Gemma 4 31B on vLLM/SGLang: NVFP4/FP8 and MTP Benchmark
A record of running Gemma 4 31B IT on vLLM 0.21.0 and SGLang gemma4-mtp, comparing NVFP4/FP8 block quantization, FP8/BF16 KV cache, and Gemma 4 MTP speculative decoding.

I ran Gemma 4 31B IT on a single RTX PRO 6000 Blackwell 96GB and compared vLLM 0.21.0 with SGLang gemma4-mtp. What I wanted to understand was not just which runtime was faster, but how KV cache dtype, KV pool size, and MTP speculative decoding behaved in real coding-agent work.
In this record, I compared NVFP4/FP8 block on the vLLM side and FP8 block + BF16 KV/FP8 KV on the SGLang side. In short, vLLM with NVFP4 + FP8 KV, or SGLang with FP8 block + FP8 KV, both fit practical use cases well. SGLang cannot match vLLM’s KV cache capacity, but in actual tasks it felt better at tool use and output quality. I also recorded videos of the generation runs.
Videos
The SGLang-side run record.
Video link: https://www.youtube.com/watch?v=YlysBl5Qg34
Video link: https://www.youtube.com/watch?v=cgYbqnwqygM
Comparison Table
I used the same RedHatAI FP8 model for the 256K-context checks. NVFP4 was measured with NVIDIA’s model.
| Config | Runtime | Weights | KV cache | KV pool | Peak TG | Typical TG | Peak accept | Notes |
|---|---|---|---|---|---|---|---|---|
| A | vLLM 0.21.0 | NVFP4 | FP8 | 876K tok | 109.8 tok/s | 90-100 tok/s | 99.5% | 262K ctx, MTP x4 |
| B | vLLM 0.21.0 | FP8 block | FP8 | 876K tok | 115.3 tok/s | 80-100 tok/s | 93.5% | 262K ctx, MTP x4 |
| C | SGLang gemma4-mtp | FP8 block | BF16 | 69.7K tok | ~80 tok/s | 55-75 tok/s | ~90% | 262K ctx, SWAKVPool, MTP x5/6 |
| D | SGLang gemma4-mtp | FP8 block | FP8 | 139.5K tok | ~93.8 tok/s | 70-90 tok/s | ~96% | 262K ctx, SWAKVPool, MTP x5/6 |
- NVFP4 sometimes collapsed into repetition. I may have made some mistake in sampling or configuration.
- vLLM + MTP + prefix caching reaches the highest TG band in single-stream generation.
- vLLM throughput split into two bands that tracked MTP accept rate more than load.
- With FP8 KV, SGLang can take about twice the token capacity of BF16 KV at the same SWAKVPool footprint.
- SGLang FP8 KV had lower raw throughput than vLLM, but the coding-agent quality felt better. Being able to set
min_pis also useful.
What I Wanted To Compare
This run separated five axes:
- Runtime:
vLLMvsSGLang - Weight quantization:
NVFP4vsFP8 block - KV cache dtype:
FP8vsBF16 - Context budget and KV pool topology: vLLM flat KV vs SGLang sliding-window KV pool
- Speculative decoding: MTP x4 vs MTP x5/6
If all I cared about were benchmark numbers, peak throughput would be enough. But real coding-agent work mixes long context, repeated tool calls, free-form writing, and structured output. For day-to-day capacity planning, it is more useful to watch the gap between windows where MTP is highly accepted and windows where acceptance drops.
