Go + NATS + Dagster AI Orchestration Platform: Design Philosophy and Middleware Selection
Go(Gin) OpenAI/Anthropic-compatible proxy, NATS JetStream event relay, Dagster sensor-driven job execution, pgvector ANN search, ColBERT reranking. Complete design record of a 3-host local AI orchestration platform.

Conclusion
To integrate LLMs into operational pipelines, an OpenAI/Anthropic-compatible API gateway was built in Go. The gateway handles RAG orchestration on incoming requests and publishes events to NATS JetStream in a fire-and-forget pattern. On the consumption side, Dagster daemon sensors pull from JetStream and execute jobs directly. Telemetry is collected by Vector (Rust) subscribing to NATS and forwarding to Prometheus/Loki.
The core design principle: “the gateway only publishes, each middleware consumes independently.” This decision eliminated Dagster dependencies from the gateway code, fully decoupling deployments.
An initial prototype was designed and implemented in Rust (axum). After that experience, the system was fully migrated to Go. Managing async contexts for SSE relay + NATS subscription + PG/pgvector writes simultaneously was verbose in Rust — goroutine + channel fits this pattern more naturally.
Prerequisites
- Language: Go 1.25, Gin framework
- Messaging: NATS 2.11 (JetStream enabled)
- Orchestration: Dagster (Python) — daemon + sensor + asset materialization
- Data store: PostgreSQL 18 + pgvector (JIT enabled)
- Telemetry: Vector 0.45 (Rust) → Prometheus + Loki + Grafana
- Inference backends: vLLM, llama.cpp, LM Studio
- Embedding + Reranker: multi-bert-inference — Rust (Axum) + ONNX Runtime (INT8, ~17MB, ~10ms). ColBERT 256d embed + 64d token MaxSim rerank. DB-free, gRPC 256d vec direct transmission (~1KB/candidate)
- Containers: Podman rootless + podman-compose
- Host topology: 3 hosts (storage server / desktop mac / compute server)
Design Decisions
Layered Architecture
Following Clean Architecture dependency direction rules: Transport → Domain → Infrastructure.
Client (opencode CLI, API consumer)
|
v
Transport Layer (Gin) [internal/transport/http/]
|-- middleware: RequestContext -> Logger -> Recovery
|-- v1/ handlers (OpenAI/Anthropic compatible endpoints)
|-- Request parsing and validation
+-- Presentation DTO conversion
|
| Presentation Layer [pkg/openai/, pkg/anthropic/]
| +-- OpenAI/Anthropic compatible request/response DTOs
|
v
Domain Layer [internal/domain/]
|-- knowledge/ RAG orchestration
|-- llm/ Multi-backend LLM routing
|-- vectorstore/ Vector search (pgvector ANN)
+-- pipeline/ Pipeline integration (NATS publish, fire-and-forget)
|
v
Infrastructure Layer [internal/infra/]
|-- vllm/ vLLM client
|-- llamacpp/ llama.cpp client
|-- lmstudio/ LM Studio client
|-- postgres/ PostgreSQL + pgvector
|-- nats/ NATS JetStream publish
|-- vector/ Vector telemetry publish
+-- reranker/ multi-bert-inference gRPC client
The Domain layer has zero external dependencies. Adding LLM backends or changing data stores only requires swapping Infrastructure layer implementations.
Gateway Is Publish-Only
The gateway only publishes to NATS. No subscribing, no triggering. Consumers (Dagster sensor, Vector) independently pull/subscribe.
Rationale:
- No Dagster dependency in gateway code → deployment isolation
- Adding or changing consumers has zero impact on the gateway
- Gateway failures do not propagate to the pipeline side
Dagster Sensor with JetStream Pull
Dagster daemon acts as a durable consumer, pulling from JetStream. Sensor → RunRequest → direct job execution. The GraphQL trigger bridge was eliminated in favor of Dagster’s native sensor mechanism.
