Running DeepSeek-V4-Flash with a llama.cpp WIP Branch: First Local Inference on Dual Blackwell Max-Q 96GB GPUs
A first-pass validation of DeepSeek-V4-Flash (284B MoE / 13B active) on dual RTX PRO 6000 Blackwell Max-Q 96GB GPUs using a llama.cpp WIP DeepSeek-V4 branch and native FP4/FP8 GGUF, covering official inference-code attempts, GGUF conversion attempts, PP/TG measurements, and the current Flash Attention limitation.

I ran DeepSeek-V4-Flash locally on dual RTX PRO 6000 Blackwell Max-Q 96GB GPUs. The result is intentionally narrow: this is a first-pass “it runs” validation using a llama.cpp WIP branch and a community GGUF.
Even with that limitation, a 284B MoE / 13B active model is already reaching around 35 t/s TG locally while staying in native FP4/FP8 GGUF. Flash Attention is still disabled, and the DSV4 graph implementation is still in progress, so I am recording this as an experimental snapshot from 2026-04-27 rather than a final performance evaluation.
Video link: https://www.youtube.com/watch?v=Hjl4efNonxE
Result First
The working setup used nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF and the wip/deepseek-v4-support branch from llama.cpp PR #22378. The Hugging Face model card reports DeepSeek-V4-Flash as 284B params, and the GGUF is published as a deepseek4 architecture model.
| Item | Value |
|---|---|
| Model | DeepSeek-V4-Flash |
| Parameters | 284B MoE |
| Active parameters | 13B |
| Experts | 256 experts / 6 active |
| GGUF | nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF |
| Runtime | llama.cpp wip/deepseek-v4-support |
| Commit range | b8942-ba173dd08 |
| Quantization | native FP4 + FP8 |
| GGUF size | 146GB |
| BPW | 4.39 |
| GPUs | RTX PRO 6000 Blackwell Max-Q 96GB x2 |
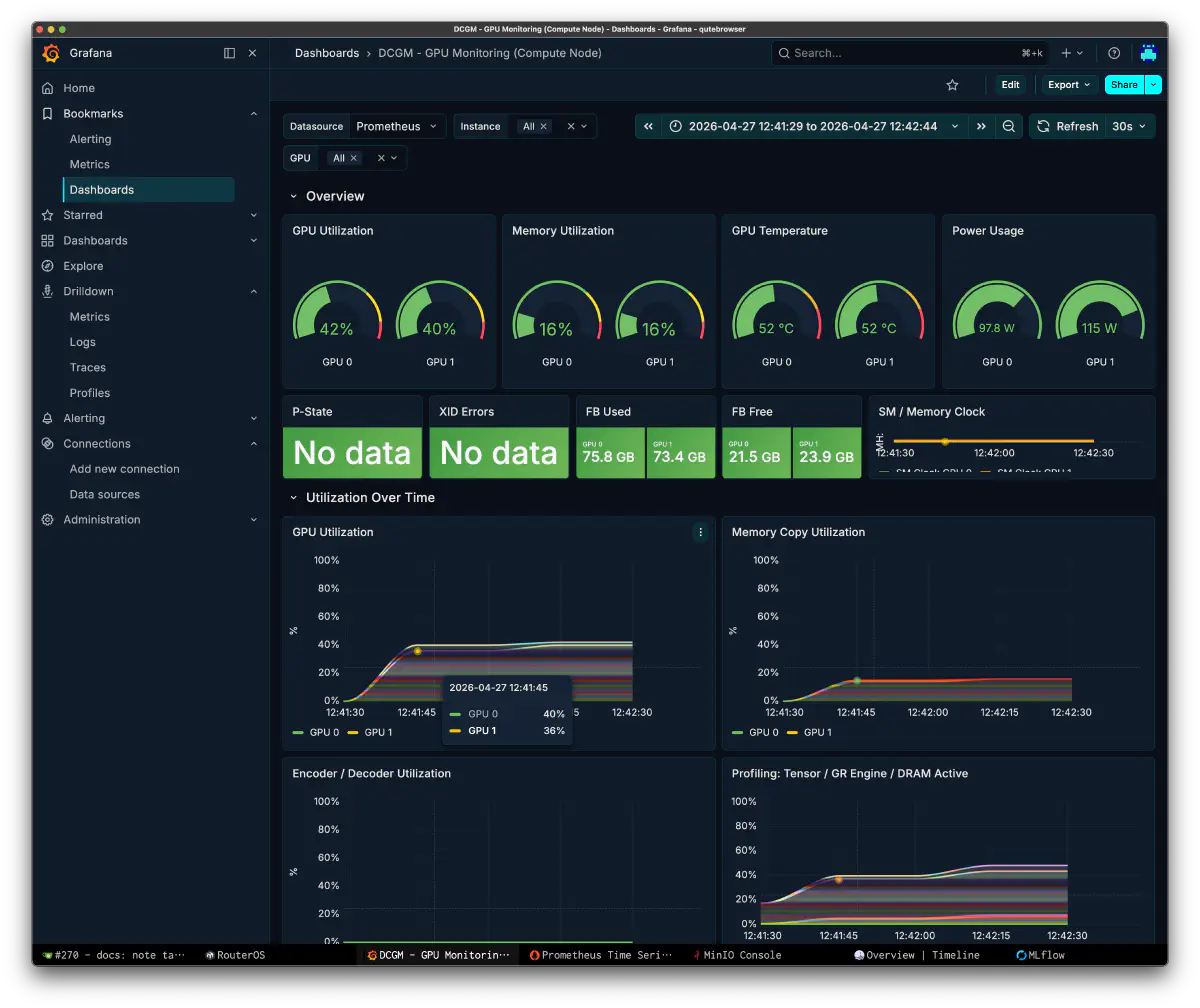
The benchmark summary:
| Metric | Value |
|---|---|
| Prompt eval (PP) | 36.5-39.4 t/s |
| Token generation (TG) | 34.1-41.7 t/s |
| PP average | 38.3 t/s |
| TG average | 35.7 t/s |
| VRAM | GPU0: 75.1GB, GPU1: 72.8GB |
| Offloaded layers | 44/44 |
| CPU mapped | 1010 MiB |
| Flash Attention | disabled |
| GPU utilization | 30-40% burst |
| Peak power | GPU0: 97.8W, GPU1: 115W |
| Graph splits | 3 |
GPU utilization stayed around 30-40% in bursts, and power draw stayed around 100-115W against a 300W TDP. Once Flash Attention and the expert dispatch graph improve, there should still be plenty of headroom.
Launch Command
This is the final command I used:
