All Rust, All Handmade -- 9 MCP Tools Powering the Homelab
A tour of the 9 custom MCP tools powering the homelab LLM agent stack. All Rust, all stdio JSON-RPC 2.0. Design philosophy and purpose for each tool.

About This Article
familiar’s orchestration currently runs on 9 MCP tools. All Rust, all stdio JSON-RPC 2.0. Built at a pace of roughly 1-2 per day, with plenty discarded along the way. This article covers the 9 that survived and are running in production.

The Full Picture
The homelab where all these tools run:
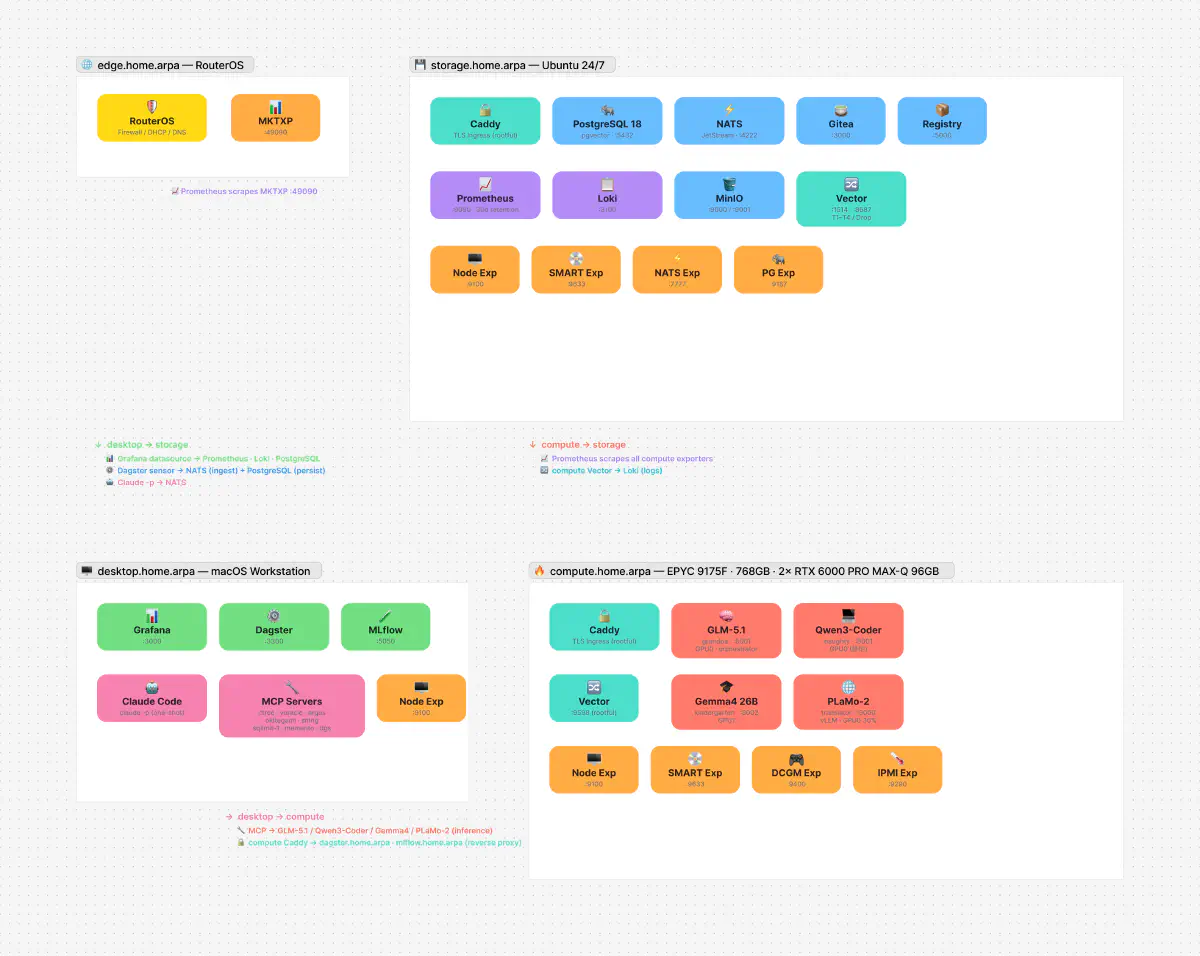
| MCP Server | Tools | Summary |
|---|---|---|
| voracle | 4 | Obsidian vault semantic search + web research |
| argus | 1 | Cross-repository code intelligence |
| ctree | 8 | Code tree structure analysis + checkpoints |
| dgs | 17 | secret |
| memento | 2 | secret |
| okitegami | 1 | Discord leave-a-letter |
| smng | 2 | Homelab secret management |
| sqlimit-1 | 5 | Read-only DB exploration |
resolve-inference (path resolution engine) is now integrated into familiar itself and no longer runs as a standalone MCP, but the design history is worth recording.
voracle – External Memory
Covered in detail in a separate article, so just the highlights. Semantic search + web research MCP for Obsidian vaults. Runs ONNX embedding + ColBERT reranking locally. The research command auto-accumulates web knowledge into the vault via the Brave Search API.
Tools: search, read, research, related
argus – Cross-Repository Code Intelligence
An MCP that indexes all repositories from Gitea and provides cross-repository symbol search. Extracts symbols with tree-sitter and reranks with ColBERT MaxSim.
