMI-K2.5-1000000x
drwxr-xr-x 6 ksh3 ksh3 85 Apr 8 16:38 models--ubergarm--Qwen3-Coder-Next-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 11 05:57 models--google--translategemma-4b-it
drwxr-xr-x 5 ksh3 ksh3 64 Apr 11 06:20 models--llm-jp--llm-jp-4-32b-a3b-base
drwxr-xr-x 5 ksh3 ksh3 64 Apr 12 18:35 models--MiniMaxAI--MiniMax-M2.7
drwxr-xr-x 6 ksh3 ksh3 85 Apr 13 02:52 models--ubergarm--MiniMax-M2.7-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 14 09:24 models--llm-jp--llm-jp-4-32b-a3b-thinking
drwxr-xr-x 5 ksh3 ksh3 64 Apr 16 09:22 models--AesSedai--Qwen3.5-397B-A17B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 17 08:51 models--AesSedai--Qwen3.6-35B-A3B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 20 09:02 models--cyberagent--CAT-Translate-7b
drwxr-xr-x 5 ksh3 ksh3 64 Apr 20 14:25 datasets--Jackrong--GLM-5.1-Reasoning-1M-Cleaned
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 00:11 models--openai--privacy-filter
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 15:41 models--Qwen--Qwen3.6-27B
drwxr-xr-x 5 ksh3 ksh3 64 Apr 23 16:36 models--Qwen--Qwen3.6-27B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 00:41 models--huihui-ai--Huihui-GLM-5.1-abliterated-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 11:19 models--deepseek-ai--DeepSeek-V4-Flash
drwxr-xr-x 5 ksh3 ksh3 64 Apr 24 15:24 datasets--Modotte--CodeX-2M-Thinking
drwxr-xr-x 5 ksh3 ksh3 64 Apr 27 01:44 models--nsparks--DeepSeek-V4-Flash-FP4-FP8-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 27 16:02 models--zai-org--GLM-5.1
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 16:51 models--Qwen--Qwen3.6-35B-A3B-FP8
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 17:22 models--Qwen--Qwen3.6-35B-A3B
drwxr-xr-x 5 ksh3 ksh3 64 Apr 29 17:43 models--AesSedai--Kimi-K2.6-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 Apr 30 18:40 models--RedHatAI--DeepSeek-V4-Flash-NVFP4-FP8
drwxr-xr-x 5 ksh3 ksh3 64 May 1 16:03 datasets--AlicanKiraz0--Cybersecurity-Dataset-Fenrir-v2.1
drwxr-xr-x 5 ksh3 ksh3 64 May 1 22:50 models--ubergarm--GLM-5.1-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 2 09:46 models--mistralai--Mistral-Medium-3.5-128B
drwxr-xr-x 5 ksh3 ksh3 64 May 2 09:55 models--mistralai--Mistral-Medium-3.5-128B-EAGLE
drwxr-xr-x 5 ksh3 ksh3 64 May 2 14:43 models--RedHatAI--Qwen3.6-35B-A3B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 3 14:55 models--ubergarm--Qwen3.6-27B-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 4 03:57 models--sakamakismile--Qwen3.6-27B-Text-NVFP4-MTP
drwxr-xr-x 5 ksh3 ksh3 64 May 4 15:06 datasets--Kassadin88--GLM-5.1-OpenThoughts3-Distill
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:01 models--LilaRest--gemma-4-31B-it-NVFP4-turbo
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:04 models--nvidia--Gemma-4-31B-IT-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 7 14:05 models--google--gemma-4-31B-it-assistant
drwxr-xr-x 5 ksh3 ksh3 64 May 9 01:20 models--RecViking--Mistral-Medium-3.5-128B-NVFP4
drwxr-xr-x 5 ksh3 ksh3 64 May 10 02:52 models--ubergarm--Kimi-K2.6-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 10 07:18 models--google--gemma-4-31B-it
drwxr-xr-x 5 ksh3 ksh3 64 May 10 10:25 models--Zyphra--ZAYA1-74B-preview
drwxr-xr-x 5 ksh3 ksh3 64 May 12 16:37 models--AesSedai--MiMo-V2.5-Pro-GGUF
drwxr-xr-x 5 ksh3 ksh3 64 May 12 17:21 models--antirez--deepseek-v4-gguf
ksh3@storage-server:~$
I tried general-purpose but nonstandard models such as uncensored ones, distinctive storytellers, image generation, video generation, security use cases, coding, and OCR. I tried every use case that came to mind. This list is not just a collection. It is the history of exploring which model could fit which role, which quantization could survive locally, and what behavioral quirks each one had.
