DwarfStar 4 × RTX PRO 6000 Blackwell: DeepSeek V4 Flash Q2 Reaches 43 tok/s
A first look at antirez’s DwarfStar 4 inference engine on an NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB GPU. DeepSeek V4 Flash 284B Q2-imatrix fits on a single GPU and delivers 43 tok/s generation, disk KV cache behavior, directional steering, and coding-agent operation.

I ran DeepSeek V4 Flash with antirez’s DwarfStar 4 (ds4.c) on an RTX PRO 6000 Blackwell Max-Q Workstation Edition 96GB. The short version: the Q2-imatrix quantized DeepSeek V4 Flash 284B model fits on a single GPU, reaches 43 tok/s on short generations, and still holds the 31 tok/s range at 50K context.
The implementation is still alpha-stage, but its behavior looked close to current Codex and Claude Code in the way it can be used with head/tail-style role control. As an orchestration model for my own agent, it is a good fit for an RTX PRO 6000 Blackwell 96GB machine. In practice, the sweet spot looks like 32K-64K context, with 96K also visible depending on workload. It can start at 128K, but there is not much headroom, so for now I would treat 96K as the ceiling. That may change with future optimization.
Video link: https://www.youtube.com/watch?v=A4aGNHEdrxE
Result First
| Item | Value |
|---|---|
| Model | DeepSeek V4 Flash |
| Parameters | 284B MoE / 13B active |
| Runtime | DwarfStar 4 (ds4.c) |
| Build | cuda-generic |
| Quant | IQ2_XXS + Q2_K routed expert, Q8 attention/shared/output |
| GGUF | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition |
| GPU memory | 96GB GDDR7 ECC |
| Memory bandwidth | 1,792 GB/s |
| Model tensor cache | 80.76 GiB |
| Peak observed VRAM | 93,142 MiB / 95,593 MiB |
| Short generation | 43.6 tok/s |
| 50K context generation | 31.4 tok/s |
| 20K prefill | 262 tok/s |
Previously I ran DeepSeek V4 Flash on dual RTX PRO 6000 GPUs using a WIP DeepSeek-V4 branch of llama.cpp. This time I used the model-specific ds4.c runtime and loaded an 80GiB-class Q2-imatrix GGUF onto a single RTX PRO 6000 Blackwell Max-Q 96GB.
The important point is not simply that it ran. It ran fast enough to use in real coding-agent work. Even at 50K context, tool-call generation stayed above 31 tok/s, and multi-turn agent sessions completed stably.
DwarfStar 4 Design
DwarfStar 4 is not a generic GGUF runner. It is a native inference engine narrowed specifically to DeepSeek V4 Flash. The official README explains that model loading, prompt rendering, tool calling, RAM/on-disk KV state, and the server API are all implemented directly for DeepSeek V4 Flash.
I like this tradeoff a lot. General-purpose engines must keep chasing support for new models, while DwarfStar 4 can validate quality around one model, including logit validation, long-context verification, and agent integration. From the perspective of using a local LLM as a coding agent, it matters that the inference engine, quantization, server API, and tool-calling shape are tested together.
At the same time, the project is explicitly alpha quality right now. The CUDA backend also has room to improve. The numbers below should be read as a first look as of 2026-05-14, not as the ceiling of a finished implementation.
Test Environment
| Item | Specification |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition |
| GPU architecture | SM_120 (Blackwell) |
| VRAM | 96GB GDDR7 ECC |
| Memory bandwidth | 1,792 GB/s |
| CPU | AMD EPYC 9175F |
| RAM | 755 GiB |
| Storage | NVMe 3.5T (xfs) |
| OS | Ubuntu 24.04 |
| CUDA | 13.2.1 |
| Container | Podman rootless |
| Model | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix |
| Engine | DwarfStar 4 (cuda-generic build) |
The RTX PRO 6000 Blackwell Max-Q has 96GB of GDDR7 ECC and 1,792 GB/s of memory bandwidth. MoE decode for a model like DeepSeek V4 Flash is strongly affected by memory bandwidth, so this is a good platform for testing how far a single GPU can go.