podman run --rm \
-p 8000:8000 \
--device nvidia.com/gpu=all \
--shm-size 8g \
-v /mnt/data/models/models--nsparks--DeepSeek-V4-Flash-FP4-FP8-GGUF:/models:Z \
llama.cpp:deepseek-v4 \
-s -m /models/snapshots/.../DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--n-gpu-layers 999 --threads 15 --threads-batch 24 \
--ctx-size 8192 --parallel 1 -b 4096 -ub 2048 \
--jinja --host 0.0.0.0 --port 8000 --alias deepseek-v4
llama-server already exposes an OpenAI-compatible endpoint, so I did not need to keep the API wrapper I had built for the official inference/ path.
Test Environment
| Item | Value |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x2 |
| Compute Capability | sm_120 |
| Driver | 580.126.09 |
| CUDA | 13.0 |
| CPU | AMD EPYC 9175F |
| RAM | 768GB DDR5-6400 |
| Container | Podman |
| Native FP4 | BLACKWELL_NATIVE_FP4 enabled |
When I loaded the model directly through transformers, both GPU0 and GPU1 used roughly 80GB of VRAM. I confirmed the first response, but the process crashed when I sent a prompt request. I then investigated the official inference-code path, but eventually switched to the GGUF that had appeared on Hugging Face.
Per-Request Benchmark
The prompts are short, so this is not a full PP benchmark. It is enough to understand the speed profile at this experimental stage.
| # | Request | prompt tokens | PP (ms/t) | PP (t/s) | gen tokens | TG (ms/t) | TG (t/s) | total (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | Japanese question | 14 | 26.7 | 37.4 | 41 | 27.1 | 36.9 | 1.5 |
| 2 | MoE explanation | 20 | 25.9 | 38.6 | 132 | 27.8 | 36.0 | 4.2 |
| 3 | FP4 vs FP8 | 19 | 25.9 | 38.7 | 125 | 27.7 | 36.1 | 4.0 |
| 4 | system prompt | 31 | 25.8 | 38.7 | 182 | 27.8 | 36.0 | 5.9 |
| 5 | multi-turn | 50 | 25.9 | 38.6 | 512 | 28.0 | 35.7 | 15.6 |
| 6 | Go code | 23 | 25.8 | 38.7 | 230 | 27.8 | 35.9 | 7.0 |
| 7 | logic puzzle | 23 | 25.9 | 38.7 | 207 | 27.8 | 35.9 | 6.4 |
| 8 | comparison analysis | 30 | 25.8 | 38.7 | 427 | 28.0 | 35.8 | 12.7 |
| 9 | JSON output | 26 | 27.4 | 36.5 | 122 | 29.3 | 34.1 | 4.3 |
| 10 | DSV4 architecture | 45 | 25.8 | 38.7 | 414 | 27.9 | 35.8 | 12.7 |
Quality looked fine on short tests such as MoE explanation, code generation, and logic questions, but I also saw odd Japanese streaming artifacts such as 東東京圜 a few times. Since this is still a test branch, I would not read much into quality yet. The useful signal here is mostly the TG estimate.