Hardware
| Item | Value |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell 96GB (SM120) |
| Host | AMD EPYC, 768GB DDR5 ECC |
A. vLLM 0.21.0: NVFP4 weights + FP8 KV
The first baseline was Gemma 4 31B with NVFP4 4-bit weights, FP8 KV cache, and MTP speculative decoding enabled with the Gemma 4 Assistant draft model. Context was 262,144, and MTP used num_speculative_tokens=4. (*official cookbook)
Configuration
| Item | Value |
|---|---|
| Runtime | vLLM 0.21.0 |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | ModelOpt NVFP4 weights |
| KV cache | FP8 |
| Context length | 262,144 |
| Tensor parallel | 1 |
| Speculative decoding | Gemma 4 MTP, 4 speculative tokens |
| Attention backend | Triton Attention |
| Sampling backend | FlashInfer |
| Compile backend | torch.compile / Inductor |
Server Command
This is the actual command. It includes some unnecessary environment variables left over from reuse.
podman run --rm \
--name test-model \
--device nvidia.com/gpu=0 \
--ipc=host \
-p 8000:8000 \
-v /mnt/data/models:/hf/hub:ro \
-e HF_HOME=/hf \
-e HF_HUB_OFFLINE=1 \
-e TORCH_CUDA_ARCH_LIST=12.0 \
-e VLLM_FLASHINFER_MOE_BACKEND=throughput \
-e VLLM_TARGET_DEVICE=cuda \
-e VLLM_USE_FLASHINFER_MOE_FP4=1 \
registry.home.arpa/vllm/vllm-openai:v0.21.0-ubuntu2404 \
/hf/hub/models--nvidia--Gemma-4-31B-IT-NVFP4/snapshots/e5ef03afa233c35cb000323ff098d4291e1dd07c \
--host 0.0.0.0 \
--port 8000 \
--served-model-name test-model \
--dtype auto \
--kv-cache-dtype fp8 \
--tensor-parallel-size 1 \
--trust-remote-code \
--gpu-memory-utilization 0.85 \
--max-num-seqs 1 \
--async-scheduling \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--speculative-config '{"model":"/hf/hub/models--google--gemma-4-31B-it-assistant/snapshots/4735700dca7bd22fad5dc348c228b50ec6cbac6d","num_speculative_tokens":4}' \
--max-model-len 262144 \
--override-generation-config '{"temperature":0.9,"top_p":0.85,"top_k":64,"presence_penalty":0.0,"repetition_penalty":1.13}'
Observed Logs
Representative values during the run looked like this.
Generation throughput: 95.9 tok/s acceptance length: 4.28 draft acceptance: 82.0%
Generation throughput: 95.3 tok/s acceptance length: 4.18 draft acceptance: 79.5%
Generation throughput: 109.8 tok/s acceptance length: 4.97 draft acceptance: 99.2%
Generation throughput: 107.6 tok/s acceptance length: 4.98 draft acceptance: 99.5%
Aggregated:
| Metric | Value |
|---|---|
| Generation throughput | Up to 109.8 tok/s |
| Typical active generation | Around 90-100 tok/s |
| Mean MTP acceptance length | Up to 4.98, equivalent to max 5 |
| Average draft acceptance rate | Around 80-90% |
| Best draft acceptance rate | 99.5% |
| GPU memory used for model load | 32.06 GiB |
| KV cache size | 876,006 tokens |
Throughput split into a band around 95 tok/s and a band above 107 tok/s. The difference was pulled more by MTP accept rate than by GPU load.
The KV cache had room for 876K tokens, about 3.3x the 262K context window. However, with --max-num-seqs 1, a single session cannot use that surplus.
I also tried several sampling settings to improve tool-call iteration stability. For this model, vLLM + MTP, text-only, and min_p could not be used together, so I adjusted temperature, top_p, top_k, and repetition_penalty. I did not land on a definitive setting for this workload.
When it collapsed, the Zed-side output fell into repeated (Sigh) and (Laughter) strings, while the vLLM log on the right kept reporting accepted/drafted throughput and acceptance rate.
I was the one sighing.