Build And Startup
The CUDA build worked with this target.
make cuda-generic
For the grandpa runtime, I built a thin container image from the CUDA 13.2.1 devel image that simply clones ds4 and builds cuda-generic.
FROM docker.io/nvidia/cuda:13.2.1-cudnn-devel-ubuntu24.04
RUN apt-get update && apt-get install -y --no-install-recommends \
git make gcc g++ ca-certificates && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
RUN git clone --depth 1 https://github.com/antirez/ds4.git . && \
make cuda-generic -j$(nproc)
EXPOSE 8000
ENTRYPOINT ["./ds4-server"]
Build and push looked like this.
podman build -t registry.home.arpa/dwarfstar4:latest .
podman push registry.home.arpa/dwarfstar4:latest
On Blackwell SM_120, -arch=native selected the right architecture. The runtime environment is a Podman rootless container using NVIDIA CDI passthrough and host networking.
The startup log showed CUDA backend initialization, device loading of the 80GiB-class tensor cache, and model loading from NVMe.
ds4: CUDA backend initialized on NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (sm_120)
ds4: CUDA loading model tensors into device cache: 80.04 GiB
ds4: CUDA startup model cache prepared 80.76 GiB of tensor spans in 16.198s
Preparing the model cache from NVMe took about 16.2 seconds. For a local 284B MoE runtime, the startup wait is quite manageable.
Q2-imatrix Quantization
The GGUF I used applies aggressive asymmetric quantization only to the routed experts in DeepSeek V4 Flash.
| Tensor class | Quant |
|---|---|
| routed expert up/gate | IQ2_XXS |
| routed expert down | Q2_K |
| shared experts | Q8_0 |
| attention projections | Q8_0 |
| output head | Q8_0 |
| router / embedding / auxiliary blocks | F16 / F32 |
In an MoE model, routed experts account for most of the model size, while each token only passes through a subset of the experts. This quantization compresses the routed experts aggressively, while keeping higher precision for quality-sensitive parts such as the router, attention projections, shared experts, and output head. The result is a 284B model that fits into the 80GiB range while still aiming to avoid collapse in coding-agent workloads.
Generation Throughput
Generation throughput was 43.6 tok/s on short text and 31.4 tok/s at 50K context.
| Context / generation | Generation speed | Notes |
|---|---|---|
| Short prompt, about 100 tokens | 43.6 tok/s | Thinking mode |
| Medium, about 400 generated tokens | 41.7 tok/s | Thinking mode |
| Long, 4,058 generated tokens | avg 38.5 tok/s / min 37.3 tok/s | Thinking to Text |
| 20K context | 36.3 tok/s | Tool calling enabled |
| 33K context | 35.3 tok/s | Stable |
| 50K context | 31.4 tok/s | Very stable |
TG drops as context gets deeper, but the curve was fairly gentle. It starts at 43 tok/s and still holds the 31 tok/s range at 50K context, which is already a practical range for a local coding-agent orchestrator.
For my workload, 32K-64K looks like the easiest sweet spot. The design of DwarfStar 4 makes very long contexts such as 256K attractive, but for agent workloads, the stronger lever is not just increasing context. It is designing reusable prefixes and session management correctly.
Prefill
Prefill proceeds in 2048-token chunks. Even at deeper context, it stayed above 245 tok/s.
| Token count | Prefill speed |
|---|---|
| 13K tokens | 267 tok/s |
| 20K tokens | 262 tok/s |
| 30K+ tokens incremental | 245-251 tok/s |
If prefill is too slow, the overall experience gets much worse, and here the 20K-context result was 262 tok/s. I am still not sure how to judge that number. I have been tuning GLM-5.1, and that setup is now around TG23 and PP700. For an orchestrator, I mostly want prefill speed.