Why Dagster (Python)
Dagster is an orchestrator (conductor), not a computation executor. Heavy processing runs entirely outside Python.
| Actual Computation | Execution Engine | Python/Dagster Role |
|---|---|---|
| LLM inference | vLLM / llama.cpp (C++/CUDA) | API call only |
| Vector search | PostgreSQL + pgvector (C) | SQL query only |
| Embedding + Reranking | multi-bert-inference (Rust/ONNX Runtime) | gRPC call only |
| Telemetry conversion | Vector (Rust) | YAML config only |
No Rust alternative to Dagster exists. The orchestrator’s performance requirements are I/O wait + state management — Rust’s strengths (CPU-bound, memory safety) do not apply here. Dagster’s value lies in its lineage tracking + sensor + asset materialization design philosophy.
LLM Backend Selection
Backend is automatically selected based on the requested model name.
| Backend | Default URL | Example Models |
|---|---|---|
| vLLM | http://$COMPUTE_HOST:8000 | qwen3-next:80b, qwen3-coder:30b |
| llama.cpp | http://$COMPUTE_HOST:8081 | nemotron-3-nano:30b |
| LM Studio | http://$COMPUTE_HOST:1234 | lfm2.5-1.2b-instruct-mlx |
LLM routing is handled by gateway goroutines. The control flow that determines the next backend based on response content requires stateful judgment — Vector cannot substitute this.
Models are continuously evaluated. Verified models are archived on the storage server’s cold storage in GGUF, NVFP4, ONNX and other formats, with performance and quality assessments tracking new model releases.

Rust to Go Migration
The initial prototype was designed in Rust (axum). The precise type system was valuable for design, but the writing cost for heavy async patterns was high.
- Managing async contexts for SSE relay + NATS subscription + PG/pgvector writes simultaneously was verbose in Rust
- goroutine + channel naturally fits this pattern
- Runtime overhead difference is negligible for this use case
All design principles were preserved after migration: OpenAI-compatible endpoints, NATS Pub/Sub event-driven architecture, trace_id on all logs, idempotent design. The Rust design documents served as specifications for the Go implementation.
Implementation
Endpoints
| Method | Path | Description |
|---|---|---|
| POST | /v1/chat/completions | Chat completions (OpenAI compatible) |
| POST | /v1/messages | Anthropic Messages API |
| POST | /v1/responses | Responses API |
| POST | /v1/embeddings | Embeddings |
| GET | /v1/models | Model listing |
| GET | /healthz | Health check |
Middleware Chain
Gin middleware: RequestContext → Logger → Recovery
- RequestContext — Extracts request tracking ID from
X-Correlation-IDorX-Request-IDheader. Auto-generates a timestamp-based ID when absent, setting it on both context and response header - Logger — Records method, path, status, duration per HTTP request via
slog - Recovery — Gin standard panic recovery
RAG Data Flow
Client
|
v
Chat Completion Request
|
v
Knowledge Service (RAG orchestration)
|-- 1. User query extraction
|-- 2. Embedding generation (multi-bert-inference -> 256d ColBERT)
|-- 3. Vector search (pgvector HNSW ANN) + reranking (ColBERT MaxSim)
|-- 4. Context injection
|-- 5. Send to LLM backend
|-- 6. NATS publish (pipeline.* + telemetry.*) <- fire-and-forget
+-- 7. Response to client
System Topology
NATS JetStream :4222
+----------------------+
| pipeline.* |
| telemetry.* |
+---+----------+--------+
publish ------+ | pull subscribe
(fire & forget) | (durable consumer)
|
+-- agent-gateway :8080 ------+ +-- Dagster daemon -----------------------+
| | | |
| Client Request | | sensor: nats_dagster_chat_persist |
| | | | sensor: nats_dagster_embedding |
| v | | sensor: nats_dagster_retrieve |
| Knowledge Service | | sensor: nats_dagster_compose |
| |-- embed (multi-bert) | | sensor: nats_dagster_flow_lineage |
| |-- vector search (pg) | | sensor: nats_dagster_tool_call |
| |-- rerank (ColBERT) | | | |
| |-- LLM inference -------|-->-| vLLM / llama.cpp / LM Studio |
| | | | | |
| |-- NATS pub: pipeline.* | | v |
| |-- NATS pub: telemetry.*| | RunRequest -> Dagster job execution |
| +-- Response | | |-- chat persist -> pg |
| | | |-- embedding event -> pg |
| LLM Backends | | |-- retrieve event -> pg |
| |-- vLLM :8000 | | |-- compose event -> pg |
| |-- llama.cpp :8081 | | |-- flow lineage -> pg |
| +-- LM Studio :1234 | | +-- tool call -> pg |
| | | |
+-----------------------------+ +-----------------------------------------+
|
+------------+
| pull subscribe
v
+-- Vector (Rust) ----------------------+
| source: nats (telemetry.*) |
| |-- sink: Prometheus exporter |
| +-- sink: Loki (CorrelationID) |
+--------------------------------------+
NATS Event Design
Two independent paths share the same CorrelationID.