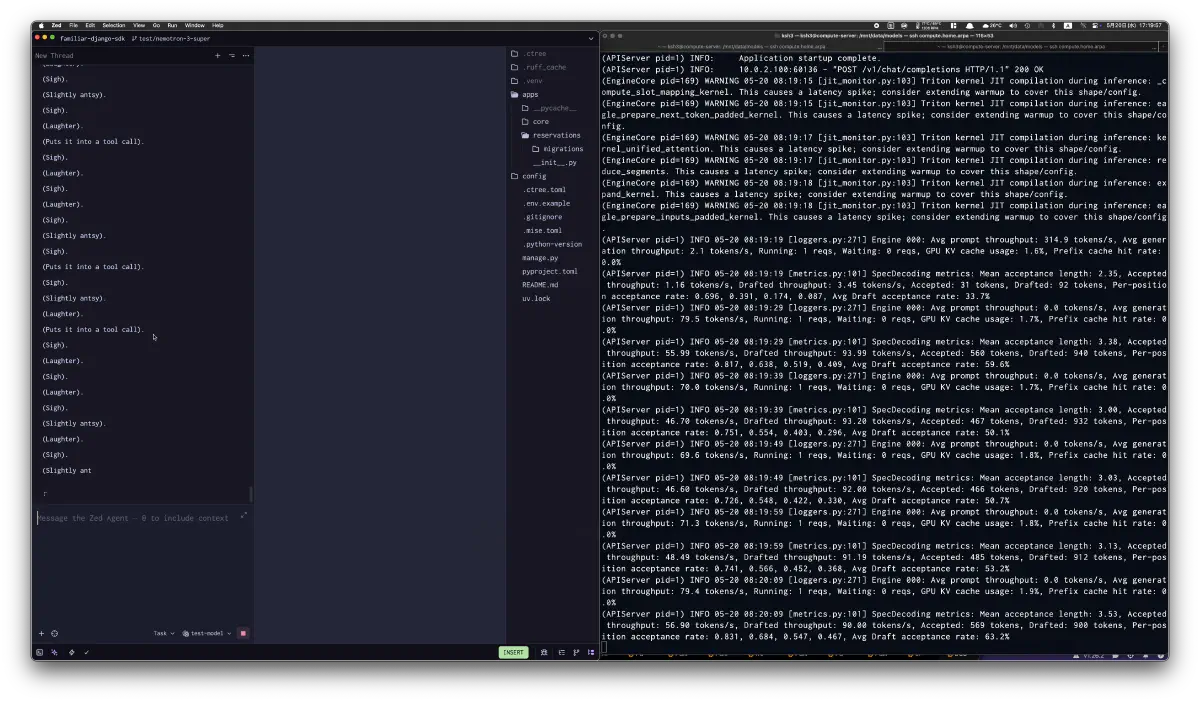
B. vLLM 0.21.0: FP8 block weights + FP8 KV
This used the same vLLM 0.21.0 runtime as A, changing only the weights from NVFP4 to FP8 block. KV cache stayed FP8.
Configuration
| Item | Value |
|---|---|
| Runtime | vLLM 0.21.0 |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache | FP8 |
| Context length | 262,144 |
| GPU KV cache size | 876,006 tokens |
| Speculative decoding | Gemma 4 Assistant draft model, num_speculative_tokens=4 |
Observed Values
Generation throughput: up to 115.3 tok/s
Typical active generation: around 80-100 tok/s
Mean MTP acceptance length: up to 4.74
Average draft acceptance rate: around 80-88%
Best draft acceptance rate: 93.5%
GPU KV cache size: 876,006 tokens
Compared with NVFP4 in A, peak throughput rose slightly from 109.8 tok/s to 115.3 tok/s. On the other hand, peak draft acceptance fell from 99.5% to 93.5%. The KV dtype stayed FP8, so the KV pool size was the same 876K tokens as A.
C. SGLang gemma4-mtp: FP8 block weights + BF16 KV
Next, I switched the runtime to SGLang gemma4-mtp. Weights stayed FP8 block, and the KV cache was BF16. On the SGLang side, this becomes a sliding-window-aware SWAKVPool, so capacity looks different from vLLM’s flat KV cache.
The timing was convenient: lmsysorg/sglang:gemma4-mtp images had been pushed the day before, so I used that line of images. This may have been the commit where NEXTN changed to FROZEN_KV_MTP.
