Running Kimi-K2.6 Locally: Making a 1T MoE Practical with ik_llama.cpp and Blackwell
A local validation of Kimi-K2.6 (1T MoE, 384 experts × 8 active) on RTX PRO 6000 Blackwell Max-Q 96GB x2, covering ik_llama.cpp MLA optimization, expert tensor placement, the gap from mainline llama.cpp, and practical Django coding-task results.

Moonshot AI’s Kimi-K2.6 is a 1T-class MoE model built on a DeepSeek2-style architecture that activates only 8 experts out of 384. The total parameter count is huge, but the active parameters are constrained enough that if the CPU-memory and GPU-VRAM split is designed well, it can reach a practical speed range as a local worker for a solo developer.
In this validation I tested IQ3_K and Q4_X from ubergarm/Kimi-K2.6-GGUF on EPYC 9175F + RTX PRO 6000 Blackwell Max-Q 96GB x2. What I cared about was not a flashy single benchmark number, but how far the model could go on real coding tasks when ik_llama.cpp is used with MLA and expert placement. Vision is still unsupported, so this is text-generation only. Mainline llama.cpp does support more there, so I also rebuilt it with --no-cache and tried it, but the tool-call parser was broken on my side and that part remains for a later retry.
Video link: https://www.youtube.com/watch?v=skTE19_JRYg
To summarize the video first: this run puts Kimi-K2.6 (1T MoE, 384 experts × 8 active) on dual RTX PRO 6000 Blackwell Max-Q 96GB, EPYC 9175F, and 768GB DDR5-6400 through ik_llama.cpp, tries several expert-placement patterns, settles on IQ3_K as the practical sweet spot, and then records a final demo. The core setup uses ubergarm’s IQ3_K (3.85 bpw, 460 GiB), keeps only 4 to 10 expert layers on GPU, and leaves the rest on CPU pinned memory in a head/tail split.
- TG lands in the
17.9to21 t/srange, and PP cold in the223to377 t/srange. Both change noticeably with-ubsize and-otplacement. - A continuous
14,707-token generation still held19.57 t/s, so long generations stayed usable. In my setup the model mostly sees custom MCP tools, and it does not always call them heavily, but the fact that it can create issues, milestones, and PRs on a local-network Gitea by itself is genuinely impressive. It still feels like there is headroom if TG rises a bit more and tool use gets closer to the way Opus 4.6 behaves. Withctk/ctv f16at 256k, VRAM was still below roughly 150 GB if I remember correctly. IQ3_Kran at17.9to20.9 t/sandQ4_Xat16.6to19.0 t/s, so I ultimately preferredIQ3_K. In practice they felt fairly close; with the sameAGENTS.md, they behaved almost the same.- On a real task, the model generated a
real_estate_salesmodule with 15 models and 772 lines of proper Django code compatible with v6. - The license is Modified MIT. The commercial restriction kicks in at about
$20Mmonthly revenue or100MMAU, which in practice makes it close to MIT for the kinds of local use I care about.
Validation Environment
| Item | Configuration |
|---|---|
| CPU | AMD EPYC 9175F (16C/32T, L3 512MB, Zen 5) |
| RAM | 768 GB DDR5-6400 ECC RDIMM |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q 96GB x2 |
| OS | Ubuntu 24.04 LTS (minimal) |
| Runtime | ik_llama.cpp |
The model-side assumptions are:
| Item | Value |
|---|---|
| Model | Kimi-K2.6 |
| Architecture | DeepSeek2-style MoE + MLA |
| Total parameters | 1T class |
| Experts / Active | 384 / 8 |
| Main quants tested | IQ3_K (3.85 bpw), Q4_X (4.55 bpw) |
Why ik_llama.cpp Instead of Mainline llama.cpp
Kimi-K2.6 uses MLA (Multi-head Latent Attention) under a DeepSeek2-style architecture, so the inference engine needs explicit support for it. Mainline llama.cpp can load and start the model, but it does not expose anything equivalent to absorbed MLA mode (-mla 3), so it falls back to a standard KV path and cannot reach the intended TG. The more serious problem is in the chat-template parser: on my side the peg-native parser could not process Kimi-K2.6 special tokens such as <|tool_call_begin|>, and the runtime crashed on tool-call responses with Failed to parse input at pos 433: <|im_end|>. Rebuilding with --no-cache did not fix it on 2026-04-22. It still looks likely to be a template-side problem, so it is worth trying again after pulling a newer version.