Pipeline (Dagster sensor → job execution):
| Topic | Dagster Job |
|---|---|
pipeline.knowledge.chat.persist | knowledge_chat_persist + knowledge_chat_pair_materialize |
pipeline.knowledge.embedding | knowledge_embedding |
pipeline.knowledge.retrieve | knowledge_retrieve |
pipeline.knowledge.compose | knowledge_compose |
pipeline.knowledge.flow.lineage | knowledge_flow_lineage |
pipeline.knowledge.tool_call | knowledge_tool_call |
Telemetry (Vector → Prometheus / Loki):
| Topic | Content |
|---|---|
telemetry.knowledge.chat | Model, backend, token usage, streaming flag |
telemetry.knowledge.embedding | Model, input count, dimensions |
telemetry.knowledge.retrieve | TopK, hit count, scores |
telemetry.knowledge.tool_call | Function name, model |
JetStream stream configuration:
PIPELINE— subjects:pipeline.>, retention: limits, max-age: 72h, storage: fileTELEMETRY— subjects:telemetry.>, retention: limits, max-age: 24h, storage: file
Dagster Assets and Jobs
The Dagster side is structured with asset materialization + sensor patterns.
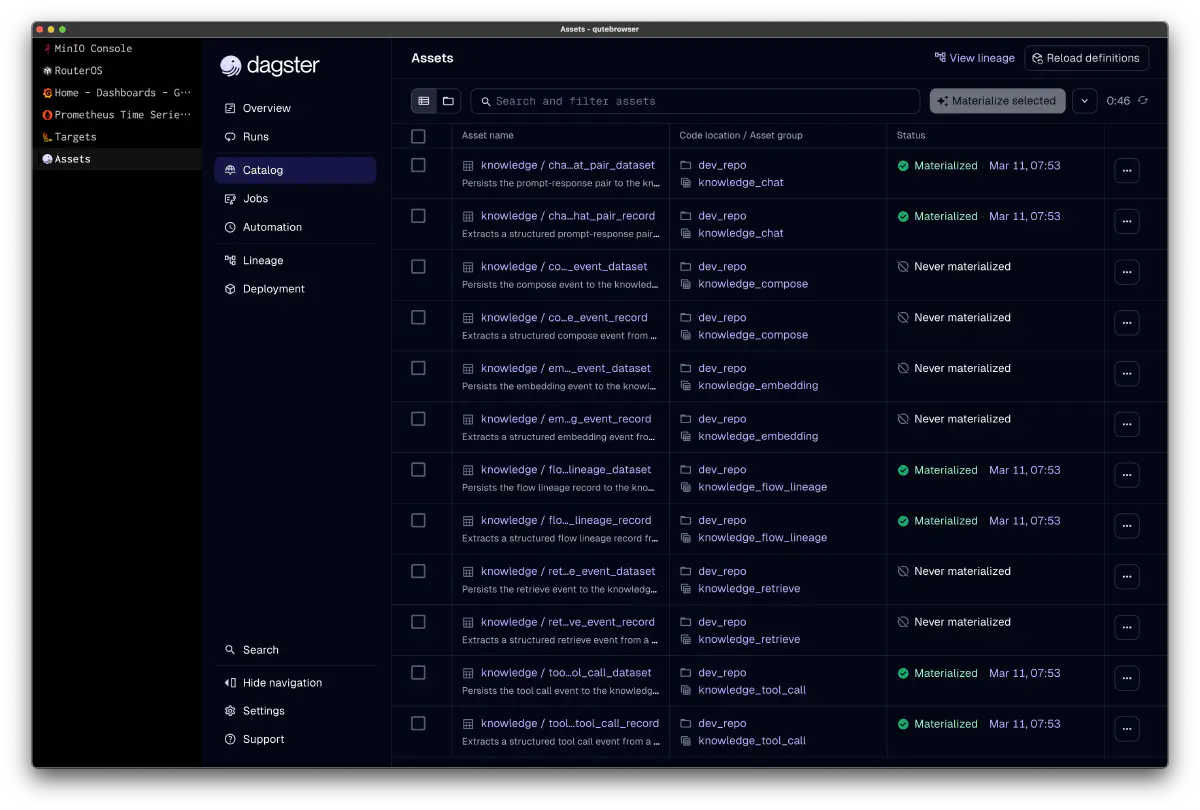
Each sensor pull-subscribes from NATS JetStream, detects events, and issues RunRequests for direct job execution. No GraphQL API involved.