Configuration
| Item | Value |
|---|---|
| Runtime | SGLang gemma4-mtp |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache dtype | torch.bfloat16 |
| Context length | 262,144 |
| Speculative decoding | Auto-promoted from NEXTN to FROZEN_KV_MTP |
| Draft model | Gemma 4 Assistant draft model |
| Speculative steps | speculative_num_steps=5 |
| Draft tokens | speculative_num_draft_tokens=6 |
SWAKVPool Initialization Values
full_layer_tokens=69757
swa_layer_tokens=55805
max_total_num_tokens=69757
KV Memory
SWA KV: 21.29 GB K + 21.29 GB V
Full KV: 2.66 GB K + 2.66 GB V
Total SWAKVPool usage: 47.90 GB
Observed Values
Typical decode throughput: around 55-75 tok/s
Peak throughput: around 80 tok/s class
Typical accept length: around 4.5-5.5
Typical accept rate: around 75-90%
In terms of FP8 block weights, this is close to vLLM B, but throughput was lower than vLLM. Representative peak values were in the 80 tok/s range, and typical throughput was 55-75 tok/s. The logs did show some low-90s samples, but the comparison table treats this as about 80 tok/s on the conservative side. KV capacity was 69.7K tokens, far below vLLM’s 876K tokens.
D. SGLang gemma4-mtp: FP8 block weights + FP8 KV
This used the same SGLang setup as C, changing only KV cache dtype to torch.float8_e4m3fn. In the SGLang runs, as the video makes fairly visible, this was the configuration that worked best for real coding-agent tasks.
Configuration
| Item | Value |
|---|---|
| Runtime | SGLang gemma4-mtp |
| GPU | RTX PRO 6000 Blackwell 96GB |
| Quantization | FP8 block |
| KV cache dtype | torch.float8_e4m3fn |
| Context length | 262,144 |
| Speculative decoding | Auto-promoted from NEXTN to FROZEN_KV_MTP |
| Draft model | Gemma 4 Assistant draft model |
| Speculative steps | speculative_num_steps=5 |
| Draft tokens | speculative_num_draft_tokens=6 |
SWAKVPool Initialization Values
full_layer_tokens=139515
swa_layer_tokens=111612
max_total_num_tokens=139515
KV Memory
SWA KV: 21.29 GB K + 21.29 GB V
Full KV: 2.66 GB K + 2.66 GB V
Total SWAKVPool usage: 47.90 GB
Observed Values
Typical decode throughput: around 70-90 tok/s
Peak throughput: around 93.8 tok/s
Typical accept length: around 5.0-5.8
Typical accept rate: around 80-96%
During an actual task, Zed Agent was generating a Django reservation-management feature on the left, while I watched SGLang decode batch logs, accept length, accept rate, and generation throughput on the right.
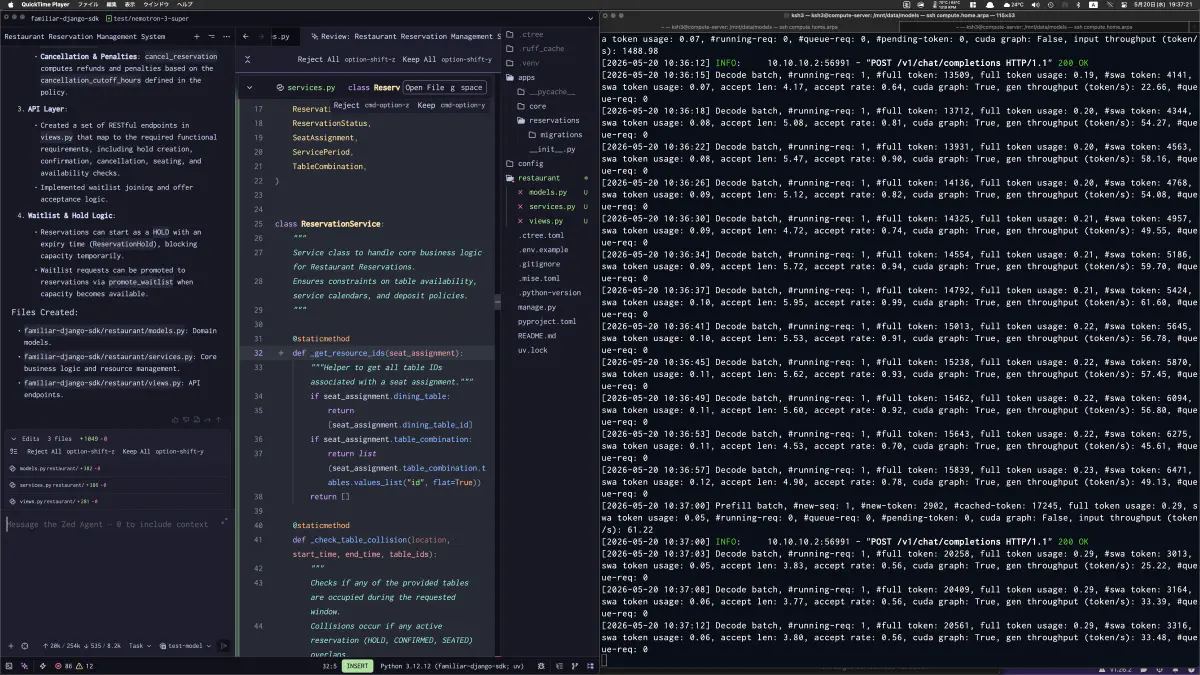