There is already an MTP-related PR in the repository, so if that becomes usable, the story may change quite a bit. At the moment it is usable, but I have not seen much benefit from it yet.
VRAM Usage
VRAM is almost fully consumed.
GPU MEM: 93,142 MiB / 95,593 MiB (95%)
The model tensor cache is 80.76 GiB, and context buffers plus compute pools sit on top of that. Since this is a fully single-GPU run with no CPU offload, it uses the RTX PRO 6000 Blackwell 96GB very cleanly.
Compared with dual-GPU or CPU/GPU hybrid giant-MoE setups, operations are much simpler. Model, runtime, and context all fit on one GPU, so it is straightforward to expose the server as an OpenAI-compatible API for Zed or my own agent stack.
Disk KV Cache
One of the most interesting parts of DwarfStar 4 is that disk KV cache is treated as a first-class feature. It combines DeepSeek V4 Flash’s compressed KV cache with fast NVMe, evicting and reusing KV state on disk. It feels somewhat like LMCache. Since this does not need to be server-grade storage, an extremely fast external M.2 drive dedicated to KV cache also sounds like a practical option, and it would make heat easier to manage.
In my log, KV save on eviction completed in about 200-370ms.
kv cache stored tokens=3405 size=67.56 MiB save=198.9 ms reason=evict
kv cache stored tokens=54163 size=734.07 MiB save=371.9 ms reason=evict
I confirmed that the cold, continued, and evict trigger patterns worked. Prefix reuse also showed up in measurement.
| Run | Response time |
|---|---|
| First run | 0.148 s |
| Second run | 0.073 s |
The second response took almost half the time. For a coding agent that repeatedly reads a large system prompt or repository context, this prefix reuse directly affects TTFT.
This was also the biggest design caveat in my environment. My own agent has a context manager built around multiple sessions, and it does not compose cleanly with DwarfStar 4’s KV reuse as-is. I added a DwarfStar 4-specific context manager and adapter so the orchestration session can absorb the single-session assumption.
Comparison With Other Platforms
This is not a strict apples-to-apples comparison, but when I line up public information and values I observed locally, decode performance moves in the same direction as memory bandwidth.
| Platform | Memory bandwidth | Generation | Notes |
|---|---|---|---|
| DGX Spark GB10 | 273 GB/s | 10-14 tok/s | Reference value |
| Mac Studio / Apple Silicon | configuration-dependent | 16-36 tok/s | Reference value |
| RTX PRO 6000 Blackwell Max-Q | 1,792 GB/s | 43.6 tok/s | My measurement |
MoE decode has to read expert weights every token, so memory bandwidth matters a lot. The RTX PRO 6000 Blackwell Max-Q has 1,792 GB/s of GDDR7 bandwidth, and a single GPU reached the 43 tok/s range. A non-Max-Q RTX variant may be able to push PP a little further.
The implementation is still alpha, so I expect a lot of remaining headroom.
- CUDA backend is still alpha-stage
- MTP support
Coding-Agent Operation
I connected Zed’s AI Assistant to the OpenAI-compatible API of ds4-server and ran real coding tasks through it.
DwarfStar 4 natively supports the DeepSeek V4 Flash DSML tool format, and it was able to execute tool calls such as these autonomously.
