Homelab Infrastructure Redesign -- PostgreSQL Storage/Compute Separation and Devstack Overhaul
Migrating PostgreSQL from an on-demand GPU box to a 24/7 Mac Mini in a 3-node homelab. Covers the pgvector integration decision, devstack macOS compatibility, and backup symlink design.

About This Article
My homelab runs on three nodes: storage.home.arpa (Mac Mini 2018, 24/7), desktop.home.arpa (main dev machine), and compute.home.arpa (GPU box, on-demand). This is about confronting the question of where PostgreSQL should live in that setup, plus devstack housekeeping done along the way.
Why PostgreSQL Was on compute
The original layout looked like this:
storage.home.arpa (Mac Mini 2018, Ubuntu, 24/7)
-- MinIO, Prometheus, Loki, Vector
desktop.home.arpa
-- familiar (agent-gateway), NATS
compute.home.arpa (GPU box, on-demand)
-- PostgreSQL, Dagster, MLflow, vLLM, llama.cpp
PostgreSQL ended up on compute because Dagster and MLflow could access it directly on the same host. Inside Docker Compose, the service name postgres just worked as a hostname. I didn’t think too hard about it during the initial build.
The problem: compute starts on demand. PostgreSQL – managing metadata that needs to persist – was sitting on a machine that only runs when needed. Every time compute got rebuilt, I had to worry about the data. On top of that, having to spin up the GPU box just to check something in the database was quietly annoying. When I wanted to run dbt from my desktop to manipulate data, compute had to be up first.
The Decision: Consolidate on storage
I evaluated moving PostgreSQL to storage.home.arpa. The concern was whether a Mac Mini 2018 (i7-8700B, 16GB RAM) could handle the load.
First, I mapped out the data characteristics. PostgreSQL was hosting three databases:
agent_gateway: main app DB (document_chunks, chat_history, session, lineage)dagster: Dagster execution metadatamlflow: MLflow experiment tracking
All metadata + text + vectors. The actual files (Parquet, artifacts) were already going to MinIO. With metadata-only workloads, I/O would be light. pg_dump fits in a few MB.
The overall data architecture:
| Location | Role | Data Examples |
|---|---|---|
| PostgreSQL (storage) | Metadata + aggregation + pgvector | session, lineage, embeddings, dbt materialized |
| MinIO (storage) | Actual files | Parquet, Iceberg data, MLflow artifacts |
| DuckDB (compute) | Transform/aggregation workbench | Dagster pipeline intermediate data |
DuckDB is a volatile workbench. If it disappears, Dagster jobs can regenerate it. The source of truth lives in PostgreSQL and MinIO.
With a flat data design, load doesn’t easily become a bottleneck. Having PostgreSQL up 24/7 turned out to be surprisingly comfortable – being able to run dbt from my desktop machine at any time was a bigger quality-of-life improvement than I expected.
The pgvector Separation Question
During the migration planning, I also considered splitting pgvector out of PostgreSQL and running Qdrant on compute.
Qdrant would let me run HNSW searches on the GPU box’s resources. It’s dedicated to HNSW and faster than pgvector at high RPS, and compute’s CPU/memory could be fully committed. But there were problems:
- Dual management of
document_chunks(text + metadata in PG, vectors in Qdrant) - Go app repository code would need rewriting for the Qdrant client
- compute is on-demand, so if it’s down when you need embedding search, you’re stuck
The last point was decisive. When using external APIs (Gemini, etc.), I need embedding search without compute being up.
Reconfirming the benefits of keeping pgvector integrated:
- embedding + metadata + chat_history can be JOINed in the same DB
- Cross-cutting queries via
correlation_idin a single query - No dual management
- Single backup target
I also reconsidered the RPS numbers. Embedding search is one HNSW query per user query. At human typing speed, 18 RPS is unrealistic. Even with aichat + Zed running simultaneously, realistic RPS is 2-5. The 18 RPS figure was about NATS-sourced Dagster events, which are lightweight metadata INSERTs.
Conclusion: keep pgvector integrated in PostgreSQL, migrate to storage. If problems arise: tune ef_search -> adjust shared_buffers -> last resort: Qdrant@compute. A staged fallback.