Compared with BF16 KV in C, full-layer tokens rose from 69,757 to 139,515 at the same 47.90GB SWAKVPool footprint. That is almost exactly 2x. SWA layer tokens also rose from 55,805 to 111,612.
SGLang warned that FP8 KV scaling factors defaulted to 1.0 in this configuration. Within the range of this run, I did not observe a visible quality regression.
Cross-Configuration Comparison
KV capacity was controlled more by KV cache dtype than by weight precision. In the SGLang C to D change, weights stayed FP8 block, and simply changing KV from BF16 to FP8 increased full-layer tokens from 69.7K to 139.5K. Conversely, in vLLM A and B, changing weights from NVFP4 to FP8 block did not change the KV pool, because the KV dtype stayed FP8.
Runtime choice also mattered a lot. At roughly equivalent weight precision, vLLM had higher raw throughput than SGLang. In this run, SGLang’s strength was not throughput but output quality and follow-through in agentic workloads.
| Viewpoint | Best Configuration | Reason |
|---|---|---|
| Highest peak throughput | B: vLLM FP8 block + FP8 KV | Reached 115.3 tok/s |
| Daily throughput stability | A: vLLM NVFP4 + FP8 KV | Stable in the 90-100 tok/s band, with high accept peak |
| MTP acceptance ceiling | A: vLLM NVFP4 + FP8 KV | Reached 99.5% |
| Practical SGLang setup | D: SGLang FP8 block + FP8 KV | Higher capacity than BF16 KV and better subjective quality |
| KV capacity | A/B: vLLM FP8 KV | Reserved 876K tokens |
Summary
If the only criterion is speed, vLLM is strong for single-stream generation. A and B both reserved a 876K-token KV pool, and B reached a peak throughput of 115.3 tok/s. A reached an acceptance ceiling of 99.5%, and it is very fast when MTP fits the window.
On the other hand, SGLang FP8 KV felt better in actual coding-agent work. D had about twice the KV capacity of C with BF16 KV, and typical decode throughput rose to 70-90 tok/s. It does not have vLLM’s KV pool size, but if tool use and output stability matter more, D is easy to use.
The caveats:
- vLLM was measured as a single stream with
--max-num-seqs 1. - vLLM reports runtime
accepted throughput, while SGLang reportsdecode throughput, so the numbers are not perfectly identical metrics. - Configurations using MTP use the Gemma 4 Assistant draft model.
- NVFP4 had cases where output collapsed into repetition, so there may still be an unresolved sampling or configuration issue.
Personally, I adopted SGLang FP8. Depending on the role, I would think of it as a CTX 96-128K, KV FP8 operating point.