Flash Attention Is Disabled
The logs show Flash Attention being disabled automatically:
sched_reserve: layer 0 is assigned to device CUDA0 but the Flash Attention tensor is assigned to device CPU (usually due to missing support)
sched_reserve: Flash Attention was auto, set to disabled
DeepSeek-V4 uses a custom attention architecture that includes CSA, HCA, and an Indexer. In this WIP branch, Flash Attention support for that graph still appears incomplete. That is probably the main reason GPU utilization stays around 30-40%.
PP should improve significantly once Flash Attention lands. TG is different: with a 4.39 BPW native FP4/FP8 GGUF split across two GPUs, each token is more constrained by memory bandwidth and expert dispatch than by Flash Attention itself. Around 35 t/s is already good for an experimental bring-up.
What I Tried with the Official Inference Code
Before using GGUF, I first tried to run the official repository’s inference/*.py path directly. The official code is built around local generation through generate.py; it does not ship with an HTTP endpoint. I therefore wrote a thin FastAPI + uvicorn wrapper around the tokenizer, model, and distributed runtime used by generate.py, exposing it as an OpenAI-compatible /v1/chat/completions endpoint.
The MP=2 weight conversion succeeded. With direct transformers loading, both GPUs used around 80GB. Through the official inference/*.py path, I also got as far as confirming the first response. At startup, nvtop showed Python processes using about 79680MiB on both GPU0 and GPU1, roughly 81% VRAM usage.
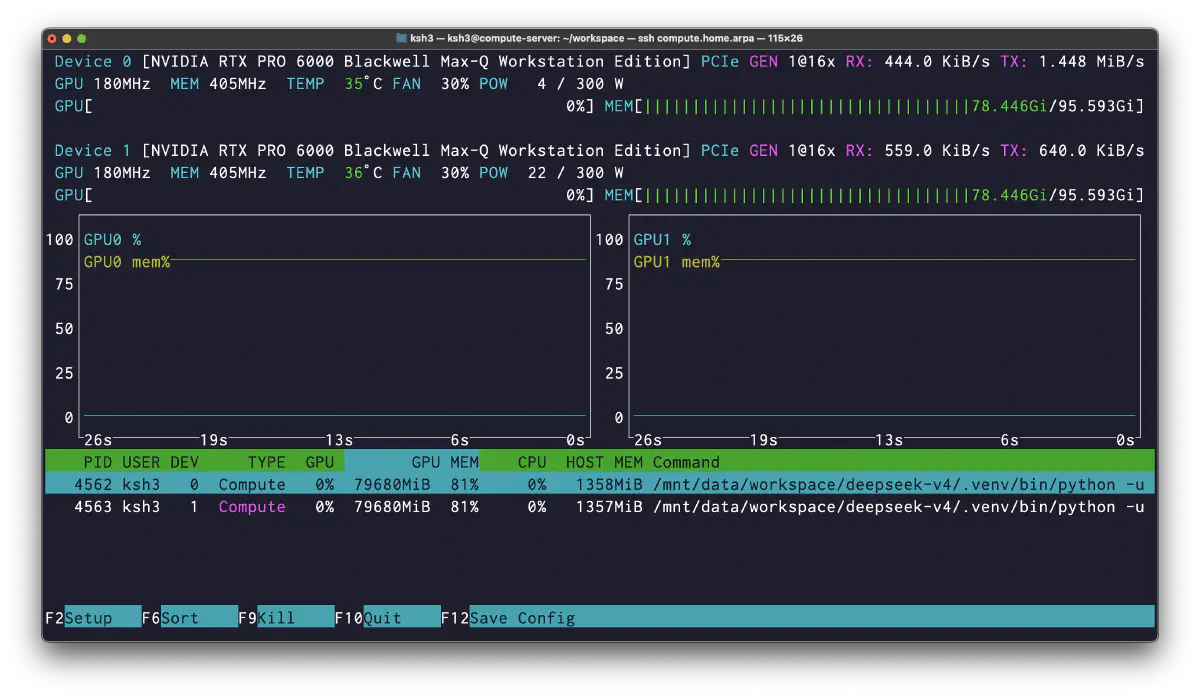
However, the process crashed when I sent a prompt request. I worked through the issues below, but the remaining blocker was the combination of the NGC container’s torch version and the FP4 dtype requirement in DSV4.