I tried Claude and immediately regretted waiting so long
I really like writing code.
Because of that, I had been stubborn about AI coding assistance and used only inline autocomplete. Copilot-like tools are convenient, but I wanted to remain the one writing the code. That feeling was strong.
In February this year, I tried Claude. The trigger was seeing its statement against military use and thinking it was good. Once I actually used it, I immediately regretted it: “Why didn’t I start using this sooner?”
As I have gotten older, daily coding has given me shoulder stiffness and tendinitis. Sometimes I thought I might have to retire in a few years. But using Claude convinced me that I could keep doing the development work I love. That is why I wanted a system that would complement my habits, know-how, design philosophy, and criteria for what to discard.
At just that time, the overall architecture of my local platform was also starting to take shape. So around March, I started bringing Claude into my development work. The initial goal was not to embed Claude or Codex as-is. I wanted to use them as a small dependency: pass prompts to claude -p or Codex, make them do work similar to a local LLM orchestrator candidate, observe that behavior, and gradually move toward local 100B-class orchestrator model candidates that could run through CPU inference.
In April, I decided to break it once
Anthropic’s policy shift in April changed the situation.
Calling claude -p from a subprocess and letting an agent use it autonomously looked like a gray area. I also saw scattered Reddit posts about bans. So I destroyed all implementation related to Claude and Codex.
That hurt. It meant throwing away something that had finally started moving. But what I understood at that point was that what I truly needed was not Claude itself, but knowledge of orchestration.
At what granularity should tasks be divided? What should be given to workers, and what makes them fail? Which failures come back with retry, and which failures require changing the design? When should review happen? Who should integrate collisions from parallel implementation? I needed to observe and accumulate those decisions inside my own platform, without relying on the behavior of external tools.
That is when I started focusing on Vector, Tempo, Alloy, and PostgreSQL-based observability tables.
That was a good direction.
Agent behavior cannot be understood by simply staring at logs. Only when plan, dispatch, worker result, tool call, token usage, task failure, review verdict, and recovery are traceable within the same correlation can I start thinking about why it moved that way.
Around this point, Grafana became more than a metrics display. It became the work surface for reading familiar’s thought process. The dashboards increased too, and I could switch viewpoints by role, task, tool call, latency, and more.
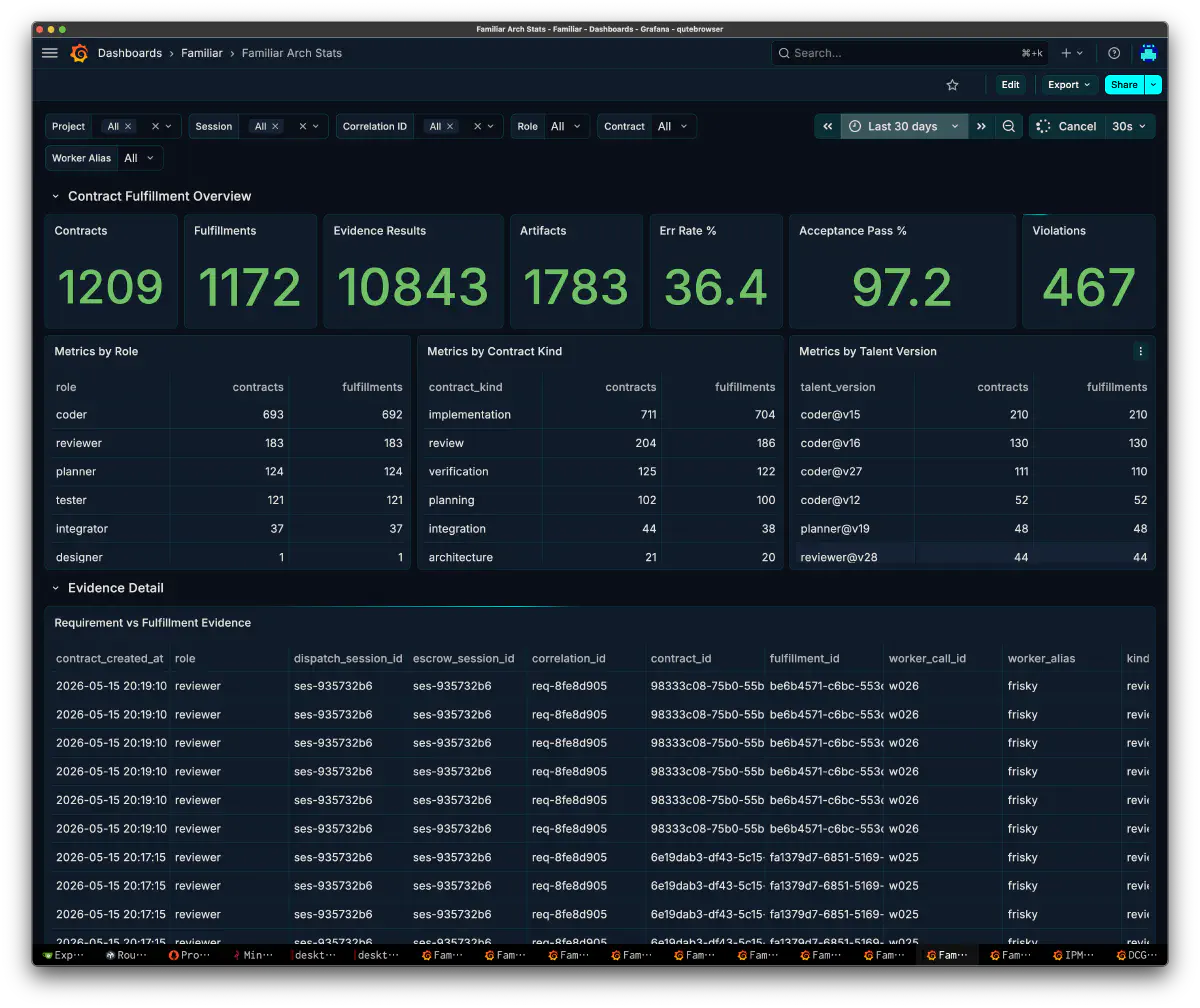
Once I could observe it, the loop between thinking and trying began. I looked at Grafana and PostgreSQL. I read sessions that did not go well. While taking a walk, I would sometimes look at the surrounding nature and suddenly understand, “Maybe it is moving like this.” Then I would come back, change the implementation shape, and run it again.
In the end, removing Claude and Codex gave me the chance to understand the system from the beginning. I found the form of the experiments I needed to repeat, and the PDCA loop began to turn.