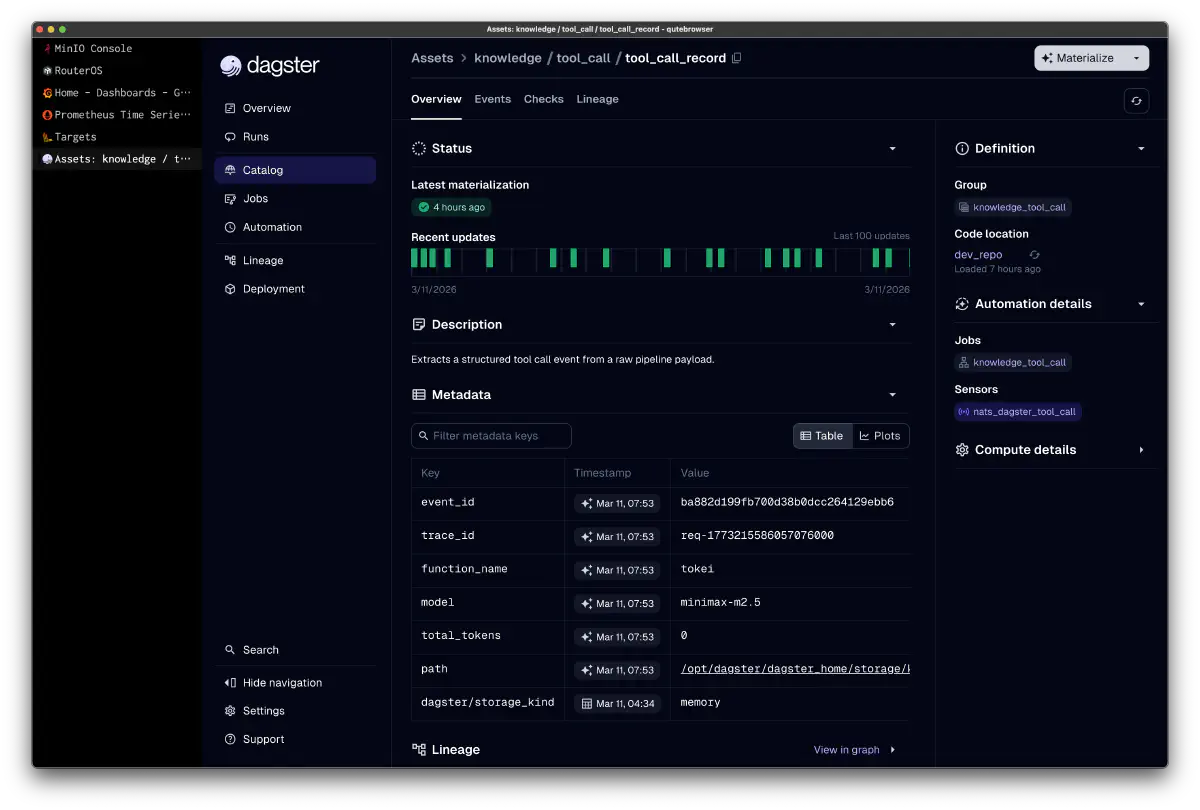
Example tool_call_record: function_name: tokei, model: minimax-m2.5 — records which tool was called by which model as an event, enabling lineage tracking in Dagster.