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} \
--n-experts 256 --model-parallel 2
NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 PYTHONPATH=. \
torchrun --standalone --nproc-per-node 2 main.py \
--ckpt-path ${SAVE_PATH} --config ${CONFIG} --port 8000
The main issues were:
| Issue | Status |
|---|---|
| NCCL segfault | Segfault around ncclNetPluginInit during broadcast. Avoided with NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 |
| tilelang could not detect CUDA | The bare-metal environment did not have the CUDA toolkit; worked around by symlinking nvcc from a container overlay |
| sparse attention shared memory | tilelang’s CSA sparse attention kernel required 104KB of dynamic shared memory |
| block size adjustment | Lowering sparse attention block size from 64 -> 32 got past the shared-memory side |
| NGC torch too old | nvcr.io/nvidia/pytorch:25.04-py3 pins torch 2.7.0 |
| DSV4 FP4 dtype | DeepSeek-V4-Flash needs torch.float4_e2m1fn_x2, which requires torch 2.11+ |
Blackwell supports up to 228KB/SM of dynamic shared memory. The 104KB required by tilelang’s sparse attention kernel should be reachable on the hardware, and reducing block size from 64 -> 32 did get past that part.
The remaining blocker was torch. The NGC container was pinned to torch 2.7.0, which does not provide the float4_e2m1fn_x2 dtype used by DeepSeek-V4-Flash. The constraints were strong enough that a simple replacement was not viable. I stopped pursuing the official inference/*.py route there and continued with the native FP4/FP8 GGUF that had appeared on Hugging Face.
What I Tried for Self-Conversion to GGUF
Next I tried converting the model myself using convert_hf_to_gguf.py from the nsparks WIP branch.
python3 convert_hf_to_gguf.py ${HF_SNAP} \
--outtype native \
--torch-threads 16 \
--outfile dsv4-flash-native.gguf
This also hit several stages:
| Stage | Result |
|---|---|
| torch 2.6 | F8_E8M0 KeyError |
| torch 2.11 CPU | F8_E8M0 passed |
| transformers | deepseek_v4 model_type was not recognized |
| tokenizer | Partly worked around by switching to PreTrainedTokenizerFast |
| pre-tokenizer | Stopped at unsupported joyai-llm pre-tokenizer |
At that point, the community GGUF had already been published, so I prioritized runtime validation over continuing the conversion work.
Final GGUF Used
The model I used was nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF. The model card lists deepseek-ai/DeepSeek-V4-Flash as the upstream source, and shows a conversion command in this shape:
python3 convert_hf_to_gguf.py /mnt/models/hf/DeepSeek-V4-Flash \
--outtype moe-f8-e4m3-mxfp4 \
--torch-threads 96 \
--outfile DeepSeek-V4-Flash-FP4-FP8-native.gguf
The official DeepSeek Hugging Face repository is MIT licensed.
Upstream Work I Am Tracking
As of 2026-04-27, DeepSeek-V4 support in upstream llama.cpp is still WIP.
| PR / Discussion | Purpose |
|---|---|
| llama.cpp PR #22378 | wip/deepseek-v4-support, including runtime graph, FP4/FP8 support, and performance hot paths |
| llama.cpp PR #22359 | DeepSeek-V4 GGUF conversion script |
| Discussion #22376 | DeepSeek-V4 support discussion |
| nsparks GGUF | native FP4/FP8 GGUF |
| official HF | official DeepSeek-V4-Flash weights |
Looking at the PR #22378 history, a lot has landed quickly: FP4/FP8 support, DeepSeek4 runtime state save, F8 decode tuning, TOP_K fast path, RMSNorm/copy kernel tuning, and more. TG may move closer to the numbers seen when using -ot exps=CPU.
Takeaways
The first important point is that I was lucky: the model size happens to fit my workstation well. A 284B MoE responding locally at around 35 t/s TG is already significant. The result is experimental and may change completely once the runtime is optimized. Flash Attention is disabled, graph splits are 3, GPU utilization is only 30-40%, and PP in particular should have a lot of room to improve.
TG is already in a practical range. The license is also clear, so for SFT/DPO distillation data, pipeline work, and batch jobs, 35 t/s is enough to be useful. I had been evaluating GLM-5.1, Kimi-K2.6, and Qwen3.5-397B as orchestrator candidates for my own agent system, and if DeepSeek-V4-Flash gets optimized in ik_llama.cpp or llama.cpp, it could become the best orchestrator in a CPU/GPU hybrid setup. Even as a fully GPU-loaded standalone model, the reported KV reduction of around 90% makes me interested in higher-context single-model use as well.
DeepSeek says DSV4 attention reduces KV cache by 93% and FLOPs by 90% compared with V3.2. In the current setup, total VRAM is 192GB. The model occupies 75.1GB on GPU0 and 72.8GB on GPU1, for 147.9GB total. That leaves 21.5GB on GPU0 and 23.9GB on GPU1, or 45.4GB free in total. If KV cache really uses only 7% of the usual footprint, that 32-45GB of free VRAM can hold a very large context. Right now I am working hard to coordinate multiple role-based models and optimize context management around them, but DSV4 feels like the kind of model meant to collapse that into a single model. If that works, some of the orchestration layer may no longer be necessary.