Implementation: Rewriting Go Config and Compose
The Go side required minimal changes. config.go was deriving DSNs from COMPUTE_HOST, so I just added POSTGRES_HOST to decouple it:
// internal/config/defaults.go
const DefaultPostgresHost = DefaultStorageHost // storage.home.arpa
// internal/config/config.go
postgresHost := envOr("POSTGRES_HOST", DefaultPostgresHost)
User mapping was also updated:
| Purpose | User | DB |
|---|---|---|
| Application | agent | agent_gateway |
| Infra metadata | system | dagster, mlflow |
| Admin | ksh3 | All DBs |
compute-compose.yaml was substantially restructured:
# Removed: postgres service block and postgres-data volume
# MLflow: point backend-store-uri to storage
mlflow:
environment:
BACKEND_STORE_URI: postgresql://system@storage.home.arpa:5432/mlflow
# Dagster: inject PG host via environment variables
dagster-webserver:
environment:
DAGSTER_PG_HOST: storage.home.arpa
DAGSTER_PG_USER: system
POSTGRES_DSN: postgresql://agent@storage.home.arpa:5432/agent_gateway
# Added restart: on-failure to all services (PG connection retry)
Removed all depends_on: postgres, replaced with restart: on-failure to cover PG startup timing. Both Dagster and MLflow have built-in connection retry, so they connect automatically once PostgreSQL on storage is up.
PostgreSQL on storage runs as a systemd quadlet. The image is a custom build on postgres:18-trixie with JIT + pgvector enabled. Tuned for the Mac Mini:
shared_buffers = 2GB # 16GB RAM shared with other services
effective_cache_size = 6GB
work_mem = 64MB
shm_size = 2GB # reduced from compute's 4GB
Init scripts were converted from .sql to .sh, handling user creation, DB creation, pgvector extensions, and permissions in one shot.
go build ./... # clean
Devstack macOS Compatibility
In parallel with the PostgreSQL migration, I fixed homelab/desktop-containers/compose.yaml to work on macOS.
Several Linux-only settings had crept in:
| Issue | Fix |
|---|---|
node-exporter privileged: true + pid: host | Removed (useless in macOS VM) |
/:/host:ro,rslave mount | Removed rslave (macOS Docker Desktop incompatible) |
version: "3.9" | Removed (deprecated) |
/private/var/log path | macOS /var/log is a symlink |
Grafana and Prometheus work on macOS as-is. node-exporter has limited functionality on macOS, but compute and storage metrics come through fine, so no practical impact.
Backup and Symlink Design
Checked the symlink duplication risk in compute-containers/runtime/backup/backup-runner.sh.
BACKUP_ROOT=/srv/persistent/backup
WORKSPACE_ROOT="${WORKSPACE_ROOT:-/mnt/data/workspace}"
Would creating a /opt -> /mnt/data/workspace symlink cause double backups? No. backup-runner.sh specifies WORKSPACE_ROOT directly and doesn’t traverse /opt. tar doesn’t follow symlinks by default (it archives the symlink itself). Caveat: using --follow-symlinks or having another backup process targeting /opt would be a different story.
ctree Checkpoints and argus
Around the same time, I added a create_checkpoint tool to the argus project’s ctree. get_revs works as a diff viewer, but I wanted a simpler accessor that just generates checkpoint files at high frequency at work boundaries.
Found a ctree bug during this work: get_affected and get_depends fail to detect symbol references in some cases:
ctree.get_affected(name="reject_removed_paging_args") -> no references (actually called from dispatch)
ctree.get_depends(dep="reject_removed_paging_args") -> "no dependencies found"
Fixed in a separate session.
familiar’s latest architecture adds an Application Layer for agent-mode orchestration (tool execution, workspace management, MCP server management):
Transport Layer (Gin)
|
+--- (agent mode) ---> Application Layer [internal/agent/]
| +- loop.go orchestration loop
| +- orchestrator_runtime.go
| +- intent_packet.go
| +- tools.go MCP tool definitions
| +- executor/ file, git, shell
| +- mcp/ MCP server management
| +- workspace/ session management
v |
Domain Layer <-----------------------+
Normal API requests flow Transport -> Domain -> Infra, but in agent mode, Transport runs the orchestration loop through the Application Layer.
The Final Layout
The three-node setup after migration:
storage.home.arpa (Mac Mini 2018, Ubuntu, 24/7)
-- PostgreSQL :5432 (pgvector, 3 DBs)
-- MinIO :9000
-- Prometheus :9090
-- Loki :3100
-- Vector
desktop.home.arpa
-- familiar :8080
-- NATS :4222
-- multi-bert-inference :50051
-- Grafana :3000
compute.home.arpa (GPU box, on-demand)
-- Dagster :3300
-- MLflow :5050
-- vLLM :8000
-- llama.cpp :8081
-- DuckDB (in-pipeline workbench)
The source of truth for persistent data is now consolidated on storage. compute is purely a compute resource – it can be shut down or rebuilt without data loss.