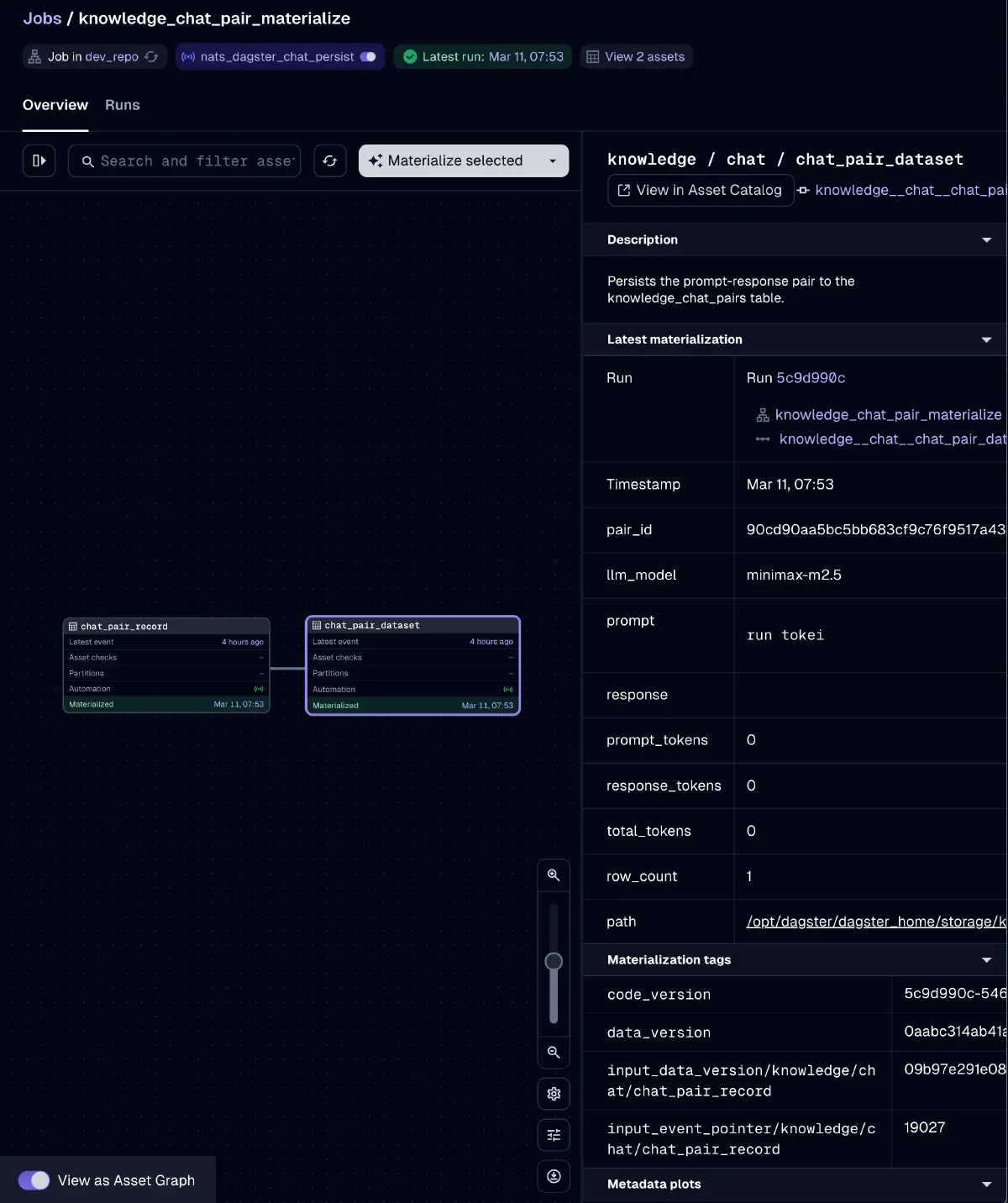
The knowledge_chat_pair_materialize job materializes two assets: chat_pair_record and chat_pair_dataset. It persists prompt-response pairs to PostgreSQL as raw material for future fine-tuning dataset construction.
devstack Container Layout
All middleware runs as rootless containers via podman-compose.