I was building tools more than the main body
Around March, while continuing model selection and behavior observation, I felt that local LLMs needed support for the parts they were bad at.
It is not as simple as local LLMs being weaker than the giant cloud models. Their weak points are different: retaining memory over long contexts, ambiguous file discovery, interpreting execution results, state management to avoid repeating the same failure, and deciding which information should be carried into the next turn. If I expected the model alone to handle too much of that, the system broke quickly.
So rather than making the main body fat with details, I first needed to observe the whole behavior and build surrounding tools for the common problems.
In the end, I built about 15 MCP, management, and debugging tools. My feeling at the time was roughly 20% familiar core and 80% tool development. Instead of trapping agent intelligence inside prompts, I was building scaffolding outside it for observation, search, structuring, verification, and recovery.
It was natural that observability tools became numerous. An LLM itself is like a function whose return value cannot be read. You pass in input and it returns something, but you cannot see its internal state. On top of that, even the same input changes behavior depending on context, temperature, the immediately preceding failure, and tool use. Chaining multiple models and then trying to inspect causality makes it difficult.
That is why the final result is not the only thing to watch. If I only look at the result, it ends at “success” or “failure.” What I needed was to understand the whole behavior and its changes. Where is the causal point? Why did it call this tool? What is creating cognitive load? Which failures come back through rework, and which failures require a permanent fix?
This idea appears directly in the design of familiar’s MCP tools. In other words, take what is unclear, turn it into an invariant function on the runtime side, and make it understandable. The work was sorting and organizing that boundary.
To do that, I also had to shift away from some practices that I had considered good development.
I prefer programs without comments. I attach labels, but I think explanation should be done through symbols. Looking at the code outline should be enough to understand a lot. Even without looking at details, the symbols of the tests I implemented should reveal the intent.
This is not about whether comments are good or bad. To me, it is about consideration for myself and for others. Writing a comment means, as a result, that I want someone to read it. So I try to make things understandable without reading extra text: I think about symbol names repeatedly, change them, and align the outline. I try to reduce how much someone has to read. That is my kind of consideration, and in that sense, my comment.
But that was my way of thinking. In familiar, the good code was the environment where the LLM doing the implementation could work comfortably. Comments were necessary, and labels for good searching were necessary too. Once I stood in the other side’s position, what needed to be implemented became clearer.
As we gain years of coding experience, we tend to like structured typed data. But for data passed into an LLM’s context, type-backed structure is not always the right answer. This was another major realization.