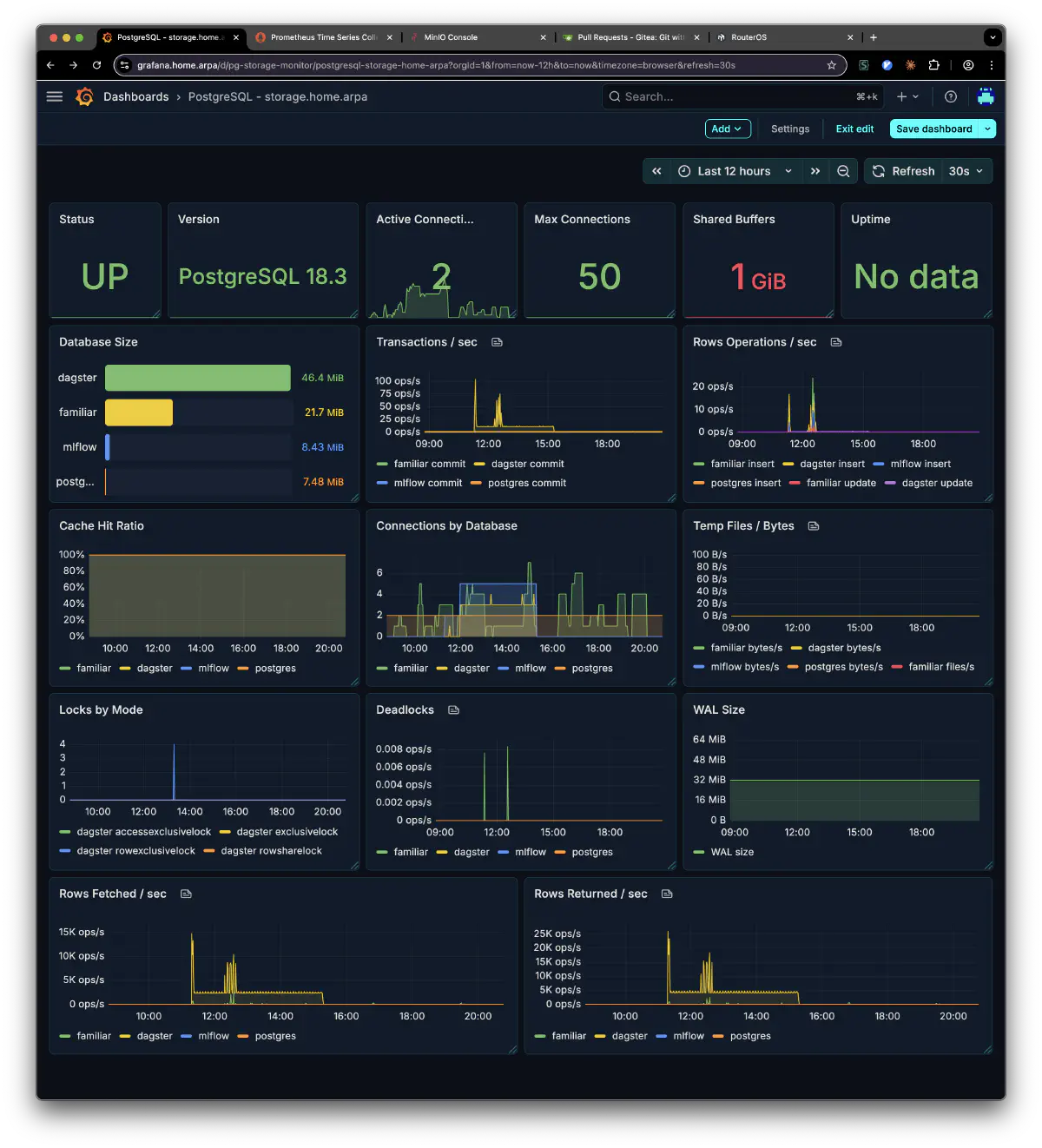
Here’s PostgreSQL after the migration. The familiar, dagster, mlflow, and postgres databases are all running on storage:
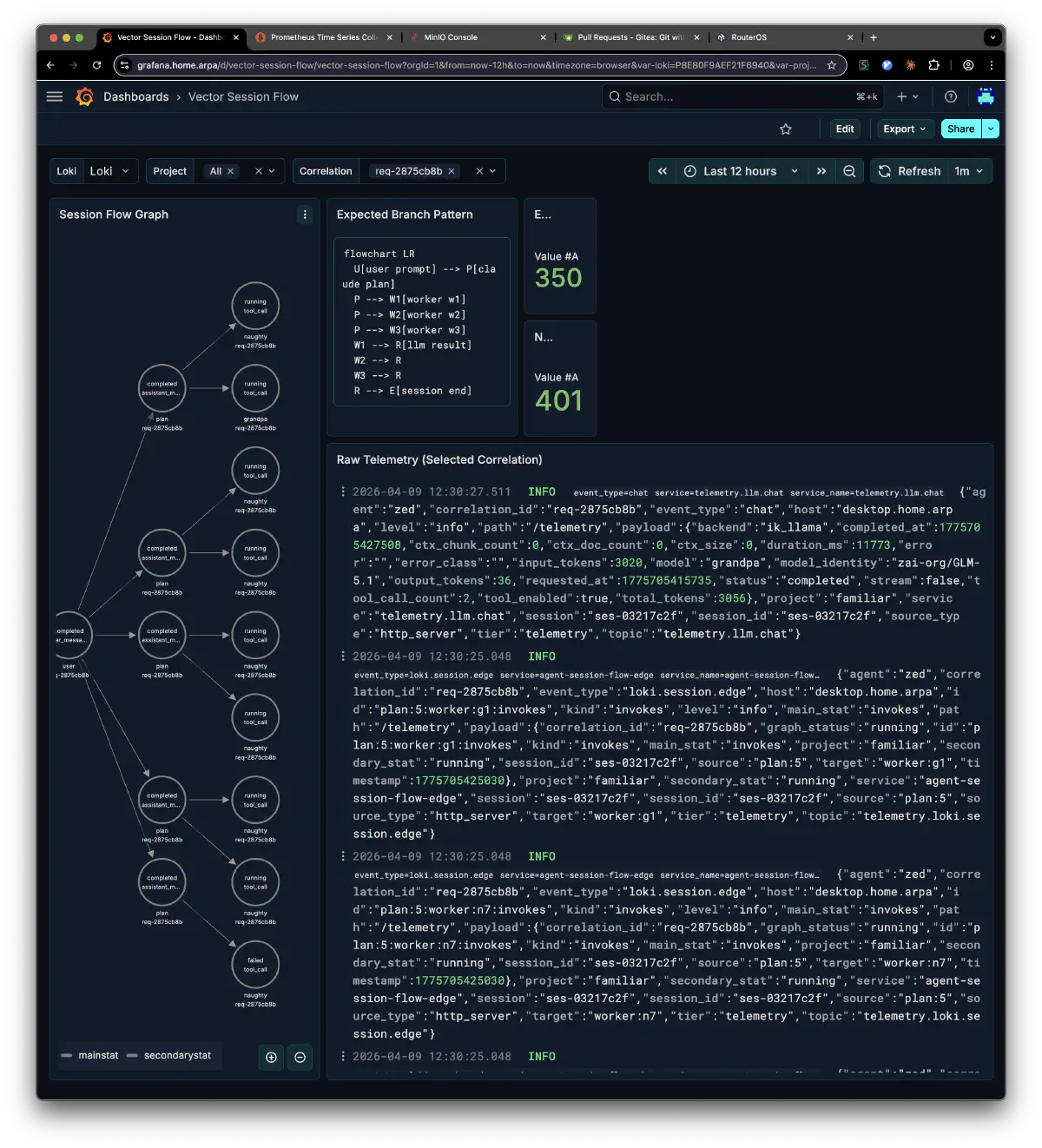
familiar’s session flow is now visible as telemetry too. You can trace a chain of requests by correlation_id:
Consolidating on storage also made the restic backup story clean. It serves as the backup collection point for all nodes, everything in one place. There are quite a few services running, but since the tooling is almost entirely Rust and Go, CPU and memory usage haven’t been an issue at all.
This storage server is a Mac Mini Late 2018 (2TB model) I picked up at Janpara for around 40,000 yen. When I checked SMART at purchase, the Power-On Hours were practically zero – a completely unused find. I replaced the OS with ubuntu-minimal, and it’s been running 24/7 under heavy use ever since.