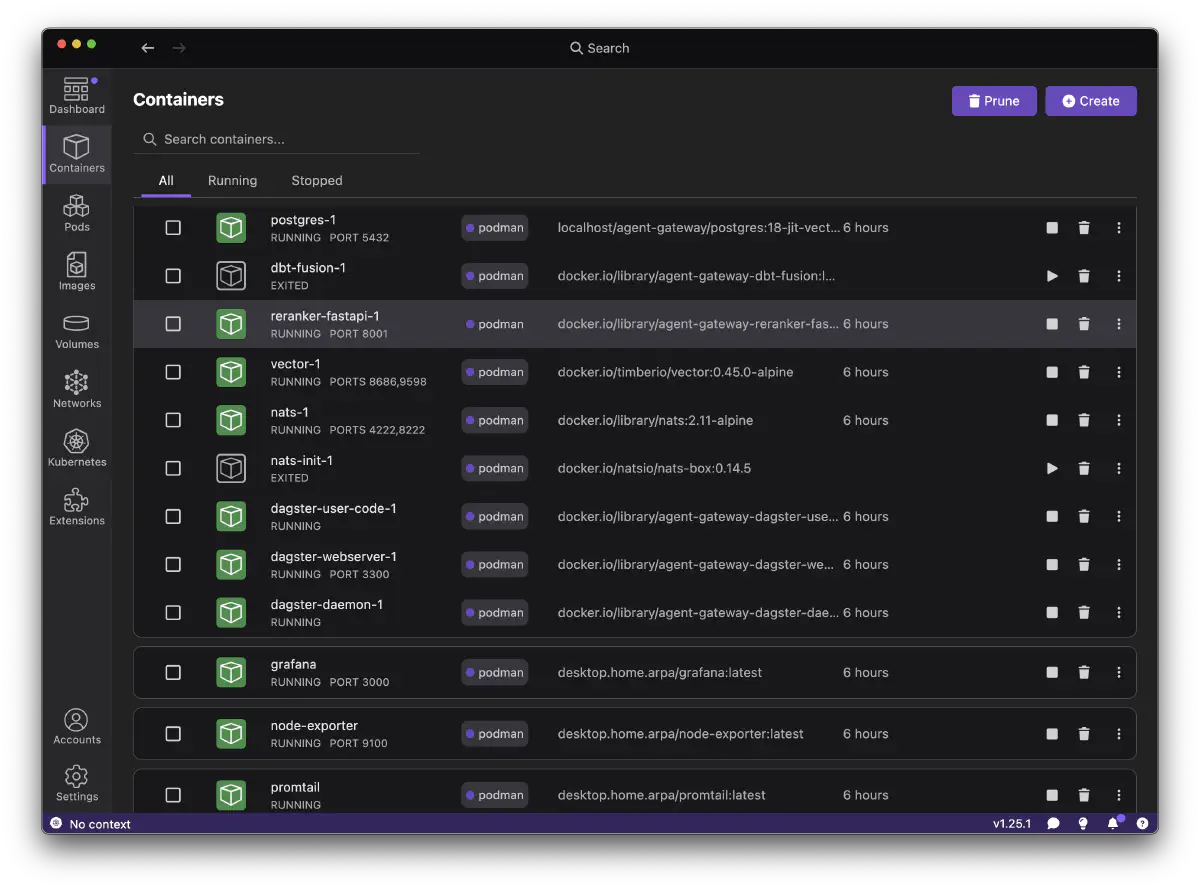
| Service | Image | Ports | Role |
|---|---|---|---|
| NATS | nats:2.11-alpine | 4222, 8222 | JetStream messaging |
| PostgreSQL | postgres:18-jit-vector | 5432 | pgvector + JIT, agent_gateway / dagster DB |
| Dagster | Custom build | 3000 | Webserver + Daemon + User-code gRPC |
| Vector | timberio/vector:0.45.0-alpine | 8686, 9598 | NATS telemetry → Prometheus/Loki |
| multi-bert-inference | Rust (Axum) + ONNX Runtime | 3001 (HTTP), gRPC | ColBERT embed (256d) + rerank (64d MaxSim) |
Lakehouse profile (for Phase 2, explicit startup):
- Nessie (19120) — Iceberg metadata catalog (git-like branching)
- Trino (8081) — SQL engine with Iceberg catalog
- dbt-fusion — dbt CLI container
3-Host Network Topology
NATS co-located with the gateway, keeping all paths within 1 hop.