Repeated forms can leave noise and residue. Conversely, a more dynamic shape can hide things that the LLM does not need to know. In other words, it can separate concerns. My understanding of these so-called antipatterns gradually progressed too. Good and bad are only interpretations based on convenience.
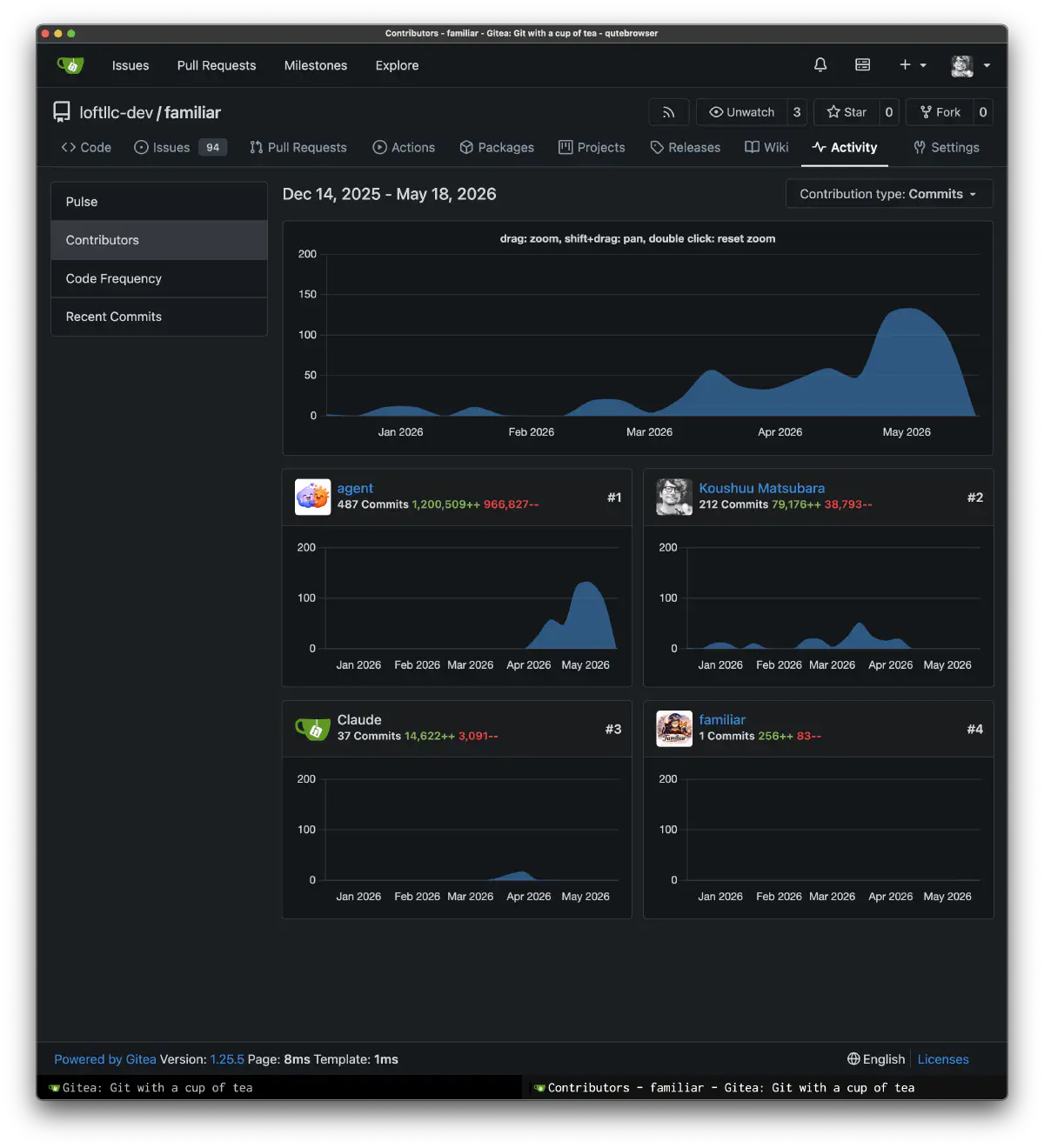