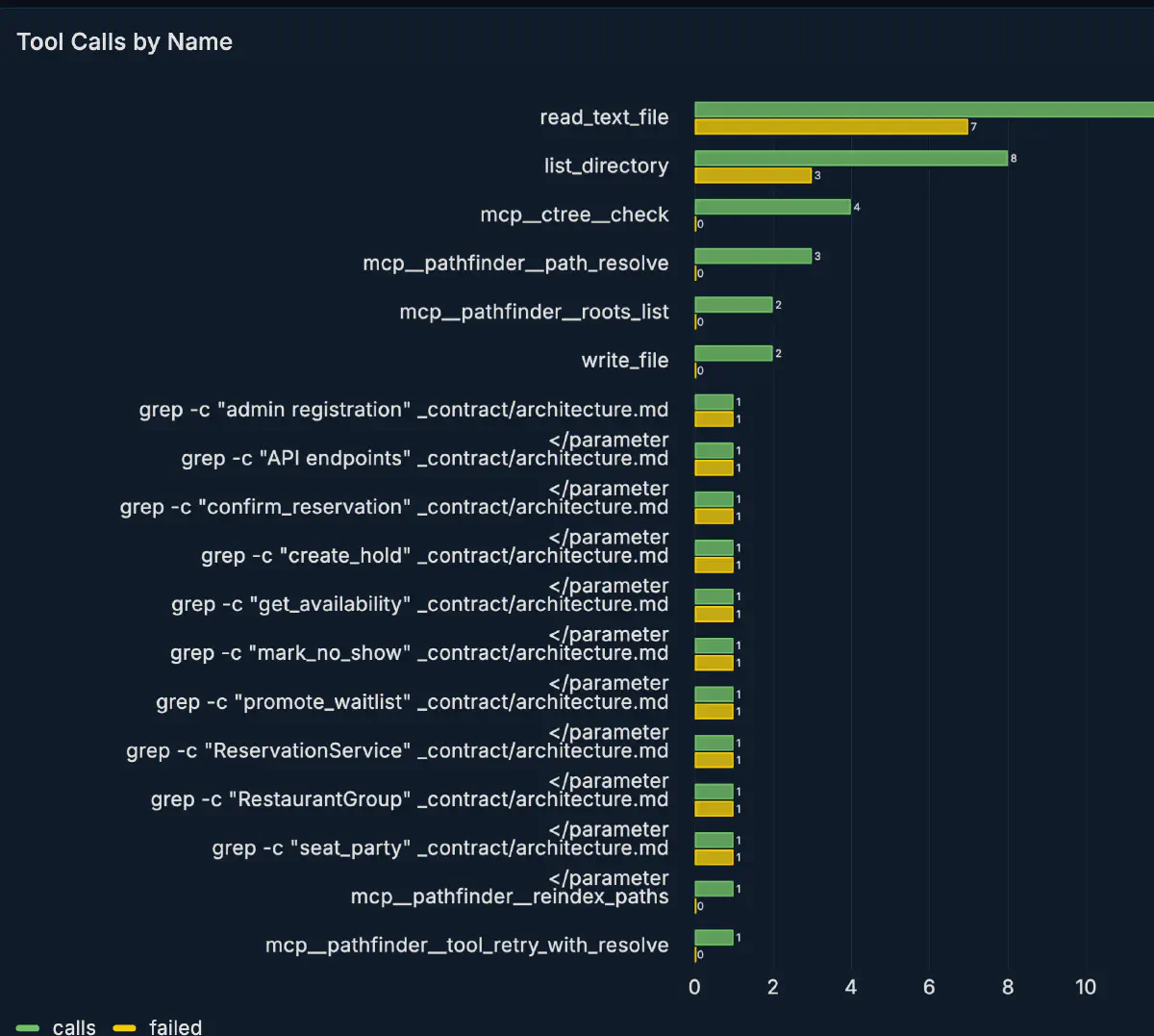
roots_listdirectory_treeread_fileterminalspawn_agent
Looking at the tool-call breakdown, my built-in tools read_text_file and list_directory were used frequently, and ctree plus pathfinder were also called. On the other hand, through terminal, I also saw a habit of repeatedly running grep -c against _contract/architecture.md. This behavior is close to existing Codex / Claude-style agents. It is useful for quick local checks, but for structural understanding it is more context-efficient to steer toward ctree or pathfinder, so this area likely needs correction.