Failed to parse input at pos 433: <|im_end|>
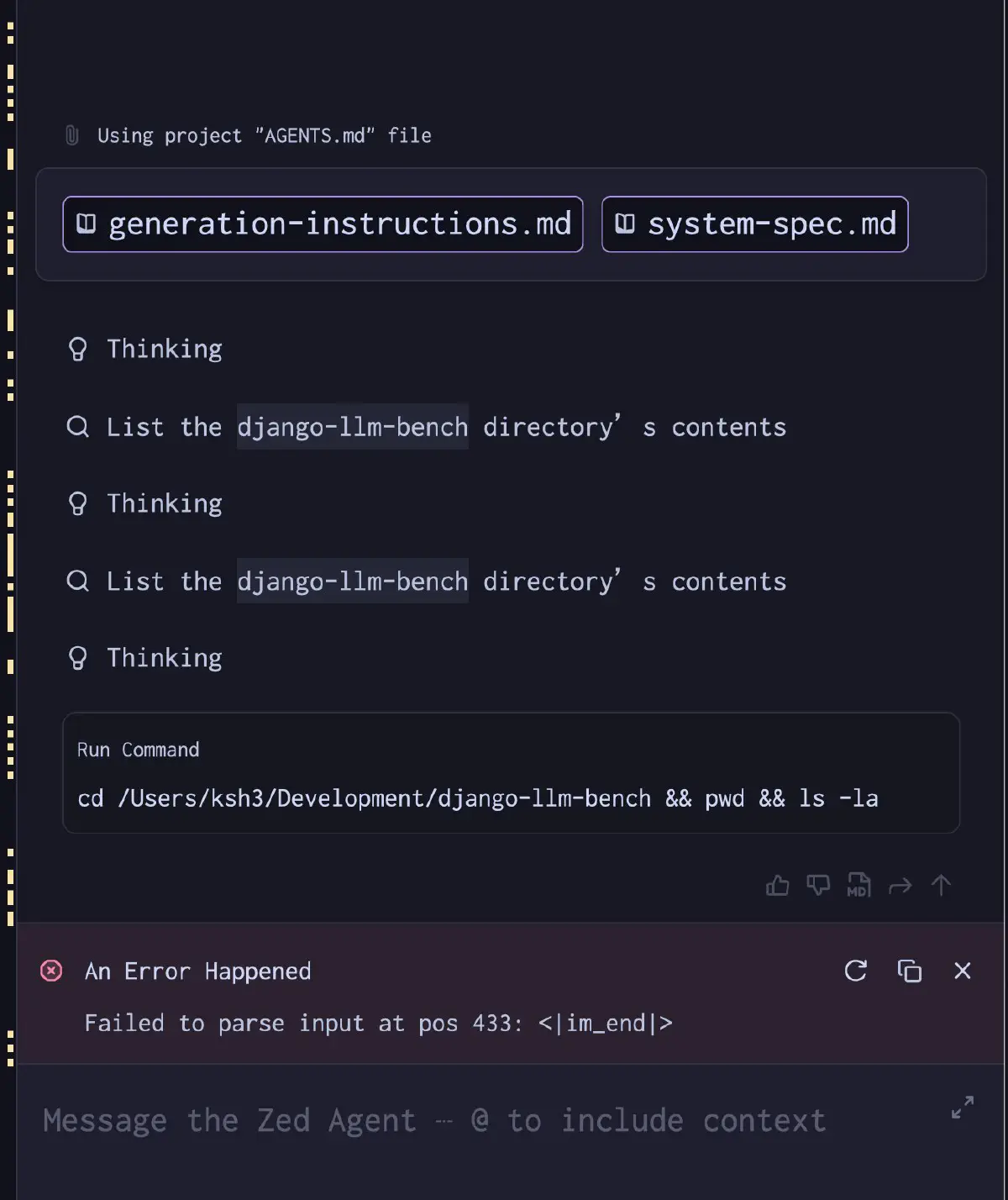
Expert Tensor Placement Determines TG
With a huge MoE like Kimi-K2.6 in a CPU/GPU hybrid setup, TG depends heavily on which expert layers get brought back to GPU. If every expert stays in CPU pinned memory, generation still works, but decode speed is harder to push up. So I tried a head/tail strategy: return only selected expert layers to GPU via -ot, and leave the rest on CPU.