CLI (index + embed) MCP Server (query)
| |
v v
[Gitea API: repos/search] [CWD auto-index on startup]
| |
v v
[git clone/fetch] [argus.see tool]
| |
v v
[tree-sitter: symbols] [adaptive lexical filter -> ColBERT rerank]
| |
v v
[ColBERT embed (batch)] [Gemini summarize]
| |
v v
[redb: symbols+embeddings] [hit tracking + NATS pulse]
Three-tier embedding:
- Batch:
argus embedpre-computes all symbol embeddings at index time - Hot-hit: symbols accessed 3+ times re-embed at query time to stay fresh
- On-demand: uncached symbols embed at query time and persist
Tools: see (specify expected symbols, modules, or specs for cross-repo search)
ctree – Code Tree Structure Analysis
An MCP for codebase symbol structure, dependency analysis, and revision management. Define scope with .ctree.toml, analyze structure with check, record work milestones with checkpoint.
Tools: check, checkpoint, get_affected, get_depends, get_symbol, get_text, get_revs, get_baseline
In familiar’s development workflow, calling checkpoint after every code change to leave a revision, then checking impact with get_affected before starting implementation has become standard practice. The agent’s work logs in Obsidian show ctree__check and ctree__get_symbol calls everywhere.
The call volume is high, but most replies are around 5 tokens – just symbol names and hashes, no actual code. The agent first grasps the structure via hashes, then injects only the code it actually needs into context on-demand with get_text. This keeps context window consumption minimal while maintaining visibility across the entire codebase’s dependency graph. Once this stabilized, Serena became unnecessary. I had been using Serena cooperatively before, but after setting up my own Gitea and distribution registry, argus handles IaC and understands my codebase’s architecture, design philosophy, and patterns well enough to code effectively.
dgs – 17 tools (non-public)
The largest tool count among the 9 MCPs. Design and implementation details are non-public.
memento – 2 tools (non-public)
An MCP related to AI agent management. Design and implementation details are non-public.
okitegami – Discord Leave-a-Letter
An MCP for LLM agents to post notifications to Discord at work milestones. Just one tool.
The design philosophy is “letter,” not “message.” I don’t want a conversation. Just leave a letter. I’ll leave one too if something comes up – and if there’s one waiting when you leave yours, read it. That’s the distance this was built for.
1. Leave a letter about current work results on Discord
2. While you're at it, check if past letters have replies
3. If no replies, do nothing
The trigger is “leave a new letter,” not “go check for replies.” No polling loops.
In practice: the agent creates threads in the #tegami channel during development and leaves progress notes. I glance at them occasionally, and if something comes to mind, I leave a reply. Replying a month later is fine. The next time the agent calls tegami, it picks up: “About that thing you implemented a month ago – ksh3 mentioned something about it, what should we do?” Or it just fixes it on its own.
It’s an asynchronous feedback loop, but it’s not chat. It moves on the timeline of letters. No urgency expected, no reply required for normal operation. This distance meshes long-running autonomous work with human life rhythms nicely.
Tools: tegami
smng – Secret Management
An MCP for managing homelab service credentials, endpoints, and connection details. Securely retrieves auth information for services within the *.home.arpa network.
Tools: list_services, get_secret
sqlimit-1 – Read-Only DB Exploration
A context-safe MCP targeting familiar’s main DB only, with query results limited to exactly one row. The core principle: don’t trust the LLM to write LIMIT 1. The tool wraps unconditionally:
SELECT * FROM (<user_sql>) AS _q LIMIT 1
Read-only is guaranteed at the connection level. Connects with a dedicated PostgreSQL user configured with default_transaction_read_only = on, so no filtering needed on the tool side. Non-SELECT statements are rejected outright.
Connection details could come from smng (secret management), but sqlimit-1’s job isn’t just DB access. It also handles schema versioning. dump_schema retrieves the schema, and if there are changes, it creates a schema version. Quickly understanding data structure with minimal context, leaving a version record on the side – that’s the specialized use case.
I prefer tools that do one thing well over tools that do everything. smng returns credentials. sqlimit-1 understands schemas. Clear responsibilities for each means they’re less likely to break when combined.
Tools: tables, describe, sample, query1, dump_schema
resolve-inference – ENOENT Path Resolution Engine (now integrated into familiar)
Built to solve the problem of LLMs guessing file paths and hitting ENOENT errors. Returns the correct path using a filesystem index with lexical scoring + ColBERT MaxSim.
The accuracy breakthrough wasn’t the model – it was query history. A ring buffer of the last 5 resolved paths, with a two-tier boost via directory affinity and package affinity:
Go monorepo (106 files, client.go exists in 4-11 locations):
With history: 85.0% (17/20)
Without history: 35.0% (7/20)
Delta: +50.0pp
I also built a framework to evaluate 3 ColBERT models as an ensemble, but all three scored identically (87.3%) while latency went up 3.7x. The accuracy bottleneck was in the lexical algorithm, not the model. Discarding the ensemble and focusing on query history correlation was the right call.
Retired Tools
Behind the 9 running tools, several have been retired. But “retired” is more accurate than “discarded” – most were integrated into current tools or had their functionality borrowed and reborn. resolve-inference being absorbed into familiar is one example; the ideas from the early shelpa (filesystem MCP) were distributed across ctree and dgs.
Above all, building them is just really fun. Writing an MCP server in Rust takes shape in a day, and the stdio JSON-RPC 2.0 protocol is simple enough that an idea turns into a working tool by the next day. Try it, discard if it’s mediocre, polish if it’s good. As long as this cycle keeps turning, the tools keep growing.
Shared Design Principles
What all tools have in common:
- Rust + stdio JSON-RPC 2.0: fast process startup, small memory footprint
- Single responsibility: one tool solves one problem. No feature creep
- Born from real agent work: built by working backwards from “this is where I got stuck”
- Graceful degradation: if one tool goes down, others keep running. familiar’s main flow doesn’t stop
41 tools across 9 processes, total memory usage in the tens of MB. Rust’s small binary size and runtime overhead pay off in architectures like this where many small processes run in parallel.