Even at 50K context, tool-call generation stayed above 31 tok/s. Multi-turn agent sessions completed stably, so the hands-on feel was strong, not just the benchmark numbers. The official sampling values were not ideal for the orchestrator role, so I adjusted them.
What stood out most was that the behavior felt close to current Codex and Claude. Of course, I have not validated it nearly enough to call it a full replacement, but at minimum the conditions are there for a local LLM orchestrator model.
I already started swapping it into my own agent for verification. This is only a first look, not a full evaluation, but as a model to run on an RTX PRO 6000 Blackwell 96GB, the balance of speed and context looks very good.
DwarfStar 4 Has The Pieces This Use Case Needs
model=deepseek-chatcan select non-thinking mode--warm-weightscan reduce first-inference stutter--dir-steering-fileand--dir-steering-ffn -1can apply verbosity steering-n 4096can constrain the default output budget- disk KV cache can preserve prefix reuse across a long orchestration session
For code-review workers, keeping thinking mode and longer context makes sense. For the orchestrator, model=deepseek-chat fixed to non-thinking mode and focused on dispatch is the more natural role split.
The help text explicitly documents the non-thinking selection conditions.
thinking={type:disabled}, think=false, or model=deepseek-chat selects non-thinking mode.
Main ds4-server parameters:
| Area | Parameter | My read |
|---|---|---|
| Model | -m, --model | Points to a ds4-specific GGUF. This is not a generic GGUF runner |
| MTP | --mtp, --mtp-draft, --mtp-margin | Speculative decoding. Still experimental, and lower priority for a resident grandpa |
| Context | -c, --ctx | Context allocated at startup. 32768 is enough for grandpa, while frisky has room to stretch to 131072 |
| Output | -n, --tokens | Default when max_tokens is omitted. For grandpa, constrain it to around 4096 |
| CPU | -t, --threads | Helper threads for tokenization and prompt rendering. Leaving it unset is fine |
| Quality | --quality | Uses stricter kernels. Useful for quality evaluation or benchmarks, usually unnecessary for resident grandpa |
| Steering | --dir-steering-file, --dir-steering-ffn, --dir-steering-attn | For grandpa, apply -1 on the FFN side to amplify the succinct direction. Attention-side steering is experimental |
| Warmup | --warm-weights | Worth enabling for a resident service. Reduces first-inference page faults and stutter |
| Backend | --cuda, --metal, --cpu, --backend | CUDA for RTX PRO 6000. CPU is for diagnostics |
| API | --host, --port | Split roles by port, such as grandpa=8000 and frisky=8001 |
| Trace | --trace | Saves prompts, cache decisions, outputs, and tool calls in human-readable form. May be useful for fulfillment logs or DPO data |
| Thinking | reasoning_effort, thinking, think, model | grandpa should use model=deepseek-chat for non-thinking mode. reviewer / frisky can benefit from thinking mode |
| Disk KV | --kv-disk-dir, --kv-disk-space-mb, --kv-cache-* | 4GB likely suffices for grandpa. Workers with long review history may want 16GB |
| Tools | --disable-exact-dsml-tool-replay, --tool-memory-max-ids | Mostly irrelevant for grandpa when it does not use tool calling |
For a resident grandpa deployment, I would likely use this shape. In production, I would start with --ctx 65536, --tokens 4096, 32GB of disk KV, and --trace enabled. If it is constrained further into a tool-less dispatch-only role, --ctx 32768 and 4GB of disk KV should also be enough.