Benchmark Results
| Config | Expert on GPU | TG avg (t/s) | PP cold (t/s) | VRAM/GPU |
|---|---|---|---|---|
Baseline (--cpu-moe) | 0 layers | 18.9 | 185 | ~11 GiB |
| 6-layer head/tail split | 6 layers (3+3) | 20.9 | 223 | ~52/60 GiB |
| 10-layer head-heavy | 10 layers (8+2) | 20.3 | 377 | ~43/44 GiB |
The balanced 6-layer split produced the best TG. The 10-layer head-heavy pattern lifted PP sharply when paired with -ub 4096, but decode slowed a bit because the layout leaned too far toward the head side.
The -ot Layout I Kept in the End
-ot "blk\.(1|2)\.ffn.*=CUDA0" \
-ot "blk\.(59|60)\.ffn.*=CUDA1" \
-ot "exps=CPU"
This puts the first two expert layers (blk.1-blk.2) on CUDA0 and the last two (blk.59-blk.60) on CUDA1, while leaving the remaining 56 expert layers on CPU pinned memory. In practice this layout used the two Blackwell cards in the rough mid-30s to high-30s GiB range while keeping decode in the 17-19 t/s band. For a 1T-class model that is meant to stay local, it is a workable layout when the goal is decode priority rather than packing the GPUs to the limit.
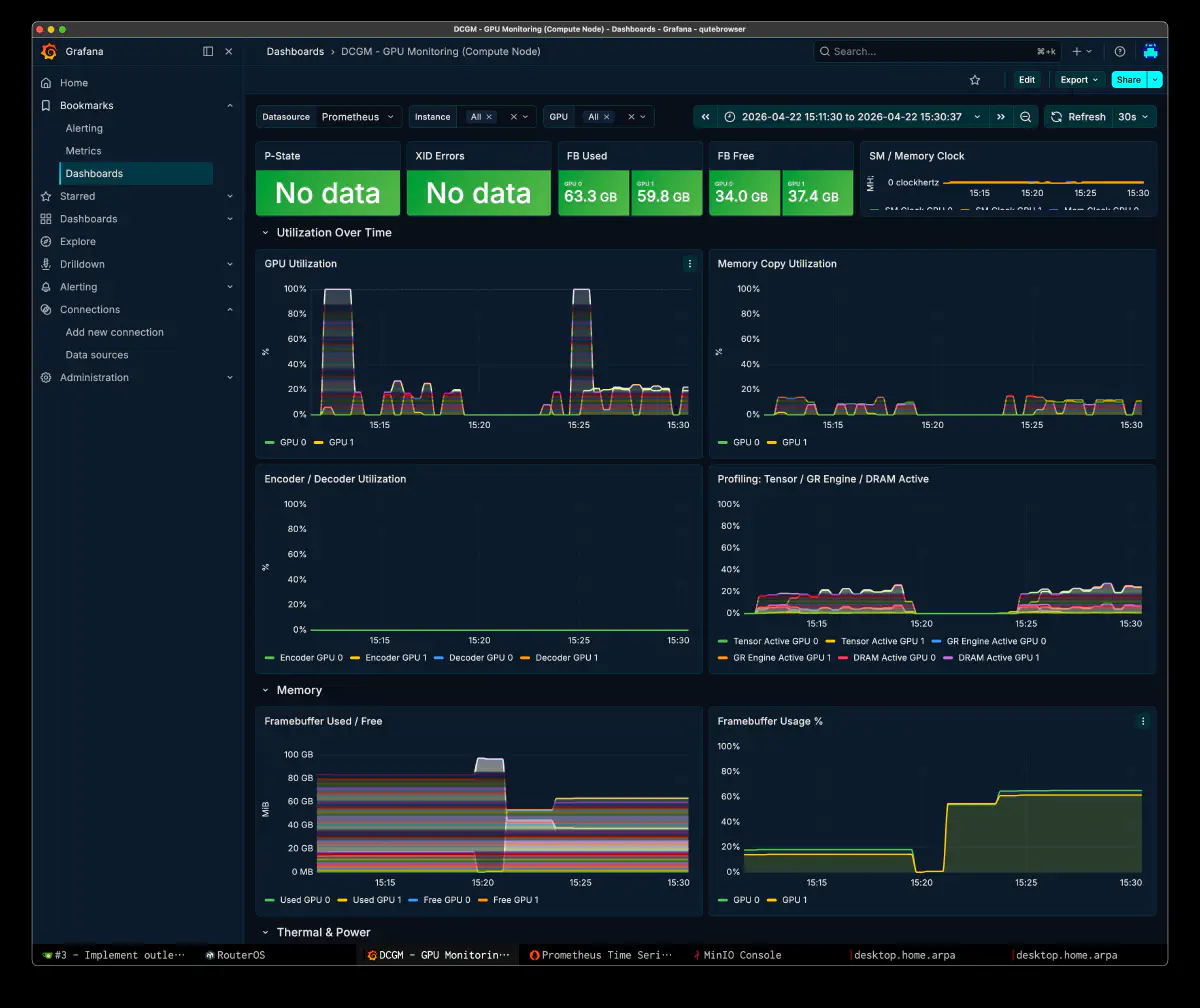
IQ3_K and Q4_X Are Good at Different Things
Even on the same Kimi-K2.6 model, IQ3_K and Q4_X feel different in practice.
| Quant | BPW | Model Size | TG avg (t/s) | PP cold (t/s) | CUDA_Host |
|---|---|---|---|---|---|
| IQ3_K | 3.85 | 460 GiB | 20.9 | 223 | 368 GiB |
| Q4_X | 4.55 | 544 GiB | 18.6 | 567 | 455 GiB |
Q4_X is dramatically faster at PP, but slower at TG. As expert tensors grow, the per-token CPU-to-GPU transfer cost grows with them, so the heavier quant loses ground on decode. In real coding runs, what matters more is not the initial prompt ingest speed but whether the model can keep decoding several thousand tokens without falling apart. On top of that, IQ3_K saves another 87 GiB of RAM, which makes it the more practical sweet spot.