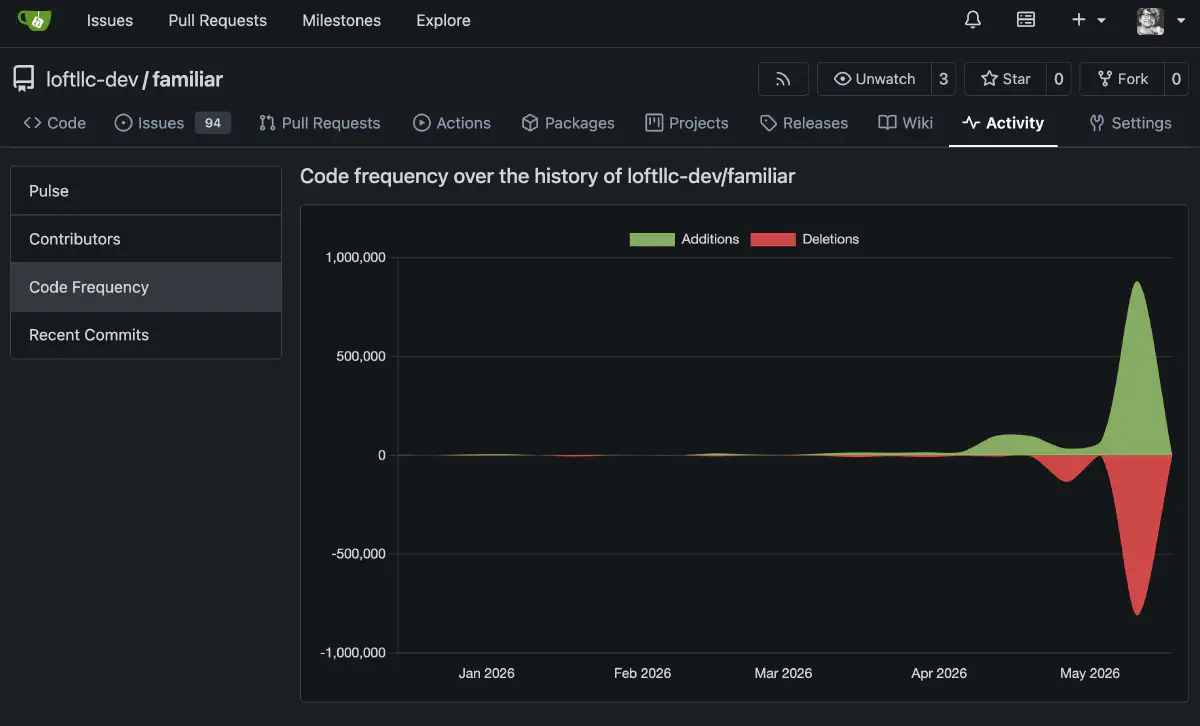
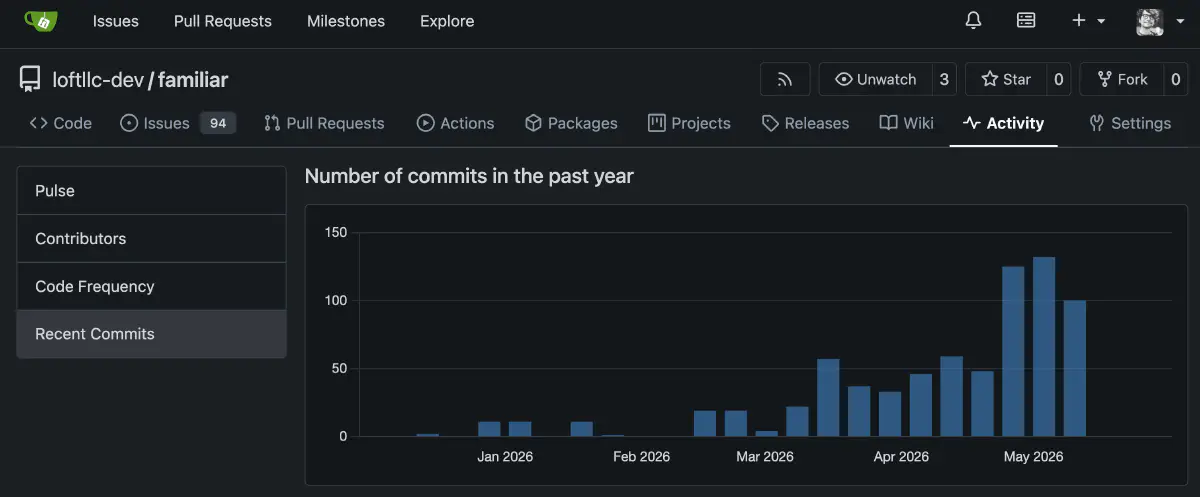
I finally feel like I have reached the starting line of development. There is still a lot to do: training, generation management, and more. I have been working intensely for the last few months, so I wanted to leave this as a milestone record. If I get the chance, I want to write the next part too.