[Container]
ContainerName=grandpa
Image=registry.home.arpa/dwarfstar4:latest
Pull=always
Network=host
AddDevice=nvidia.com/gpu=0
Volume=/mnt/data/models/models--antirez--deepseek-v4-gguf/snapshots/c566ab6d7c696ddd0c7f124e115228af1a326824:/model:ro
Volume=/mnt/data/models/models--antirez--deepseek-v4-gguf/kv_cache:/kv
Exec=-m /model/DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf --ctx 65536 --tokens 4096 --host 0.0.0.0 --port 8000 --warm-weights --kv-disk-dir /kv --kv-disk-space-mb 32768 --trace /kv/trace.log
To verify the same settings once by hand, podman run --rm -it works directly.
podman run --rm -it \
--device nvidia.com/gpu=0 \
-v /mnt/data/models/models--antirez--deepseek-v4-gguf/snapshots/c566ab6d7c696ddd0c7f124e115228af1a326824:/model:ro,Z \
-v /mnt/data/models/models--antirez--deepseek-v4-gguf/kv_cache:/kv:Z \
--network host \
registry.home.arpa/dwarfstar4:latest \
-m /model/DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf \
--ctx 65536 \
--tokens 4096 \
--host 0.0.0.0 \
--port 8000 \
--warm-weights \
--kv-disk-dir /kv \
--kv-disk-space-mb 32768 \
--trace /kv/trace.log
When using steering, generate the vector under dir-steering/ in the ds4 repository, mount it into the container, and pass it through --dir-steering-file. verbosity.f32 does not exist inside the container image by default, so generating it on the host and mounting it is the practical route.
cd ~/src/ds4
python3 dir-steering/tools/build_direction.py \
--ds4 ./ds4 \
--model ds4flash.gguf \
--good-file dir-steering/examples/succinct.txt \
--bad-file dir-steering/examples/verbose.txt \
--out dir-steering/out/verbosity.json \
--component ffn_out \
--ctx 512
ls -lh dir-steering/out/verbosity.f32
ds4-server has a different cache strategy from the cache pool in ik_llama.cpp, which reuses partial cache through f_keep. ds4 keeps only one live KV cache in VRAM. When switching sessions, it evicts the current KV to disk, checks whether the next request prefix hits the disk cache, and if it does, reads that cache back as the live session.
Directional Steering
y = y - scale * direction[layer] * dot(direction[layer], y)
The bundled verbosity vector has 43 layers × 4096 dimensions and is about 704KB. The scale changes output verbosity at runtime.
| Scale | Behavior |
|---|---|
-1 | Compresses output length to about half |
2 | Strengthens detailed explanations |
This works well with multi-agent role tuning. For example, the orchestrator can use -1 for short decisions, while the reviewer can use 2 for more detailed analysis. Being able to change output density per role without fine-tuning is interesting as a control surface for a local multi-agent runtime.
Summary
| Item | Value |
|---|---|
| Model | DeepSeek V4 Flash 284B |
| Runtime | DwarfStar 4 |
| GPU | RTX PRO 6000 Blackwell Max-Q 96GB x 1 |
| Quant | Q2-imatrix |
| Short generation | 43.6 tok/s |
| 50K context | 31.4 tok/s |
| Prefill | 245-267 tok/s |
| Model cache | 80.76 GiB |
| Peak VRAM | 93.1 GiB |
Loading DeepSeek V4 Flash 284B onto a single RTX PRO 6000 Blackwell and holding 43 tok/s generation plus the 31 tok/s range at 50K context was impressive. The 512MB L3 cache on the EPYC 9175F may also be helping.
DwarfStar 4 is still alpha-stage, but it designs the inference engine, quantization, disk KV cache, tool calling, and directional steering together for DeepSeek V4 Flash. As a result, it is getting close to a practical way to run a giant MoE model locally as a coding agent at usable speed.
In my agent, at least, the behavior felt viable. Compared with my more converged GLM-5.1 setup, the content was still a little rough, but I have only just started the optimization pass, so this is a promising starting point.
If the CUDA backend, disk KV cache, and directional steering continue to mature, DwarfStar 4 could become a strong base for a local multi-agent runtime. I also added AMD MI350P PCIe Cards to the links as a next candidate, because the hardware profile looks like a good fit.