Choosing -mla
On a DeepSeek2-style model such as Kimi-K2.6, the -mla choice directly changes the speed profile.
| Flag | KV cache mode | VRAM usage | Speed |
|---|---|---|---|
-mla 0 | Standard KV | Highest | Slowest |
-mla 1 | Compressed latent KV | Lowest | Slow |
-mla 3 | Absorbed MLA | Highest | Fastest |
Even at 132k context, the KV cache stays around 8.9 GiB. If VRAM is tight, -mla 1 is a viable escape hatch. On this 96GB x2 setup, though, -mla 3 was the rational choice because the goal was TG.
Quality on Real Coding Tasks
Benchmark numbers alone are not enough, so I also pushed Kimi-K2.6 through real tool-call coding tasks from Zed. The main runs used IQ3_K, non-thinking mode, and 4- to 10-layer -ot patterns.
massage_salon Module
In about 15 minutes, the model created a Gitea issue, adjusted my own semantic-diff context tool .ctree.toml, scaffolded Django v6, and generated models, admin, and apps in one pass. That run produced 15 models and 839 lines of final code.
restaurant Module
With the 10-layer head-heavy setup, it modeled procurement, profitability, workforce, sales, and master data as separate domains. It used patterns like RestaurantSettings proxies, TextChoices, UniqueConstraint, and MinValueValidator appropriately, which is a good sign for structural reasoning.
real_estate_sales Module
With a 3+3 split, it generated 14,707 tokens in a single request over about 12.5 minutes, holding TG at 19.57 t/s. The output was 15 model classes and 772 lines covering property, appraisal, brokerage agreements, viewings, purchase applications, loan screening, sale contracts, and settlement as one connected flow.