+-- storage server (observability) --+ +-- desktop mac (gateway) ----------+ +-- compute server (inference) ------+
| | | | | |
| Prometheus <-- scrape --------------|-- :9598 (Vector exporter) | | vLLM :8000 (GPU inference) |
| Grafana | | | | llama.cpp :8081 |
| Loki <-- push ----------------------- Vector (nats source) | | |
| Vector (aggregator) | | | | | Dagster :3000 |
| |-- nats source -------------------- NATS JetStream :4222 <---------|--|---- daemon sensor (pull subscribe) |
| |-- -> Loki sink | | ^ publish | | |-- webserver |
| +-- -> Prometheus exporter | | | (fire-and-forget) | | |-- daemon (sensor -> job) |
| MinIO :9000 | | | | | +-- user-code gRPC |
| | | agent-gateway :8080 | | |
| | | |-- proxy API | | PostgreSQL 18 :5432 |
| | | | (OpenAI/Anthropic/ | | +-- pgvector (ANN + full-text) |
| | | | Responses) | | |
| | | |-- knowledge orchestrator | | multi-bert-inference :3001 |
| | | +-- NATS pub ----------------|---> pipeline.* + telemetry.* |
| | | | | |
| | | LM Studio :1234 (CPU inference) | | Trino :8080 |
| | | | | Nessie :19120 |
+------------------------------------+ +-----------------------------------+ +-------------------------------------+
| Host | Role | Key Services | Uptime |
|---|---|---|---|
| storage server | Observability + object storage | Prometheus, Grafana, Loki, Vector, MinIO | 24/7 |
| desktop mac | Gateway + messaging | agent-gateway, NATS JetStream, LM Studio | Working hours |
| compute server | GPU inference + data platform | vLLM, llama.cpp, Dagster, PostgreSQL, Trino | Working hours |
NATS placed on desktop mac because the gateway (largest publisher) co-locates for zero pub latency. Desktop/compute start and stop together, so NATS availability is not a concern. Only the storage server runs 24/7; Vector detects disconnection and auto-reconnects to NATS on restart.
Data Storage Strategy
Storage is split by data characteristics between PostgreSQL (pgvector) and Iceberg (Parquet).
PostgreSQL (pgvector) Iceberg (Parquet via Trino/Nessie)
-------------------- -----------------------------------
Characteristics Structured + vector search File-oriented + bulk accumulation
Queries WHERE + ANN (nearest neighbor) SQL JOIN + time-travel
Update pattern UPSERT (row-level) append-only (immutable Parquet)
Versioning None (self-managed history) Nessie branches + Iceberg snapshots
In Phase 1 (real-time), all data is written directly to PostgreSQL. From Phase 2 onward, Dagster batch processes will convert PG data to Parquet → Iceberg append, with dbt-fusion building analytical datasets.
PostgreSQL Schema
- document_chunks — 256-dimension ColBERT embeddings + HNSW vector index
- chat_history — Conversation history by correlation_id
- rerank_scores — Reranking scores per query x document x model
- api_responses — Responses API persistence
Caveats
- When desktop mac / compute server are stopped, NATS goes down too, but JetStream persistent data is retained on desktop mac disk and resumes from unconsumed messages on next startup
- Vector detects disconnection and auto-reconnects, but telemetry events during NATS downtime are lost (pipeline side is protected by JetStream durable consumers)
- PostgreSQL 18 JIT requires
shm_size: 4gbconfiguration. Insufficient allocation risks OOM kills
Verification
- Confirmed asset materialization status in Dagster UI: chat_pair, flow_lineage, tool_call successfully Materialized
- Monitored stream state and consumer lag via NATS monitoring (
:8222) - Verified telemetry metrics delivery through Vector exporter (
:9598) → Prometheus - Integration tests:
go test -tags=integration ./internal/infra/integration ./internal/domain/pipeline
Next Actions
Phase 1 (real-time platform) is currently operational. Roadmap:
| Phase | Content | Status |
|---|---|---|
| 1 | gateway → NATS → Dagster/pg, Vector → Prometheus/Loki | Running |
| 2 | pg → Parquet → Iceberg batch, dbt-fusion processing | devstack ready |
| 3 | MCP server tool definitions, Trino query tool, hypothesis testing automation | Not started |
| 4 | Fine-tuning pipeline, MOE expert pruning, synthetic data augmentation | Not started |