What stood out most was that the model inferred the behavior of my custom ctree MCP configuration from the system prompt alone, even though that tool is not in public training data, and then changed scope settings while continuing code generation. That kind of thing does not show up in a benchmark table, but it matters a lot for a local worker. After trying many models, my impression is still that once you get past the 500B range, you start feeling a different kind of baseline reasoning quality.
Kimi-K2.6 did not just emit tokens quickly. It stayed relatively stable through long units of work that included multi-file generation, test-plan enumeration, and repeated MCP tool calls.
ik_llama.cpp vs Mainline llama.cpp
The difference is fairly clear on the same hardware.
| Engine | Quant | TG (t/s) | PP cold (t/s) | Tool call |
|---|---|---|---|---|
ik_llama.cpp | IQ3_K | 20.9 | 223 | OK |
ik_llama.cpp | Q4_X | 18.6 | 567 | OK |
llama.cpp (mainline) | Q4_X | 15.4 | 188 | Crash |
So this is not just a case of mainline being slower by a few points. On my setup it actually failed on tool calls. I still want to retry it later because I also want to validate vision support, but for coding use without image input, ik_llama.cpp is the runtime I plan to keep using.
Reference: A Single-GPU Benchmark Seen in the HF Community
In ubergarm/Kimi-K2.6-GGUF discussion #3 on Hugging Face, I also saw a Q4_X benchmark on a single RTX PRO 6000 + EPYC 9355 + DDR5-6400 using aiperf. The average for a 16-turn conversation simulation looked like this:
| Engine | TG avg (t/s) | TTFT avg (ms) | Request latency avg (ms) |
|---|---|---|---|
ik_llama.cpp | 18.85 | 8,563 | 22,480 |
llama.cpp (mainline) | 16.03 | 12,526 | 28,872 |
That result also favored ik_llama.cpp across the board. There was also discussion that -muge can backfire on Kimi-K2.6, which reinforces the feeling that following the fork’s own knowledge is often the faster path than waiting for mainline to converge.
The Launch Command I Ended Up Keeping
podman run --rm \
--device nvidia.com/gpu=all \
-p 8000:8000 \
--cap-add=SYS_NICE \
-v /mnt/data/models/models--ubergarm--Kimi-K2.6-GGUF:/models:ro,Z \
registry.home.arpa/ik_llama.cpp:latest \
-m /models/snapshots/${REF}/IQ3_K/Kimi-K2.6-IQ3_K-00001-of-00012.gguf \
--ctx-size 131768 \
--parallel 1 \
--threads 15 \
--threads-batch 32 \
-b 8192 \
-ub 4096 \
-ngl 999 \
-mla 3 \
-ger \
--special \
-amb 512 \
--jinja \
--host 0.0.0.0 \
--port 8000 \
--warmup-batch \
--alias kimi-k2.6-IQ3_K \
-ot "blk\.(1|2)\.ffn.*=CUDA0" \
-ot "blk\.(59|60)\.ffn.*=CUDA1" \
-ot "exps=CPU" \
--temp 0.6 \
--chat-template-kwargs '{"thinking":false}'
This exposes Kimi-K2.6 as an OpenAI-compatible API while letting me call it directly from Zed and from my own agents.
Summary
| Item | Value |
|---|---|
| Model | Kimi-K2.6 (1T MoE, 384×8 active) |
| Quant | IQ3_K is the practical first choice |
| Engine | ik_llama.cpp |
| TG | 20.9 t/s (best 6-layer head/tail split) |
| PP cold | 223-377 t/s depending on -ub and placement |
| Real tasks | Long-form Django tenant-module generation works |
| Intended use | Orchestrator model |
| License | Modified MIT ($20M / 100M MAU trigger) |
The conclusion for me is that Kimi-K2.6 is not “unrealistic because it is 1T.” It is difficult mainly because CPU pinned memory, GPU VRAM, and model placement have to be balanced carefully. Once ik_llama.cpp MLA optimization and -ot placement are tuned properly, it becomes a local LLM with a TG range I can actually tolerate. That is enough to keep building data pipelines alongside Claude rather than treating the whole thing as a stunt.